
Dengan lebih dari 1,5 miliar listing aktif, eBay adalah salah satu platform e-commerce terbesar di dunia. Membaca data yang tersedia untuk umum dari eBay menawarkan banyak keuntungan, seperti: B. memantau harga dan tren produk.
Di blog mendetail ini, Anda akan mempelajari cara melakukan scraping eBay dengan Python, tantangan yang dihadapi saat melakukan scraping eBay, dan cara menggunakan API Scrape-It.Cloud untuk mengekstrak data dari situs web mana pun dengan panggilan API sederhana tanpa memerlukan proxy.
Pengantar Pengikisan Data eBay
eBay adalah salah satu opsi paling populer untuk Ekstraksi data e-niaga, karena memberikan informasi yang kaya untuk analisis dan pengambilan keputusan. Model bisnis eBay berbeda dari platform ritel standar (seperti Amazon) melalui fitur lelangnya, di mana penjual menawarkan produk dengan harga rendah dan pelanggan mengajukan tawaran, sehingga terjadi perubahan harga yang dinamis.
Penjual dapat mengambil data berharga dari eBay untuk meningkatkan listing mereka dan mendapatkan keunggulan kompetitif dalam beberapa cara, seperti:
- Pemantauan harga: Harga berfluktuasi terus-menerus di e-commerce. Oleh karena itu penting untuk mengakses data pesaing di eBay untuk menawarkan harga yang paling kompetitif. Mengikis data ini bisa sangat berharga. Ini dapat menampilkan kisaran harga saat ini untuk produk target Anda sehingga Anda dapat membuat keputusan yang tepat mengenai harga Anda.
- Riset pasar: Data e-commerce memberikan wawasan berharga mengenai tren pasar, preferensi konsumen, dan pola pembelian. Dengan menganalisis perilaku belanja pelanggan, Anda dapat memprediksi pembelian mereka di masa depan dengan lebih baik dan mengidentifikasi tren pasar yang lebih luas. Selain itu, melacak lokasi pelanggan dapat mengungkapkan di mana produk Anda berfungsi dengan baik.
- Analisis kompetitif: Dengan mengumpulkan informasi tentang harga, diskon, dan promosi produk pesaing, Anda dapat membuat keputusan berdasarkan data tentang penawaran produk Anda. Pertimbangkan untuk menurunkan harga untuk menarik pelanggan atau penawar ketika ada banyak produk serupa yang tersedia.
- Analisis sentimen: Ulasan dan penilaian memberikan wawasan berharga tentang kepuasan pelanggan dan umpan balik produk. Scraping memungkinkan Anda memahami kepuasan pelanggan dan mengidentifikasi peluang untuk meningkatkan produk atau layanan Anda.
Membangun halaman eBay
Situs web eBay mencakup halaman produk dan hasil pencarian. Halaman produk eBay standar, seperti Beberapa situs web, seperti halaman Apple MacBook yang ditunjukkan di bawah ini, berisi informasi berguna yang dapat diambil. Informasi ini mencakup judul produk, deskripsi, gambar, rating, harga, status ketersediaan, ulasan pelanggan, biaya pengiriman dan tanggal pengiriman.
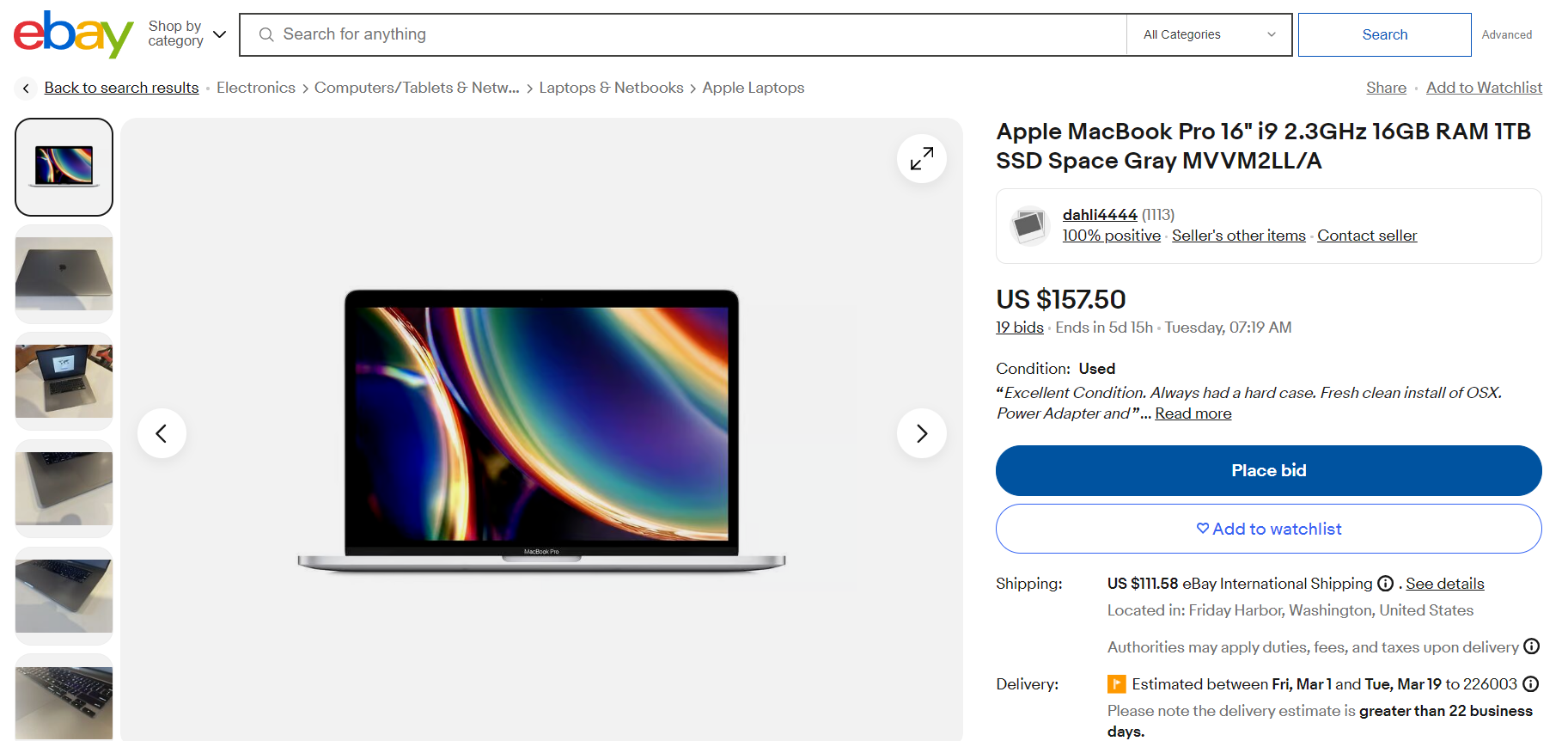
Jika Anda mencari kata kunci seperti “MacBook” di bilah pencarian, Anda akan diarahkan ke halaman hasil pencarian seperti di bawah ini. Anda dapat mengekstrak semua produk yang terdaftar di halaman ini, termasuk judul, gambar produk, peringkat, ulasan, dan lainnya.
Di sini Anda dapat melihat ribuan produk yang dapat diekstraksi, memberikan akses ke banyak informasi.
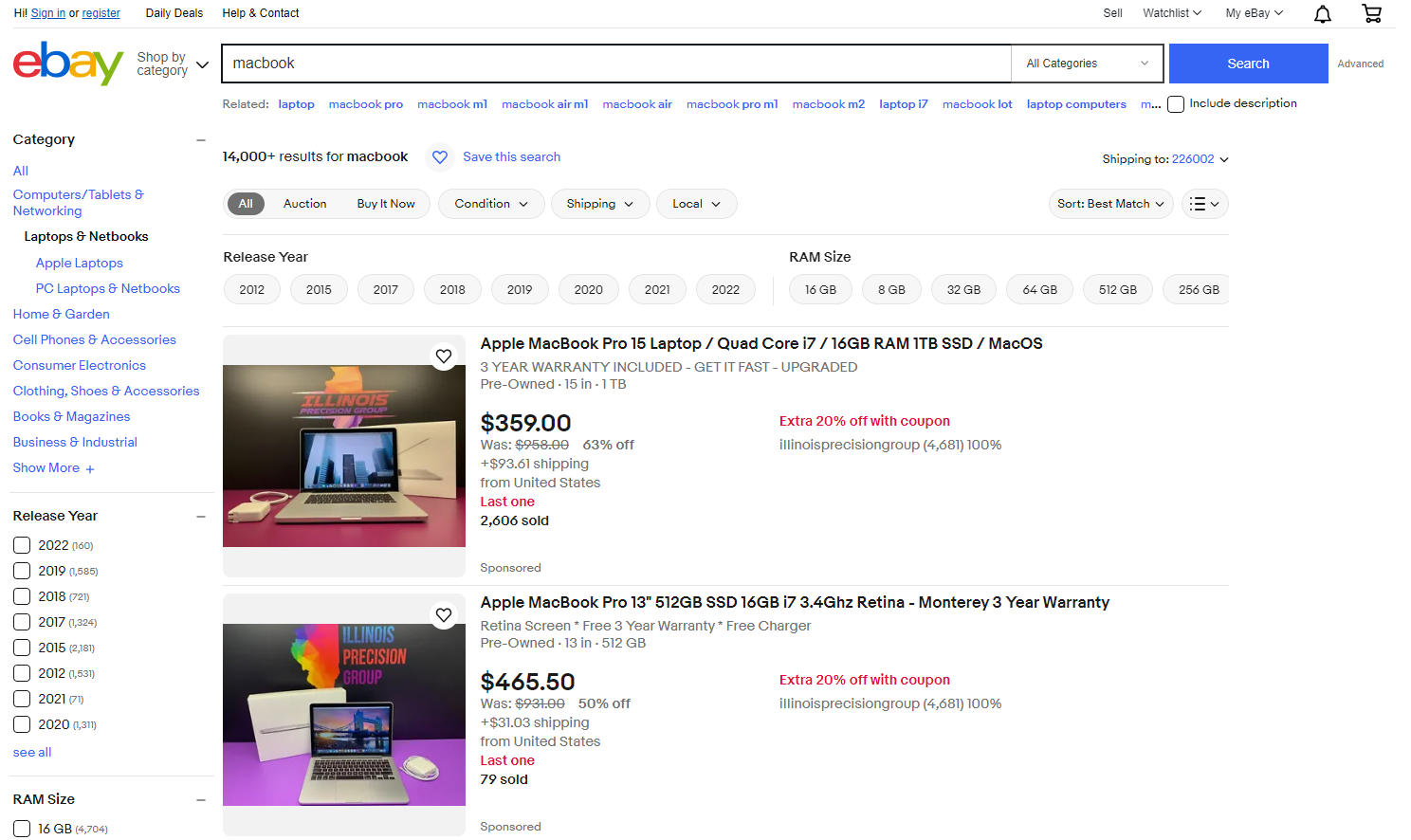
Sekarang setelah Anda memahami pentingnya data yang dapat kita peroleh dari eBay, mari selami panduan langkah demi langkah tentang cara mengekstrak data tertentu dari eBay menggunakan Python.
