
Memulung data dari Internet adalah alat yang ampuh bagi orang-orang yang perlu mengumpulkan informasi online dengan cepat. Dengan alat yang tepat dan beberapa pengetahuan, mudah untuk mengekstrak data dalam jumlah besar dari situs web untuk digunakan dalam aplikasi atau proyek lain.
Google Sheets adalah salah satu alat canggih yang memungkinkan pengguna mengekstrak data dari situs web dengan mudah tanpa memiliki pengetahuan pemrograman apa pun. Ini bagus untuk pemula karena Anda tidak perlu menulis kode untuk mendapatkan data dalam Excel (format XSLX atau CSV) - Anda hanya memerlukan pengetahuan dasar tentang spreadsheet dan rumus.
Rumus utama untuk web scraping di Google Sheets
Web scraping dengan Google Sheets memiliki banyak keunggulan dibandingkan metode tradisional, seperti: B. bahwa tidak diperlukan keahlian teknis yang hebat atau paket perangkat lunak yang mahal; dapat dengan cepat mengakses informasi terkini hanya dengan beberapa klik; Akses ke fitur bahasa kueri canggih yang menjadikannya lebih mudah dari sebelumnya; dan yang terpenting, mampu melakukan semua ini di lingkungan yang familiar bagi semua orang.
Google Spreadsheet menawarkan beberapa cara untuk mengekstrak data dari situs web. Metode paling sederhana adalah dengan menggunakan salah satu dari empat rumus:
- IMPORTFEED – Ambil data umpan RSS;
- IMPORTHTML – menggores daftar dan tabel;
- IMPORTDATA – Impor semua data terstruktur;
- IMPORTXML – Menggunakan kueri XPath untuk mengambil data arbitrer dari halaman web.
Bagi mereka yang memiliki keterampilan pemrograman, ada cara lain untuk mengekstrak data di Google Spreadsheet – skrip khusus yang ditulis dalam GS, yang mirip dengan bahasa pemrograman JavaScript. Metode ini menawarkan lebih banyak fleksibilitas daripada hanya mengandalkan rumus yang ada karena memungkinkan pengguna untuk menyesuaikan kode mereka sendiri untuk memenuhi kebutuhan tertentu.
Kikis produk WooCommerce dengan Google Spreadsheet
WooCommerce adalah platform eCommerce sumber terbuka yang memungkinkan pengguna membuat toko online menggunakan WordPress. Ini adalah salah satu yang paling populer (dengan lebih dari 5 juta pemasangan aktif) dan solusi serbaguna yang tersedia, menawarkan berbagai fitur seperti halaman produk yang dapat disesuaikan, berbagai metode pembayaran, alat manajemen inventaris, dan banyak lagi. WooCommerce juga menawarkan fitur pemasaran canggih seperti kupon, diskon, dan email penjualan otomatis. Itu sebabnya kami memilih WooCommerce sebagai contoh saat menulis scraper kami.
Kabar baik bagi mereka yang ingin mengikis situs web dengan WooCommerce – semua situs web yang menggunakan plugin ini memiliki struktur produk, tag, dan proses pengikisan yang sama. Artinya, setelah Anda mengetahui cara mengikis situs WooCommerce, Anda dapat dengan mudah mengekstrak data dari hampir semua toko lain di platform tersebut.
Menganalisis situs dengan Woocommerce
Sebelum Anda dapat mulai mengekstrak data dari situs web dan memprosesnya di Google Spreadsheet, Anda perlu melihat lebih dekat halaman web yang ingin Anda cari dan memutuskan data apa yang ingin Anda kumpulkan.
Mari kita lihat toko acak yang dibangun di platform WooCommerce. Untuk melihat kode HTML laman, Anda dapat menggunakan alat pengembang Chrome. Untuk melakukan ini, tekan F12 atau klik kanan pada ruang kosong di halaman dan pilih Inspect dari menu.
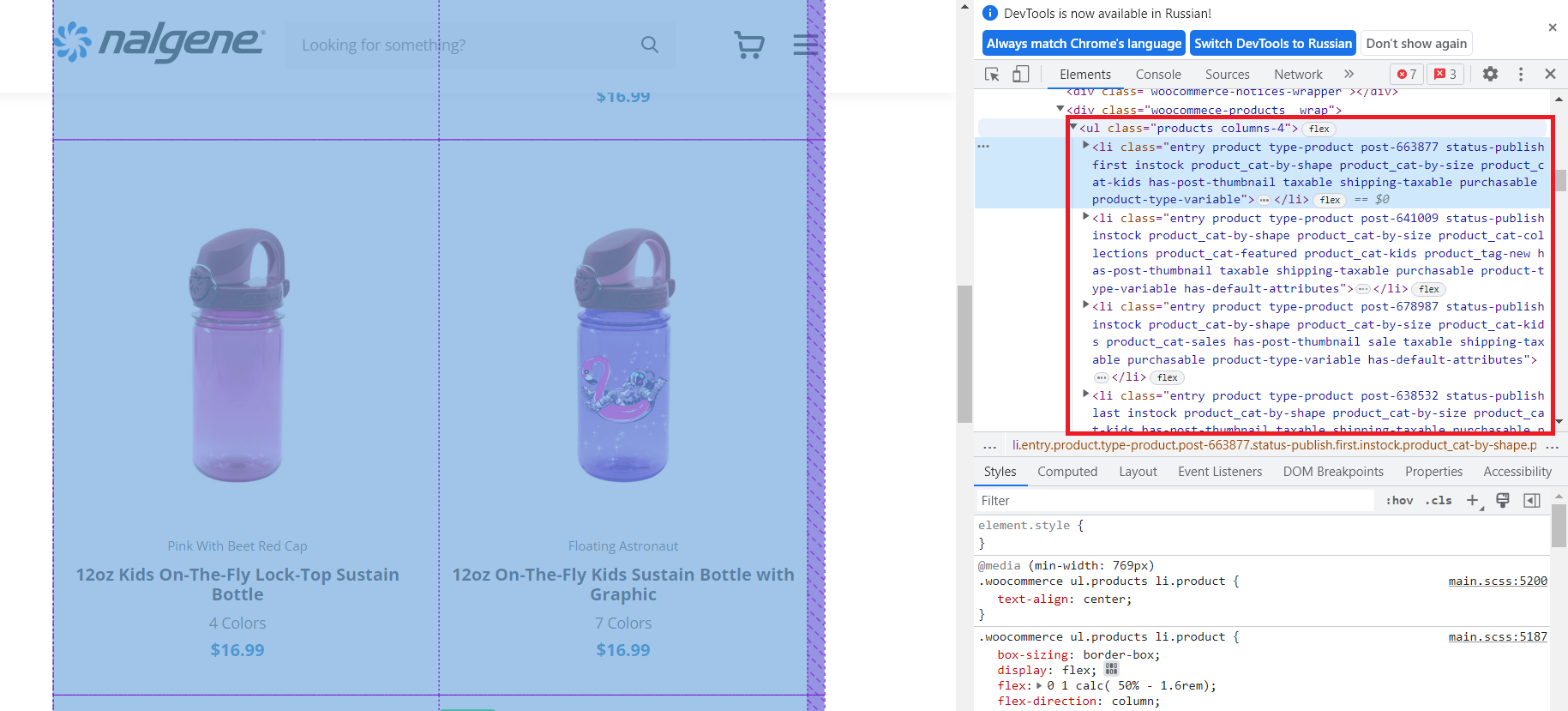
Seperti yang bisa kita lihat, semua produk ada di dalam
- tag dengan kelas "produk". Artinya semua produk berada dalam bentuk terstruktur di dalam tag ini. Kami akan menggunakan ini untuk mendapatkan nama, tautan, dan harga.