Menyiapkan lingkungan Python Anda untuk scraping
Untuk membuat lingkungan Python Anda Pengikisan web Untuk menyiapkannya, Anda harus memenuhi beberapa persyaratan sistem dan menginstal perpustakaan yang diperlukan.
persyaratan
Sebelum memulai, pastikan Anda memenuhi persyaratan berikut:
- Python diinstal: Unduh versi terbaru dari situs web resmi Python. Untuk blog ini kami menggunakan Python 3.9.12.
- Editor Kode: Pilih editor kode, mis. B. Kode Visual Studio, PyCharm atau Notebook Jupyter.
Selanjutnya, buat proyek Python bernama “ebay-scraper” dengan perintah berikut:
mkdir ebay-scraper
cd ebay-scraperBuka proyek ini di editor kode favorit Anda dan buat file Python baru (scraper.py).
Instal perpustakaan yang diperlukan
Untuk melakukan web scraping dengan Python, Anda perlu menginstal beberapa perpustakaan penting: Requests, BeautifulSoup, dan Pandas.
- Panda untuk membuat DataFrames dari data yang diekstraksi dan secara efisien menulis DataFrame ke file CSV. Secara resmi mendukung Python 3.9, 3.10, 3.11 dan 3.12.
- Permintaan mengirimkan permintaan HTTP dan mengambil konten HTML dari halaman web. Ini secara resmi mendukung Python 3.7+.
- BeautifulSoup mengekstrak data dari konten HTML mentah menggunakan tag, atribut, kelas, dan pemilih CSS.
pip install beautifulsoup4 requests pandasMengikis halaman produk eBay
Menggores halaman melibatkan pemahaman strukturnya, mengunduh konten HTML mentah, menganalisis konten HTML untuk mengekstrak detail produk, dan kemudian menyimpan data untuk analisis lebih lanjut.
Analisis halaman produk eBay
Halaman produk berisi berbagai elemen data yang dapat kita ekstrak. Kami akan menghapus tujuh atribut utama dari halaman tersebut, termasuk:
- Gambar produk
- Nama Produk
- Harga
- Harga asli
- Diskon
- Peringkat Umpan Balik Penjual
- Pengiriman
Di eBay, URL halaman produk mengikuti format di bawah ini. Ini adalah URL dinamis yang berubah berdasarkan ID artikel, yang merupakan pengidentifikasi unik untuk setiap artikel.
<https://www.ebay.com/itm/><ITM_ID>Mari jelajahi situs https://www.ebay.com/itm/404316395828. ID barangnya adalah 404316395828.
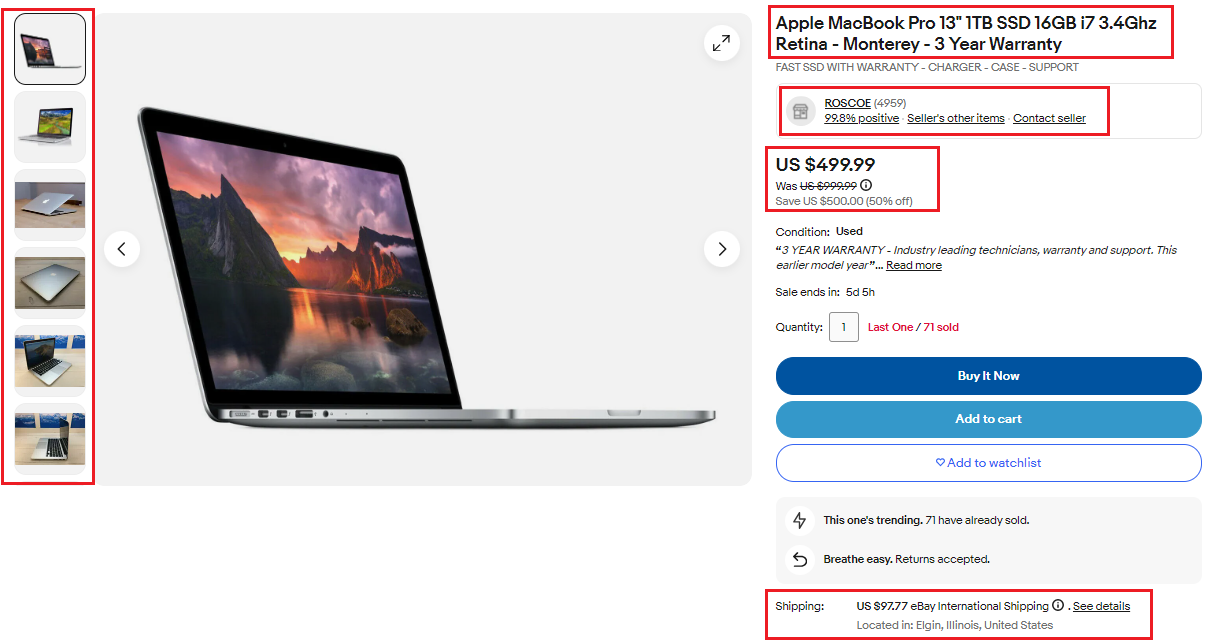
Ambil halaman HTML
Untuk mendapatkan konten HTML halaman produk eBay, identifikasi terlebih dahulu nomor ID uniknya. Lalu gunakan itu requests.get() Berfungsi dan mengembalikan ID sebagai argumen. Fungsi ini mengirimkan permintaan HTTP GET ke eBay yang meminta halaman produk tertentu.
Jika berhasil, server mengirimkan kembali respons dengan semua konten HTML halaman, disimpan dalam variabel untuk Anda akses. Namun, jika terjadi kesalahan selama proses ini, seperti ID tidak valid atau masalah jaringan, maka raise_for_status() Fungsi ini memberikan pengecualian untuk memperingatkan Anda.
url = f"<https://www.ebay.com/itm/{item_id}>"
response = requests.get(url)
response.raise_for_status()Mengurai halaman HTML
Buat objek BeautifulSoup dengan meneruskan yang berikut ini response.text dan nama parser “html.parser”. BeautifulSoup() Konstruktor. Proses penguraian ini memecah kode HTML menjadi bagian-bagian komponennya, termasuk tag dan atribut, dan menciptakan struktur mirip pohon yang dikenal sebagai Document Object Model (DOM).
Setelah DOM disiapkan, Anda dapat menggunakan berbagai metode seperti find(), find_all(), select_one() dan select() untuk mengekstrak elemen secara selektif. find() Dan find_all() digunakan untuk menavigasi pohon analisis select_one() Dan select() digunakan untuk menemukan elemen menggunakan pemilih CSS.
soup = BeautifulSoup(response.text, "html.parser")Kami mengekstrak tujuh atribut utama dari produk: gambar, judul, harga saat ini, harga asli, diskon, peringkat penjual, dan biaya pengiriman.
Judul disimpan di h1 hari bersama kelas x-item-title__mainTitle. Dengan ini h1 Hari, ada satu span Tag dengan dua nama kelas. Kami akan menggunakannya .ux-textspans--BOLD Nama kelas untuk mengekstrak teks judul. Oleh karena itu pemilih terakhir adalah mengekstrak judul .x-item-title__mainTitle .ux-textspans--BOLD.
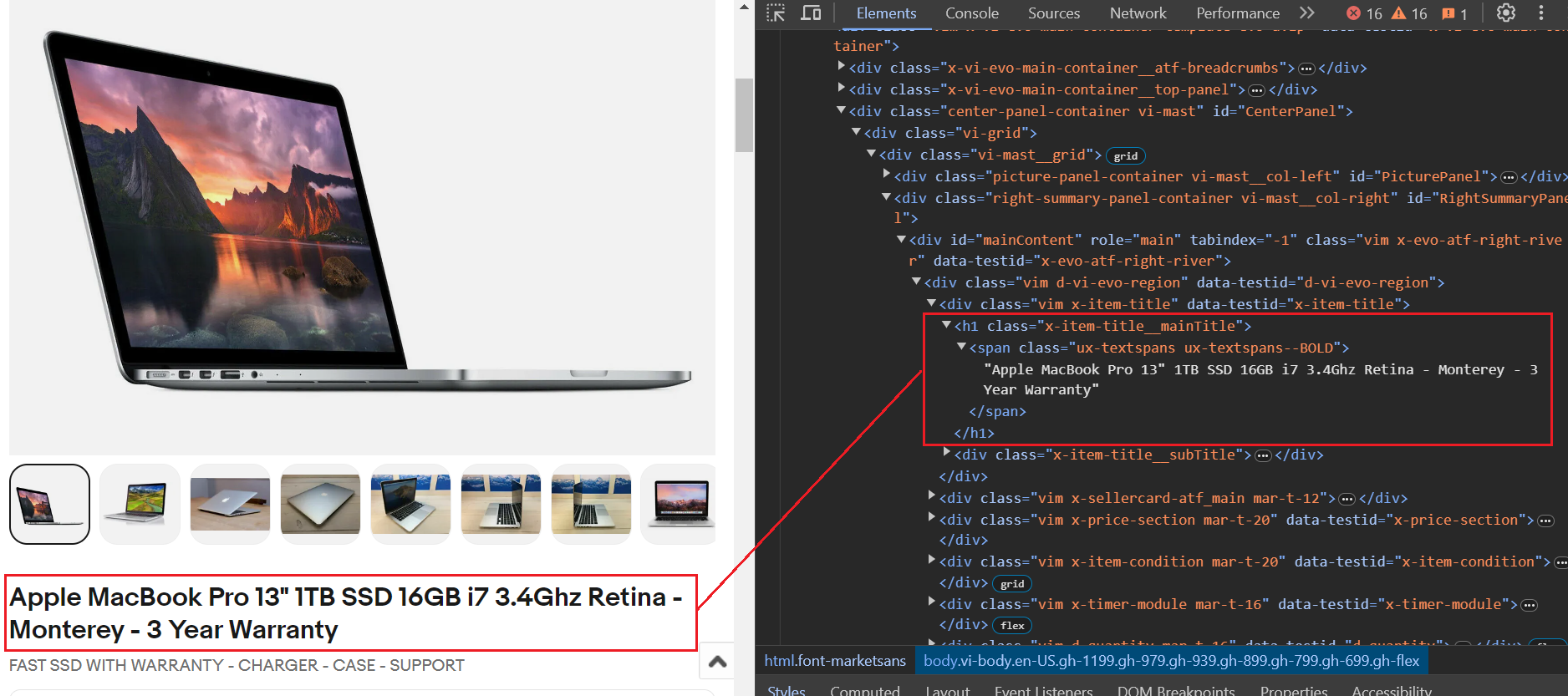
Berikut ini contoh cuplikan kode. Kami menggunakan itu select_one Metode yang mengembalikan elemen pertama yang cocok dengan pemilih CSS yang ditentukan. Kita ekstrak dulu judulnya, lalu periksa apakah kosong dan terakhir simpan di item_data Kamus tempat semua atribut utama disimpan.
item_title_element = soup.select_one(".x-item-title__mainTitle .ux-textspans--BOLD")
item_title = item_title_element.text if item_title_element else "Not available"
item_data("Title") = item_titleHarga berada dalam kisaran a div Tandai dengan nama kelas x-price-primary. Di sana div hari, a span Tandai dengan nama kelas ux-textspans termasuk harganya. Menargetkan elemen ini secara akurat menggunakan CSS adalah pilihan yang tepat .x-price-primary .ux-textspans.
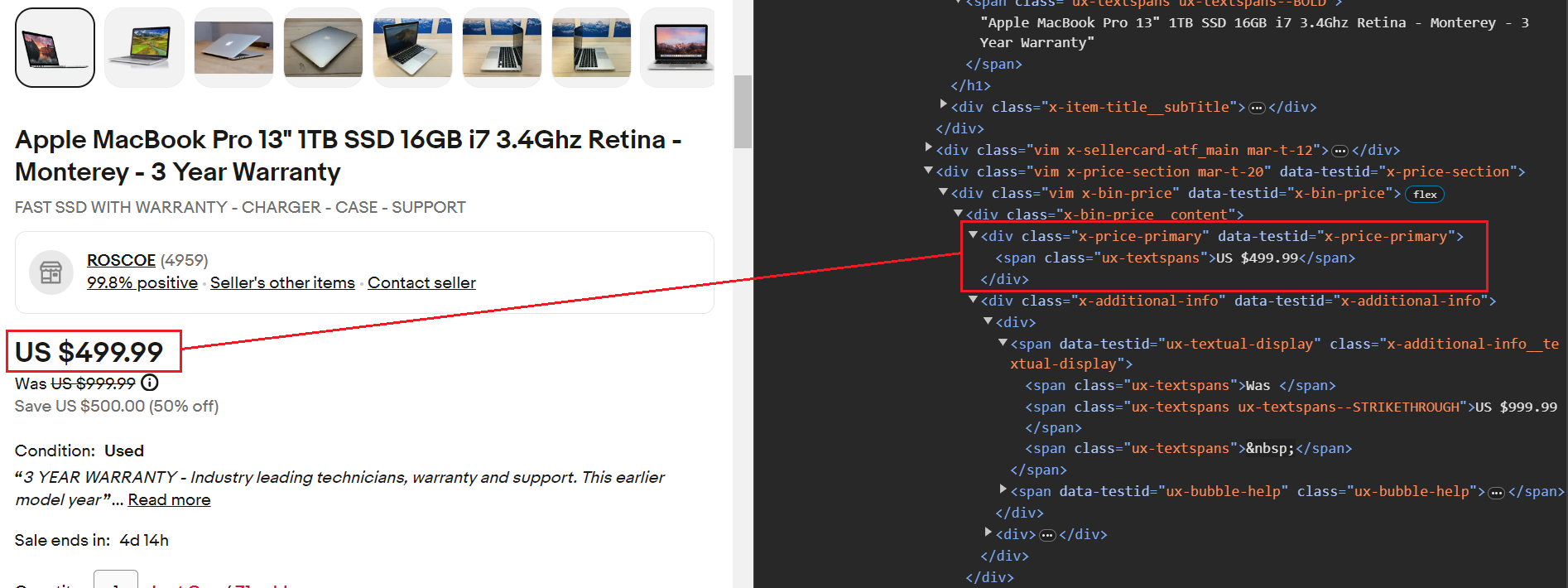
Berikut cuplikan kodenya. Operasi pengikisan sama seperti yang kita lihat di judul.
current_price_element = soup.select_one(".x-price-primary .ux-textspans")
current_price = current_price_element.text if current_price_element else "Not available"
item_data("Current Price") = current_priceNilai yang dicoret menunjukkan harga sebenarnya. Nilai ini dapat dengan mudah diekstraksi menggunakan span Tandai kelas ux-textspans--STRIKETHROUGH.
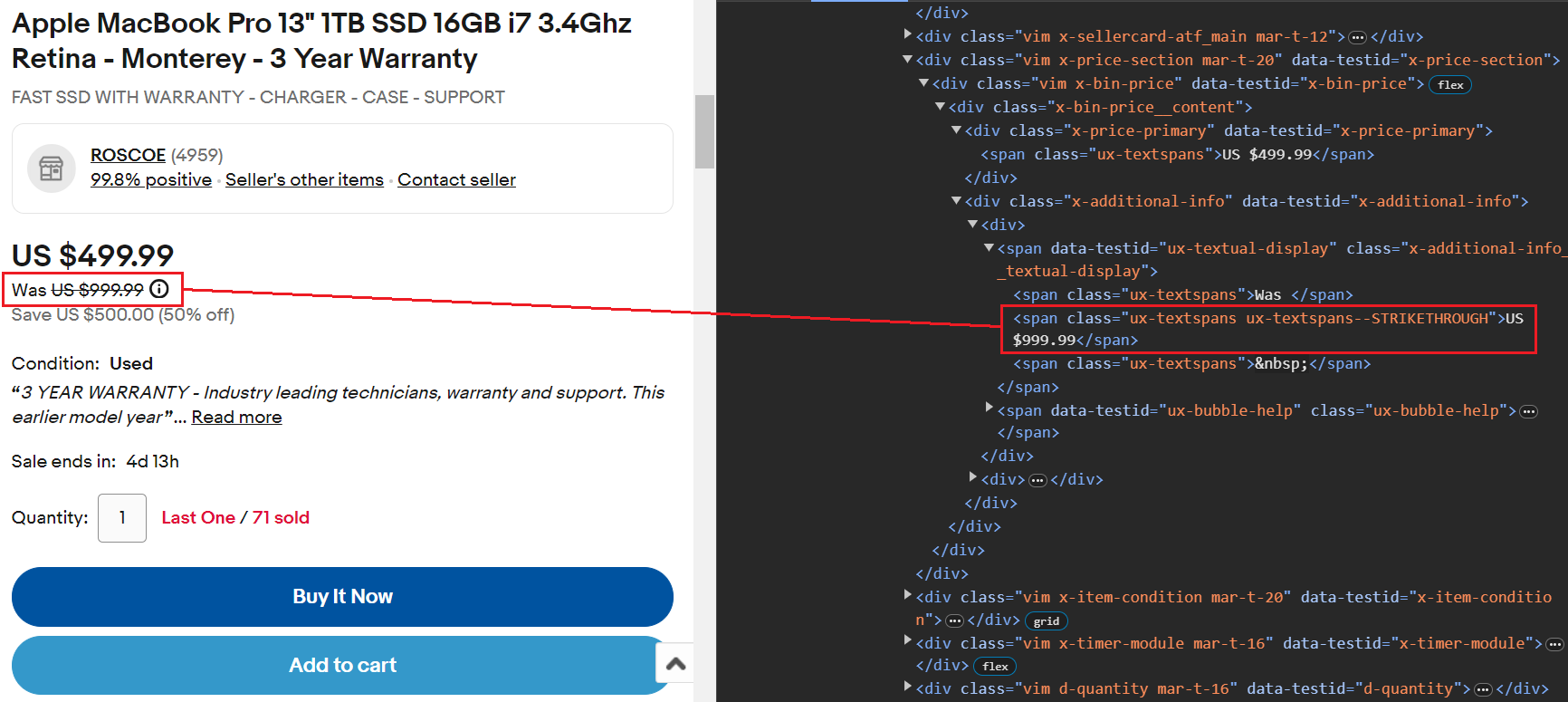
Berikut cuplikan kodenya:
original_price_element = soup.select_one(".ux-textspans--STRIKETHROUGH")
original_price = (
original_price_element.text if original_price_element else "Not available")
item_data("Original Price") = original_priceDiskon disimpan dalam a span hari bersama kelas ux-textspans--EMPHASIS. Itu span Tag ini bersarang di dalam elemen induk yang berisi kelas x-additional-info__textual-display. Oleh karena itu, pemilih yang tepat untuk menargetkan elemen ini adalah .x-additional-info__textual-display .ux-textspans--EMPHASIS.