- Tautan ke halaman produk.
- Gambar produk.
- Nama produk.
- Variasi produk.
- Harga.
Mari kita lihat lebih dekat salah satu produknya:
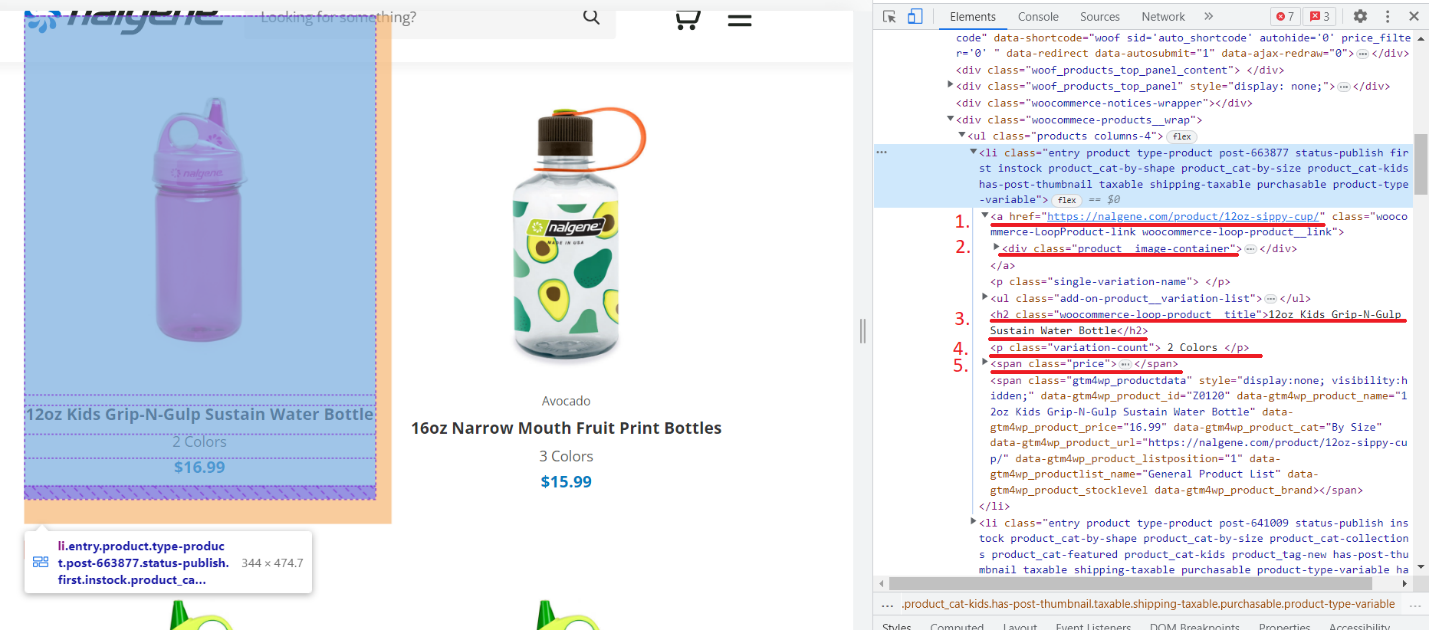
Kami telah memberi nomor pada tag yang berisi data yang ingin kami ekstrak:
Sekarang mari kita pergi ke halaman produk dan melihat informasi apa yang bisa kita peroleh tentangnya.

Di sini kita bisa mendapatkan deskripsi produk, fitur dan ulasannya. Sekarang setelah kita memiliki semua informasi yang diperlukan, mari mulai menambahkan data ke Google Spreadsheet.