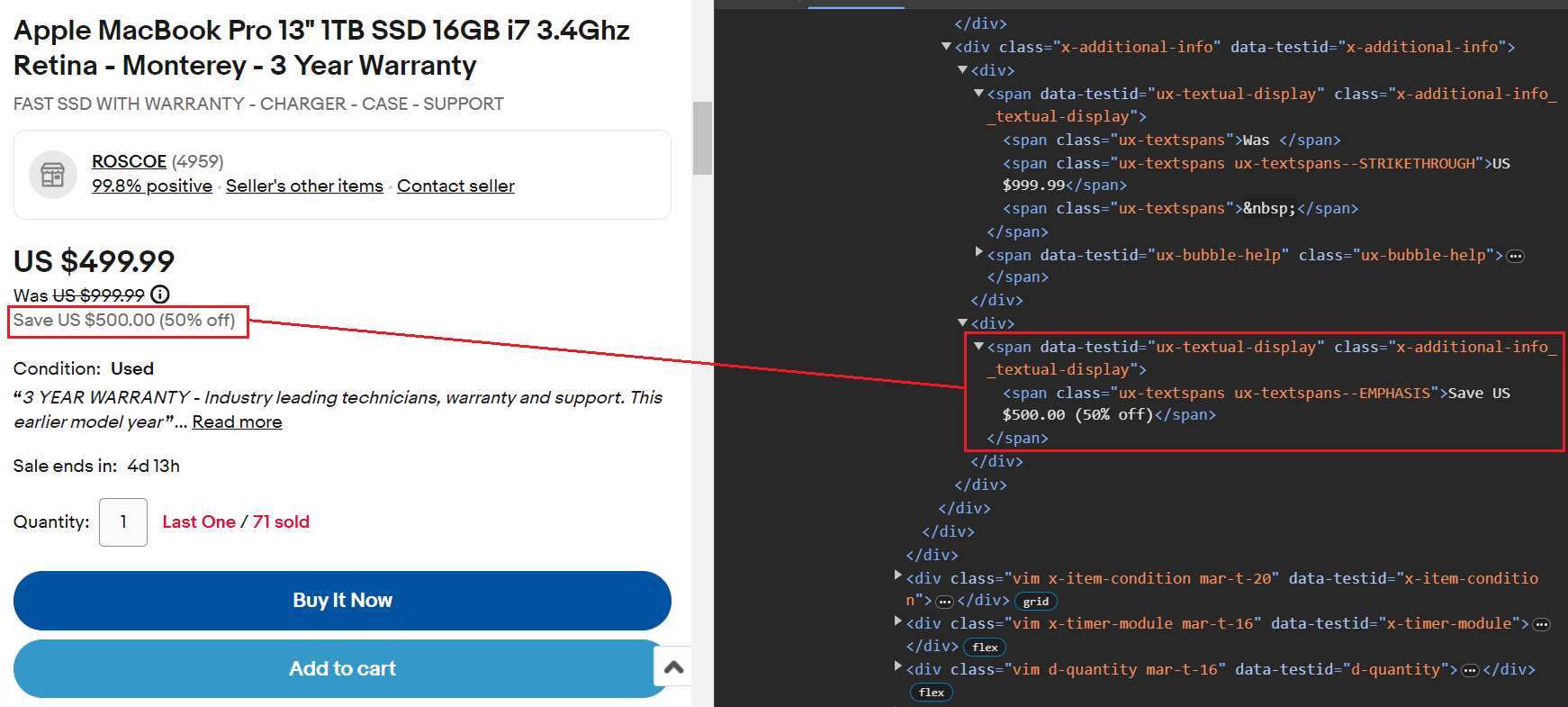
Berikut cuplikan kodenya:
savings_element = soup.select_one(
".x-additional-info__textual-display .ux-textspans--EMPHASIS")
savings = savings_element.text if savings_element else "Not available"
item_data("Savings") = savingsHarga pengiriman berada dalam kisaran a span hari bersama kelas ux-textspans--BOLD. Terutama ini span Tag bersarang di tempat yang berbeda div Tag, tapi kami akan fokus pada elemen induk div hari yang dimiliki kelas tersebut ux-labels-values--shippingseperti ini div Tag tampaknya memiliki nama kelas yang unik. Proses pengikisan mencakup dua langkah berikut:
- Menggunakan
soup.find('div', class_='ux-labels-values--shipping')untuk menemukan itudivTag dengan nama kelas yang ditentukan. - Menerapkan
.find('span', class_='ux-textspans--BOLD').textuntuk menemukan dan mengekstrak konten teks dari hit pertamaspanElemen dengan kelasux-textspans--BOLDdalam yang teridentifikasidivLabel.
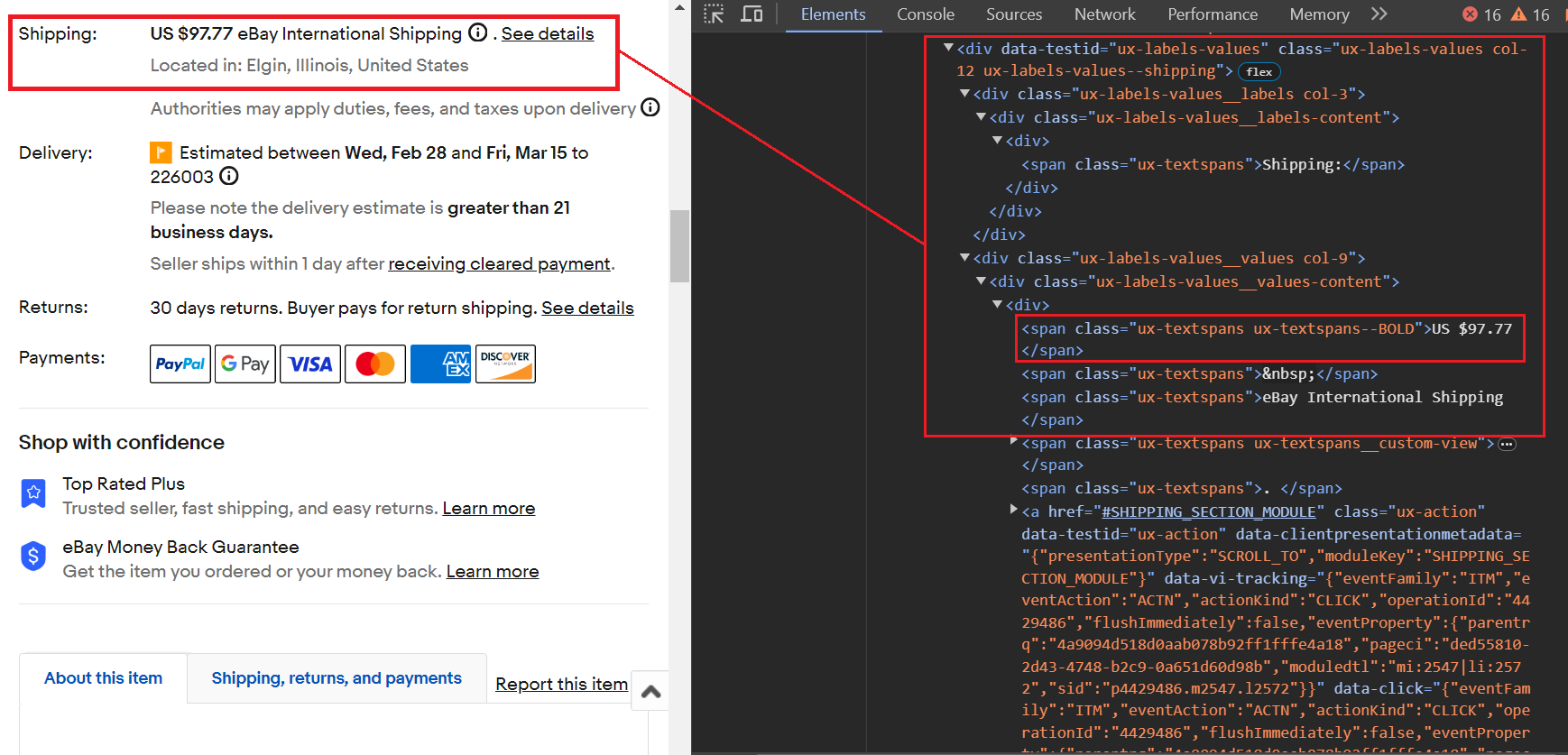
Berikut cuplikan kodenya:
shipping_parent_element = soup.find("div", class_="ux-labels-values--shipping")
shipping_info = (
"Free Shipping"
if not shipping_parent_element
else shipping_parent_element.find("span", class_="ux-textspans--BOLD").text
)
item_data("Shipping Price") = shipping_infoPeringkat umpan balik penjual ada di dalam <a> Tag bersarang di dalam satu <li> hari dengan itu data-testid Atribut disetel ke x-sellercard-atf__data-item. Itu <li> Tag pada gilirannya terkandung dalam satu <ul> hari yang dimiliki kelas tersebut .x-sellercard-atf__data-item-wrapper.
Demikianlah pemilih yang menargetkan elemen ini .x-sellercard-atf__data-item-wrapper li(data-testid="x-sellercard-atf__data-item") a.