Cara menggunakan IMPORTXML untuk web scraping di Google Sheets
Untuk mengekstrak data dari penyimpanan sampel, kami menggunakan fungsi IMPORTXML(), yang memungkinkan kami mengekstrak data dari halaman web menggunakan kueri XPath. XPath adalah bahasa kueri yang digunakan untuk menavigasi dokumen XML. Hal ini memerlukan pengetahuan dasar tentang struktur dan sintaksis HTML atau XML, serta keakraban dengan ekspresi XPath. Untuk membuat proses pengikisan lebih mudah bagi Anda, pantau terus tutorial kami yang memandu Anda mempelajari dasar-dasar penulisan ekspresi XPath yang efektif.
Meskipun menggunakan rumus IMPORTXML() memerlukan pengetahuan pemrograman, namun hal ini tidak terlalu sulit. Kami memerlukan tautan ke halaman produk dan XPath dari item yang perlu kami kikis. Secara umum rumusnya seperti ini:
=IMPORTXML(URL, XPath)Mencari halaman kategori toko menggunakan Google Sheets
Mari kita ambil link ke halaman produk salah satu kategori. Ada dua cara untuk mendapatkan XPath:
- Tulis sendiri.
- Salin dari peramban.
Pertama, mari kita salin dari browser dan kemudian lihat seperti apa tampilan XPath yang dikompilasi sendiri.
Buka halaman kategori di browser dan buka DevTools. Pilih fungsi pemilihan item dan klik pada nama item.
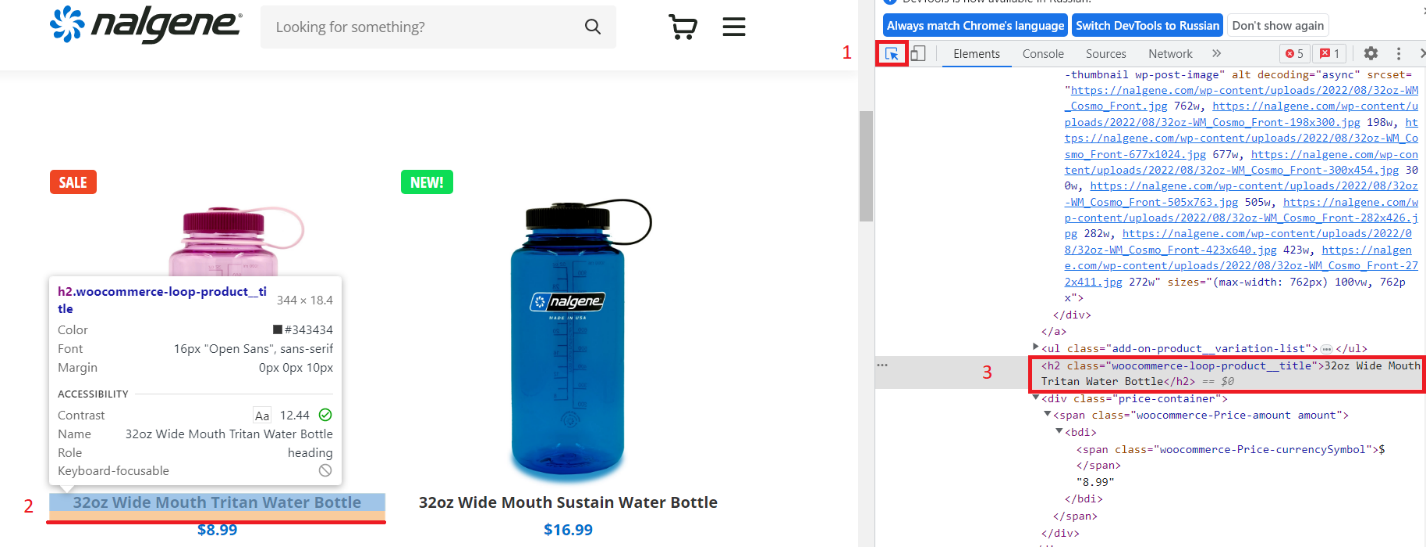
Kemudian klik kanan pada tag dengan nama produk dan pilih “Salin” – “Salin XPath”.