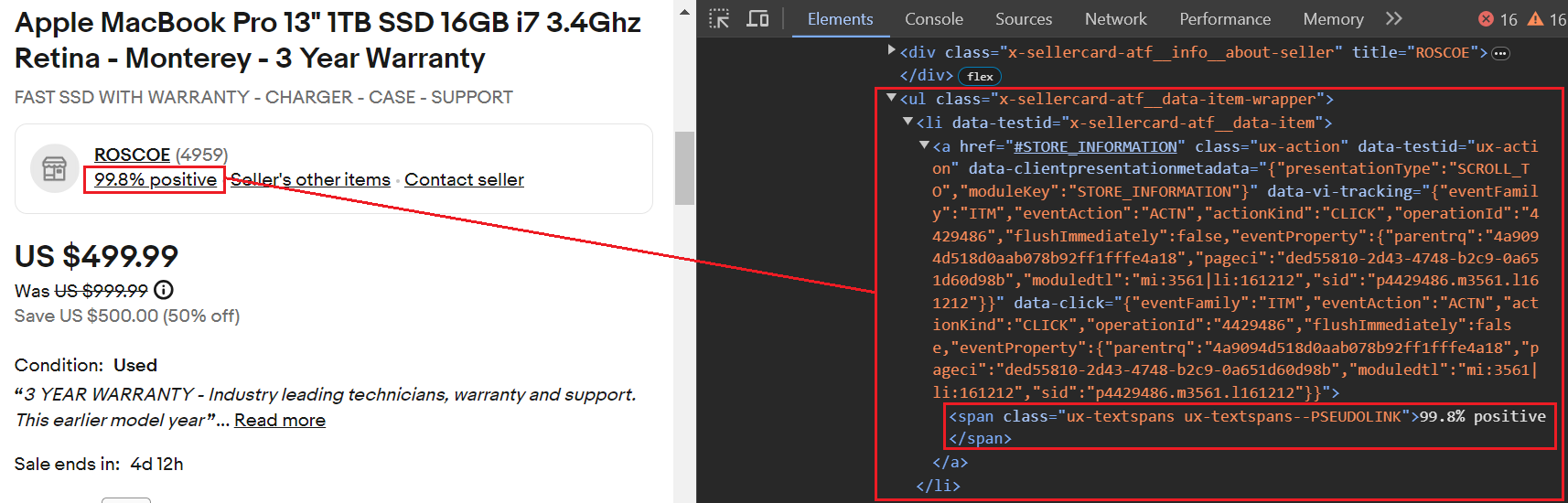
Berikut cuplikan kodenya:
seller_feedback_element = soup.select_one(
'.x-sellercard-atf__data-item-wrapper li(data-testid="x-sellercard-atf__data-item") a'
)
seller_feedback = (
seller_feedback_element.text if seller_feedback_element else "Not available"
)
item_data("Seller Feedback") = seller_feedbackSemua gambar berada dalam individu button Tag yang berbagi nama kelas yang sama ux-image-grid-item. Wadah induk untuk ini button Tag adalah a div hari bersama kelas ux-image-grid-container.
Untuk mengakses gambar, ikuti langkah-langkah berikut:
- Temukan tag div menggunakan
findMetode. - Menerapkan
selectMetode menggunakan pemilih CSS.ux-image-grid-item imguntuk mendapatkan daftar semua elemen gambar yang cocok.
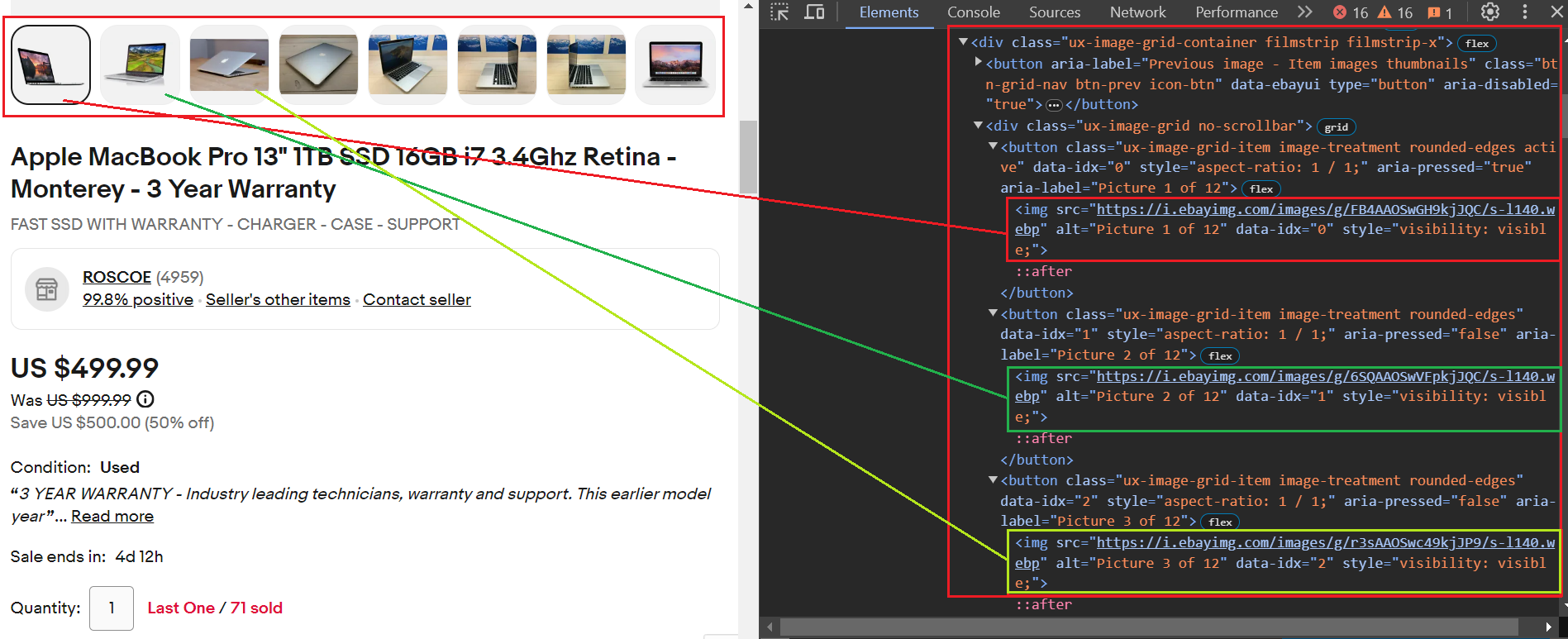
Berikut cuplikan kodenya. Setelah mengekstrak semuanya <img> Tag, kami memeriksa apakah src Atributnya ada di tag ini. Hal ini karena src Atribut menentukan URL gambar.
image_grid_container = soup.find("div", class_="ux-image-grid-container")
image_links = ()
if image_grid_container:
img_elements = image_grid_container.select(".ux-image-grid-item img")
image_links = (img("src") for img in img_elements if "src" in img.attrs)
item_data("Images") = image_linksEkspor data ke JSON
Anda telah berhasil mengekstrak dan menyimpan semua data item_data Kamus. Untuk menyimpan data ke file JSON, impor json modul dan gunakan itu dump Metode.
with open(filename, "w") as file:
json.dump(item_data, file, indent=4)Ini file JSONnya:
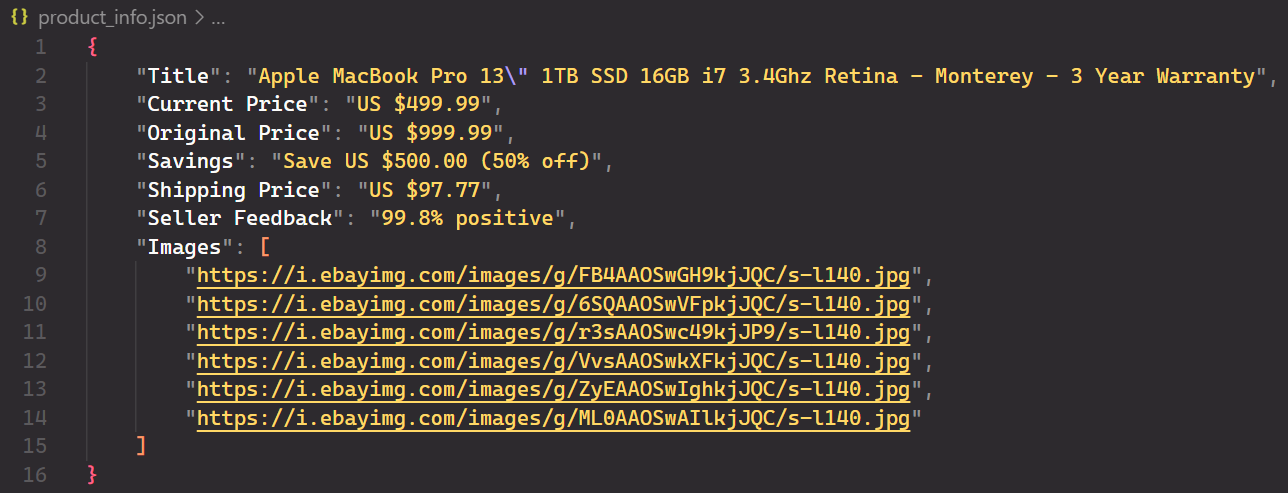
Kode lengkap
Di bawah ini adalah kode lengkap untuk ekstraksi data produk. Yang Anda butuhkan hanyalah ID item.
import requests
from bs4 import BeautifulSoup
import json
def fetch_ebay_item_info(item_id):
url = f"<https://www.ebay.com/itm/{item_id}>"
try:
response = requests.get(url)
response.raise_for_status() # Raise an exception for bad requests
except requests.exceptions.RequestException as e:
print(f"Error: Unable to fetch data from eBay ({e})")
return None
soup = BeautifulSoup(response.text, "html.parser")
item_data = {}
try:
current_price_element = soup.select_one(
".x-price-primary .ux-textspans")
current_price = (
current_price_element.text if current_price_element else "Not available"
)
original_price_element = soup.select_one(
".ux-textspans--STRIKETHROUGH")
original_price = (
original_price_element.text if original_price_element else "Not available"
)
savings_element = soup.select_one(
".x-additional-info__textual-display .ux-textspans--EMPHASIS"
)
savings = savings_element.text if savings_element else "Not available"
shipping_parent_element = soup.find(
"div", class_="ux-labels-values--shipping")
shipping_info = (
"Free Shipping"
if not shipping_parent_element
else shipping_parent_element.find("span", class_="ux-textspans--BOLD").text
)
seller_feedback_element = soup.select_one(
'.x-sellercard-atf__data-item-wrapper li(data-testid="x-sellercard-atf__data-item") a'
)
seller_feedback = (
seller_feedback_element.text if seller_feedback_element else "Not available"
)
item_title_element = soup.select_one(
".x-item-title__mainTitle .ux-textspans--BOLD"
)
item_title = item_title_element.text if item_title_element else "Not available"
image_grid_container = soup.find(
"div", class_="ux-image-grid-container")
image_links = ()
if image_grid_container:
img_elements = image_grid_container.select(
".ux-image-grid-item img")
image_links = (img("src")
for img in img_elements if "src" in img.attrs)
item_data("Title") = item_title
item_data("Current Price") = current_price
item_data("Original Price") = original_price
item_data("Savings") = savings
item_data("Shipping Price") = shipping_info
item_data("Seller Feedback") = seller_feedback
item_data("Images") = image_links
return item_data
except Exception as e:
print(f"Error: Unable to parse eBay data ({e})")
return None
def save_to_json(item_data, filename="product_info.json"):
if item_data:
with open(filename, "w") as file:
json.dump(item_data, file, indent=4)
print(f"Success: eBay item information saved to {filename}")
def main():
item_id = input("Enter the eBay item ID: ")
item_info = fetch_ebay_item_info(item_id)
if item_info:
save_to_json(item_info)
if __name__ == "__main__":
main()Pengikisan pencarian eBay
Saat Anda mencari kata kunci, eBay secara otomatis akan mengarahkan Anda ke URL tertentu yang berisi hasil pencarian Anda. Misalnya, menelusuri “klaster kubernetes” akan membawa Anda ke URL yang mirip dengan https://www.ebay.com/sch/i.html?_nkw=kubernetes+cluster&_sacat=0.
URL ini menggunakan beberapa parameter untuk menentukan permintaan pencarian Anda. Berikut beberapa di antaranya:
_nkw: Istilah pencarian itu sendiri._sacat: Pembatasan kategori apa pun yang Anda terapkan._sop: Jenis penyortiran yang dipilih, mis. Misalnya, “Pencocokan Terbaik” atau “Terdaftar Baru”._pgn: Nomor halaman hasil pencarian saat ini._ipg: Jumlah entri yang ditampilkan per halaman (default: 60).
Anda akan menerima beberapa hasil untuk istilah pencarian. Agar berhasil mengekstrak data, Anda harus menelusuri semua entri pada halaman dan membuat nomor halaman hingga Anda mencapai halaman terakhir.
Penawaran eBay
Seperti yang Anda lihat pada gambar di bawah, kami mencari kata kunci dan mendapatkan daftar hasil. Setiap hasil terkandung dalam file terpisah li Label. Untuk mengekstrak informasi yang kita inginkan, kita harus melalui semua ini li Tandai dan ekstrak data tertentu dengan hati-hati. Kami mengekstrak judul, harga, biaya pengiriman penjual, URL produk, dan tanggal pencatatan.
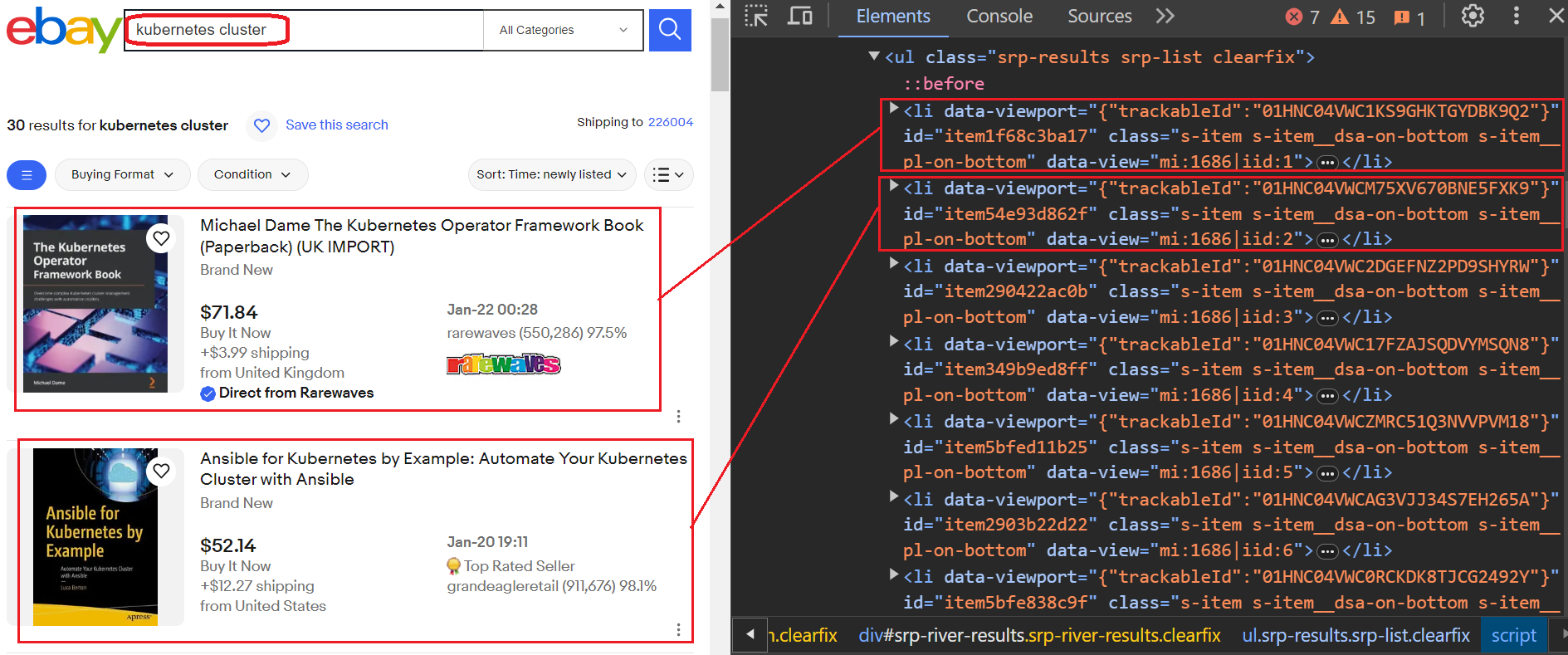
Mari kita lihat bagaimana kita dapat menghapus data produk dari daftar ini. Secara khusus, setiap produk dikemas dalam kemasan li hari bersama kelas s-item. Kita bisa menggunakannya find_all Berfungsi untuk menemukan semua item ini. Fungsi ini menemukan semua elemen yang cocok di pohon parsing dan mengembalikan daftar. Anda kemudian dapat mengulangi daftar dan meneruskan setiap elemen satu per satu ke dalamnya extract_product_details Berfungsi untuk mengekstrak informasinya.
for item in soup.find_all("li", class_="s-item"):
extract_product_details(item)Sekarang Anda dapat mengekstrak semua titik data dengan meneruskan tag dengan nama kelas. Judulnya ada di div Hari yang memiliki kelas s-item__title. Begitu pula dengan harganya span Hari dengan kelas s-item__pricedan biaya pengiriman berada di dalam span Hari dengan kelas s-item__logisticsCost.
def extract_product_details(item):
title = item.find("div", class_="s-item__title")
price = item.find("span", class_="s-item__price")
seller = item.find("span", class_="s-item__seller-info-text")
shipping = item.find("span", class_="s-item__logisticsCost")
url = item.find("a", class_="s-item__link")
list_date = item.find("span", class_="s-item__listingDate")Berurusan dengan paginasi
Untuk satu halaman, pengikisan akan mudah dilakukan. Namun, eBay menggunakan sistem pagination bernomor (nomor halaman berurutan di URL). Anda dapat dengan mudah melihat perubahan URL dengan mengklik Berikutnya: itu _pgn Parameternya hanya bertambah satu.

Untuk menangani penomoran halaman, kita dapat menerapkan perulangan while yang berlanjut hingga tidak ada halaman berikutnya yang tersedia. Setelah mengikis setiap halaman, Anda perlu mengekstrak URL halaman berikutnya. Di bawah ini adalah cuplikan kode kasar:
def extract_next_url(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
next_page_button = soup.select_one("a.pagination__next")
next_page_url = next_page_button("href") if next_page_button else None
while current_url:
products_on_page, next_page_url = extract_next_url(current_url)
current_url = next_page_urlCuplikan kode di atas menggunakan pemilih CSS untuk menemukan elemen jangkar pertama dengan kelas tersebut pagination__next, yang biasanya mewakili tombol “Halaman Berikutnya”. Jika tombol seperti itu ditemukan, nilainya diekstraksi href Atribut.
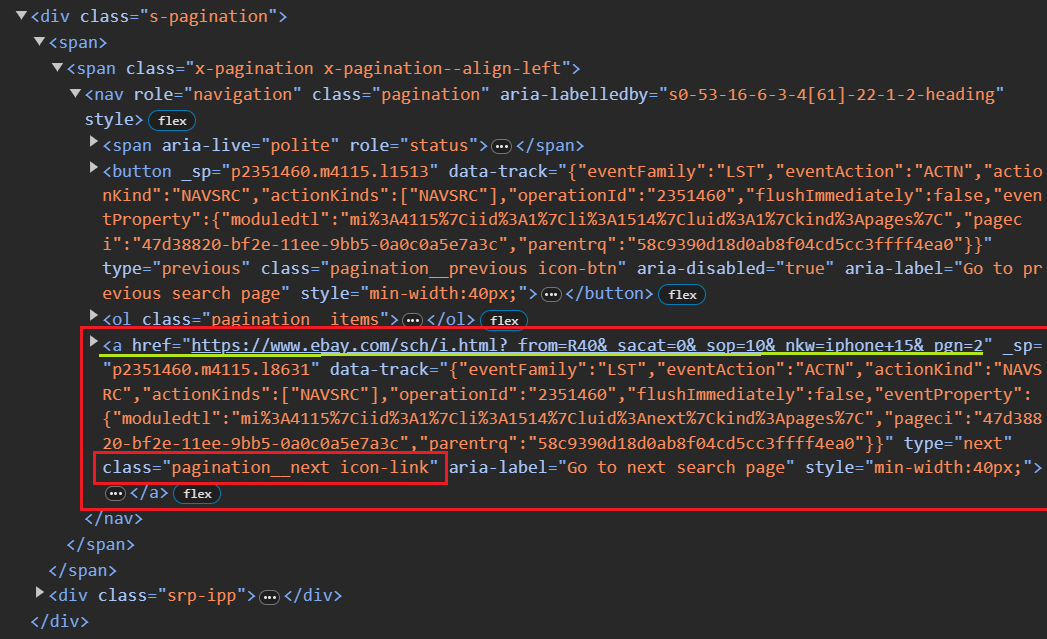
Kita berhasil! Semuanya disimpan dalam file CSV.
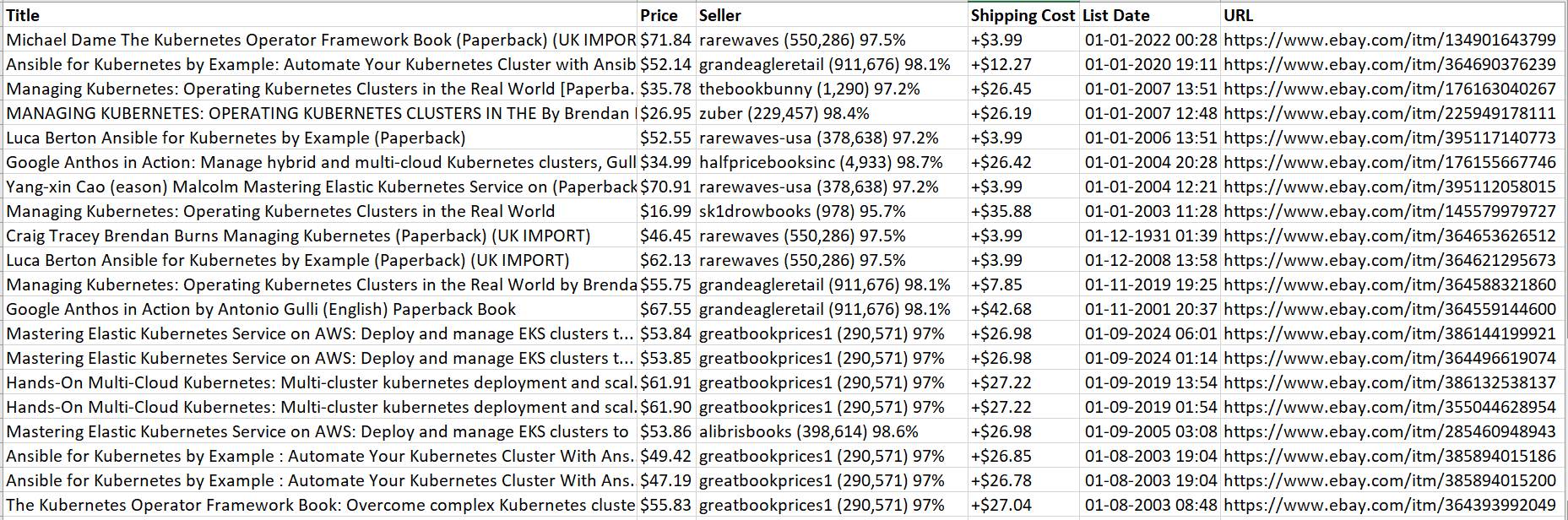
Kode lengkap
Skrip ini pada dasarnya memungkinkan pengguna untuk memasukkan permintaan pencarian dan preferensi penyortiran (misalnya “best_match,” “end_soonest,” atau “new_listed”), mencari hasil pencarian eBay, mengekstrak detail produk, dan menyimpannya ke file CSV .
import requests
from bs4 import BeautifulSoup
import pandas as pd
from urllib.parse import urlencode
def extract_product_details(item):
title = item.find("div", class_="s-item__title")
price = item.find("span", class_="s-item__price")
seller = item.find("span", class_="s-item__seller-info-text")
shipping = item.find("span", class_="s-item__logisticsCost")
url = item.find("a", class_="s-item__link")
list_date = item.find("span", class_="s-item__listingDate")
return {
"Title": title.text.strip() if title else "Not available",
"Price": price.text.strip() if price else "Not available",
"Seller": seller.text.strip() if seller else "Not available",
"Shipping Cost": (
shipping.text.strip().replace("shipping", "").strip()
if shipping
else "Not available"
),
"List Date": (
list_date.text.strip() if list_date else "Date not found"
),
"URL": url("href").split("?")(0) if url else "Not available",
}
def extract_page_data(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
products = (
extract_product_details(item) for item in soup.find_all("li", class_="s-item")
)
next_page_button = soup.select_one("a.pagination__next")
next_page_url = next_page_button("href") if next_page_button else None
return products, next_page_url
def write_to_csv(products, filename="product_info.csv"):
df = pd.DataFrame(products)
mode = "w" if not pd.io.common.file_exists(filename) else "a"
df.to_csv(filename, index=False, header=(mode == "w"), mode=mode)
print(f"Data has been written to {filename}")
def make_request(query, sort, items_per_page=60):
base_url = "<https://www.ebay.com/sch/i.html?">
query_params = {
"_nkw": query,
"_ipg": items_per_page,
"_sop": SORTING_MAP(sort),
}
return base_url + urlencode(query_params)
def scrape_ebay(search_query, sort):
current_url = make_request(search_query, sort, 240)
total_products = ()
while current_url:
products_on_page, next_page_url = extract_page_data(current_url)
total_products.extend(products_on_page)
current_url = next_page_url
total_products = (
product for product in total_products if "Shop on eBay" not in product("Title")
)
write_to_csv(total_products)
SORTING_MAP = {
"best_match": 12,
"ending_soonest": 1,
"newly_listed": 10,
}
user_search_query = input("Enter eBay search query: ")
sort = input("Choose one ('best_match', 'ending_soonest', 'newly_listed'): ")
scrape_ebay(user_search_query, sort)Tantangan menghapus eBay
Untuk membuat perayapan eBay lebih efisien dan efektif, Anda juga harus ingat bahwa eBay dapat mendeteksi bot, memblokir alamat IP, dan pada akhirnya mengganggu aliran data. Oleh karena itu, saat memperluas perayapan eBay, Anda harus siap menghadapi tantangan berikut:
- CAPTCHA: Membuat ekstraksi data yang lancar menjadi jauh lebih sulit.
- Pemblokiran IP: eBay secara aktif memblokir alamat IP yang mencurigakan.
- Batas waktu sesi: Pengikisan berkelanjutan memerlukan pemeliharaan sesi aktif untuk menghindari kesenjangan data.
- Paginasi: Navigasi yang efisien melalui konten yang diberi halaman dapat meningkatkan kecepatan pengikisan secara signifikan.
- Pertimbangan Hukum dan Etis: Penting untuk menghormati persyaratan layanan dan privasi pengguna eBay.
Mengikis eBay dengan API Scrape-It.Cloud
Mari kita lihat betapa mudahnya web scraping API mengekstrak informasi produk dari situs web e-niaga hanya dengan panggilan API sederhana tanpa memerlukan proxy.
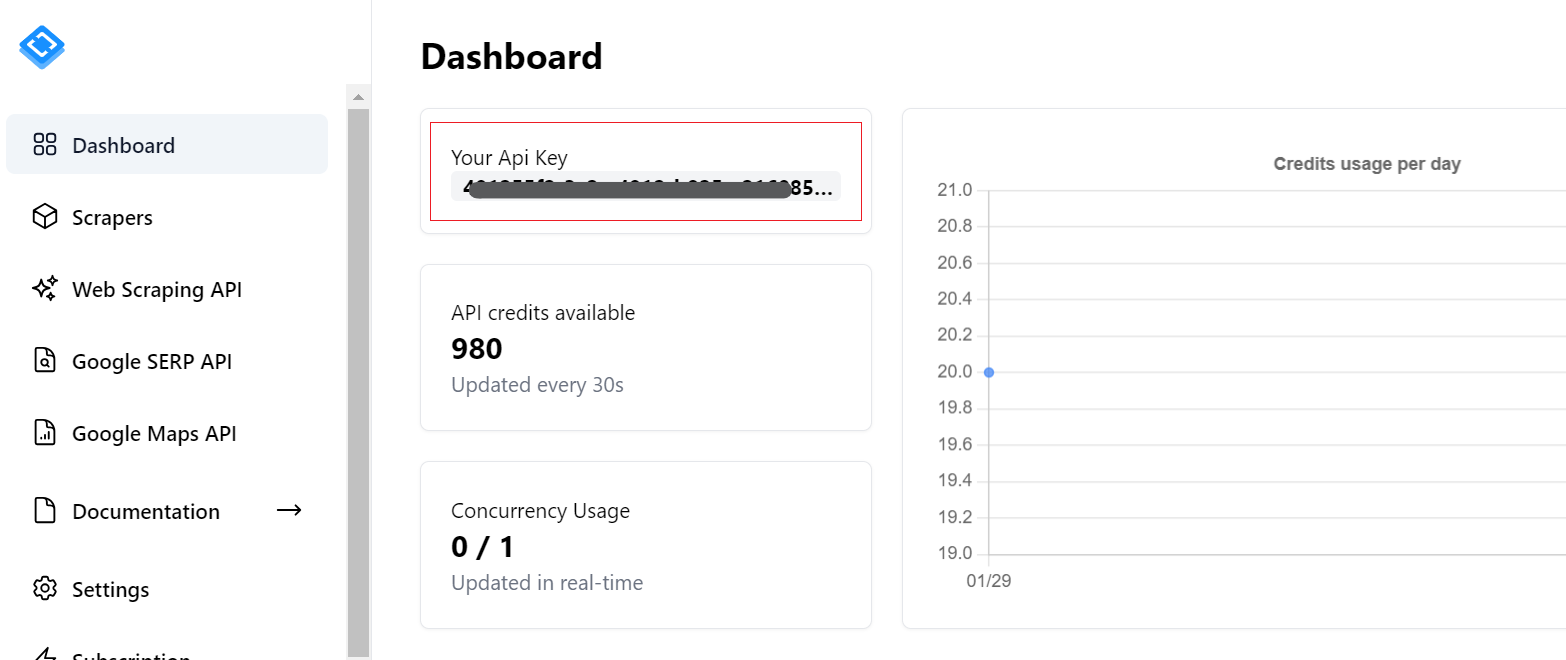
Untuk memulai, Anda memerlukan kunci API. Anda dapat menemukannya di akun Anda setelah masuk ke Scrape-It.Cloud. Selain itu, Anda akan menerima 1.000 kredit gratis saat mendaftar untuk menguji fitur kami.
Manfaat Menggunakan Scrape-It.Cloud untuk eBay Scraping
eBay, seperti kebanyakan platform online, memiliki sikap negatif terhadap bot scraping. Mengikis data dalam jumlah besar dalam waktu singkat dapat mengakibatkan peningkatan lalu lintas situs web, yang dapat memengaruhi kinerja dan ketersediaan. Hal ini dapat memperlambat waktu respons pengguna lain dan mengakibatkan calon pembeli tersesat. Meskipun tidak semua pengikis merusak situs dalam mengumpulkan data, eBay dapat mengambil langkah-langkah untuk membatasi bot tersebut ketika ditemukan.
Untuk membatasi bot, eBay menggunakan tindakan seperti CAPTCHA dan memblokir alamat IP yang mencurigakan. Langkah-langkah ini dapat mempersulit pengikisan, namun dapat dihindari. Misalnya, Anda dapat menerapkan layanan penyelesaian CAPTCHA di aplikasi Anda dan menggunakan proxy untuk menghindari pemblokiran alamat IP asli Anda. Namun, untuk melakukan ini, Anda perlu mencari proxy gratis, yang tidak dapat diandalkan, atau membeli proxy yang mahal dan mengonfigurasinya untuk rotasi.
Untuk menyelesaikan semua masalah ini sekaligus, daripada melewatinya satu per satu, yang bisa memakan banyak biaya, Anda dapat menggunakan layanan perantara yang mengumpulkan data untuk Anda dan memberi Anda data siap pakai. Perantara ini adalah API pengikisan web. Dalam contoh ini, kita akan melihat bagaimana kita dapat meningkatkan kode kita menggunakan API scraping web Scrape-It.Cloud, yang menggunakan berbagai mekanisme untuk menghindari teknik anti-scraping, termasuk penghindaran blok, penyelesaian CAPTCHA, rendering JavaScript, penggunaan proxy dan lagi.
Menerapkan API Scrape-It.Cloud di proyek Anda
Scrape-It.Cloud memungkinkan pengguna mengambil data yang ditargetkan secara langsung dalam format JSON, menyederhanakan proses ekstraksi data dan menghilangkan kebutuhan penguraian HTML. Berikut langkah-langkah untuk mengimplementasikan Scrape-It.Cloud API di proyek Anda:
- Tentukan URL API Scrape-It.Cloud.
- Tentukan payload: Ini berisi data permintaan dalam format JSON. Itu mengandung:
- URL Target: Alamat situs web yang ingin Anda pindai.
- Aturan ekstraksi: Aturan ini menentukan bagaimana elemen tertentu diekstraksi menggunakan pemilih CSS. Misalnya,
{"Title": ".product-title-css-selector"}Ekstrak elemen judul menggunakan kelas pemilih CSS yang ditentukan. Anda dapat menentukan aturan untuk berbagai titik data seperti harga, penjual, biaya pengiriman, dll. - Header: Ini mencakup informasi seperti kunci API Anda untuk autentikasi.
- Kirim permintaan POST dengan URL API, header, dan payload.
- Simpan respons JSON: Respons berisi semua titik data yang Anda tetapkan dalam aturan ekstraksi.
Apakah Anda melihat sesuatu yang berbeda dengan pendekatan ini? Ya! Anda tidak perlu mengurai kode HTML sendiri. Cukup pilih nama untuk titik data dan berikan pemilih CSS yang sesuai untuk data yang ingin Anda ekstrak. Scrape-It.Cloud menangani penguraian dan mengembalikan data secara langsung dalam format JSON.
Berikut adalah contoh sederhana dalam mengintegrasikan API Scrape-It.Cloud ke dalam proyek Anda:
def extract_page_data(url):
api_url = "<https://api.scrape-it.cloud/scrape>"
payload = json.dumps(
{
"url": url,
"js_rendering": True,
"extract_rules": {
"Title": "div.s-item__title",
"Price": "span.s-item__price",
"Seller": "s-item__seller-info-text",
"Shipping cost": "span.s-item__logisticsCost",
"List Date": "span.s-item__listingDate",
"URL": "a.s-item__link @href",
"next": "a.pagination__next @href",
},
"proxy_type": "datacenter",
"proxy_country": "US",
}
)
headers = {
# Put Scrape-it.cloud API key here
"x-api-key": "YOUR_API_KEY",
"Content-Type": "application/json",
}
full_response = requests.request("POST", api_url, headers=headers, data=payload)
data = json.loads(full_response.text)
title_df = pd.DataFrame(
data("scrapingResult")("extractedData").get("Title", ()), columns=("Title")
)
price_df = pd.DataFrame(
data("scrapingResult")("extractedData").get("Price", ()), columns=("Price")
)Berikut adalah kode lengkap untuk mengimplementasikan Scrape-It.Cloud API di proyek Anda.
import requests
import pandas as pd
from urllib.parse import urlencode
import json
def extract_page_data(url):
api_url = "<https://api.scrape-it.cloud/scrape>"
payload = json.dumps(
{
"url": url,
"js_rendering": True,
"extract_rules": {
"Title": "div.s-item__title",
"Price": "span.s-item__price",
"Seller": "s-item__seller-info-text",
"Shipping cost": "span.s-item__logisticsCost",
"List Date": "span.s-item__listingDate",
"URL": "a.s-item__link @href",
"next": "a.pagination__next @href",
},
"proxy_type": "datacenter",
"proxy_country": "US",
}
)
headers = {
# Put Scrape-it.cloud API key here
"x-api-key": "YOUR_API_KEY",
"Content-Type": "application/json",
}
full_response = requests.request(
"POST", api_url, headers=headers, data=payload)
data = json.loads(full_response.text)
title_df = pd.DataFrame(
data("scrapingResult")("extractedData").get("Title", ()), columns=("Title")
)
price_df = pd.DataFrame(
data("scrapingResult")("extractedData").get("Price", ()), columns=("Price")
)
seller_df = pd.DataFrame(
data("scrapingResult")("extractedData").get("Seller", ()), columns=("Seller")
)
shipping_df = pd.DataFrame(
data("scrapingResult")("extractedData").get("Shipping cost", ()),
columns=("Shipping cost"),
)
list_date_df = pd.DataFrame(
data("scrapingResult")("extractedData").get("List Date", ()),
columns=("List Date"),
)
url_df = pd.DataFrame(
data("scrapingResult")("extractedData").get("URL", ()), columns=("URL")
)
products = pd.concat(
(title_df, price_df, seller_df, shipping_df, list_date_df, url_df), axis=1
)
products("URL_split") = products("URL").apply(lambda x: x.split("?")(0))
products = products.drop(columns=("URL"))
next_page_url = data("scrapingResult")("extractedData").get("next")
next_page_url = next_page_url(0) if next_page_url else None
return products, next_page_url
def make_request(query, sort, items_per_page=60):
base_url = "<https://www.ebay.com/sch/i.html?">
query_params = {
"_nkw": query,
"_ipg": items_per_page,
"_sop": SORTING_MAP(sort),
}
return base_url + urlencode(query_params)
def write_to_csv(products, filename="product_info.csv"):
mode = "w" if not pd.io.common.file_exists(filename) else "a"
products.to_csv(filename, index=False, header=(mode == "w"), mode=mode)
print(f"Data has been written to {filename}")
def scrape_ebay(search_query, sort):
current_url = make_request(search_query, sort, 240)
total_products = pd.DataFrame()
while current_url:
products_on_page, next_page_url = extract_page_data(current_url)
if total_products.empty:
total_products = pd.DataFrame(products_on_page)
else:
total_products = pd.concat(
(total_products, products_on_page), ignore_index=True
)
write_to_csv(total_products)
current_url = next_page_url
SORTING_MAP = {
"best_match": 12,
"ending_soonest": 1,
"newly_listed": 10,
}
user_search_query = input("Enter eBay search query: ")
sort = input("Choose one ('best_match', 'ending_soonest', 'newly_listed'): ")
scrape_ebay(user_search_query, sort)Diploma
Tutorial ini memandu Anda dalam mengambil item data dari eBay. Kami menggunakan perpustakaan permintaan untuk mengunduh HTML mentah dan kemudian menguraikannya menggunakan BS4. Kami mengekstrak data yang diinginkan dari pohon HTML terstruktur menggunakan metode bawaan dan menyimpannya dalam file CSV. Terakhir, untuk menghindari pemblokiran, kami menggunakan API Scrape-It.Cloud, yang secara cerdas mengonfigurasi setiap web scraper untuk mencegah pemblokiran.