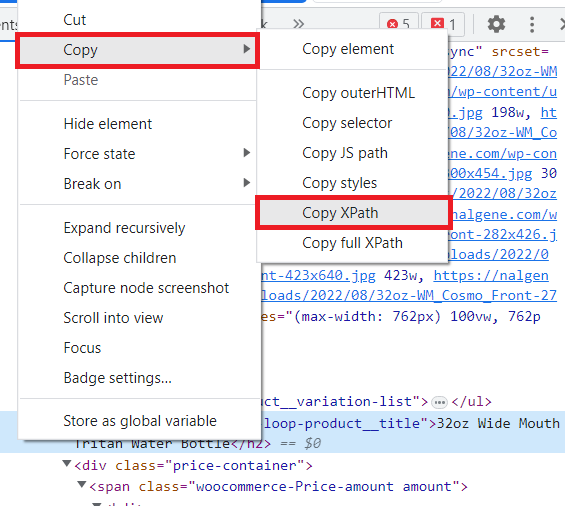
XPath yang dihasilkan terlihat seperti ini:
/html/body/div(1)/div(2)/div/main/article/div/div(3)/div/div/div/div(1)/h2Mari buka Google Sheets dan coba dapatkan judul menggunakan salinan XPath. Di sel A1, masukkan link ke halaman produk dan di sel B1 masukkan rumus:
=IMPORTXML(A1,"/html/body/div(1)/div(2)/div/main/article/div/div(3)/div/div/div/div(1)/h2")Alhasil, kami hanya mendapat satu gelar. Untuk memperbaikinya, mari ubah XPath:
=IMPORTXML(A1,"/html/body/div(1)/div(2)/div/main/article/div/div(3)/div/div/div/div/h2")Sekarang kami memiliki semua itemnya. Namun, XPath ini panjang dan sulit dipahami. Jadi mari kita buat sendiri XPath yang sesuai.
Mari kita lihat lebih dekat tag dengan judul:
<h2 class="woocommerce-loop-product__title">Botol Air Tritan Mulut Lebar 32oz</h2>Seperti yang bisa kita lihat, ini adalah tag h2 dengan kelas “woocommerce-loop-product__title”. Di XPath tampilannya seperti ini:
//h2(@class="woocommerce-loop-product__title")Ganti konten sel dengan rumus baru:
=IMPORTXML(A1,"//h2(@class="woocommerce-loop-product__title")")Hasilnya, kami mendapatkan daftar yang sama seperti sebelumnya, tetapi XPath sekarang terlihat lebih jelas dan lebih baik: cocok untuk digunakan tidak hanya di situs ini, tetapi juga di situs lain yang menggunakan WooCommerce.
Mengikis tautan kategori menggunakan Google Spreadsheet
Namun, sulit dan memakan waktu untuk menelusuri semua halaman kategori secara manual dan mendapatkan tautannya. Di sini kami telah menggunakan tautan ke kategori yang kami temukan sendiri. Namun mari kita ambil semua tautan kategori secara otomatis menggunakan rumus IMPORTLXML().
Pertama, mari kita dapatkan semua tautan di halaman:
=IMPORTXML("https://nalgene.com/#","//li/a/@href")Namun, beberapa tautan diduplikasi dan dapat mengganggu. Oleh karena itu, kami menggunakan rumus QUNIQUE() untuk hanya menyisakan nilai unik.
=UNIQUE(IMPORTXML("https://nalgene.com/#","//li/a/@href"))Sekarang gunakan fungsi REGEMATCH() di FILTER() untuk hanya menyisakan tautan yang berisi “kategori produk”:
=FILTER(UNIQUE(IMPORTXML("https://nalgene.com/#","//li/a/@href")),REGEXMATCH(UNIQUE(IMPORTXML("https://nalgene.com/#","//li/a/@href")),"product-category"))Dengan cara ini kami mendapatkan tautan ke semua kategori:
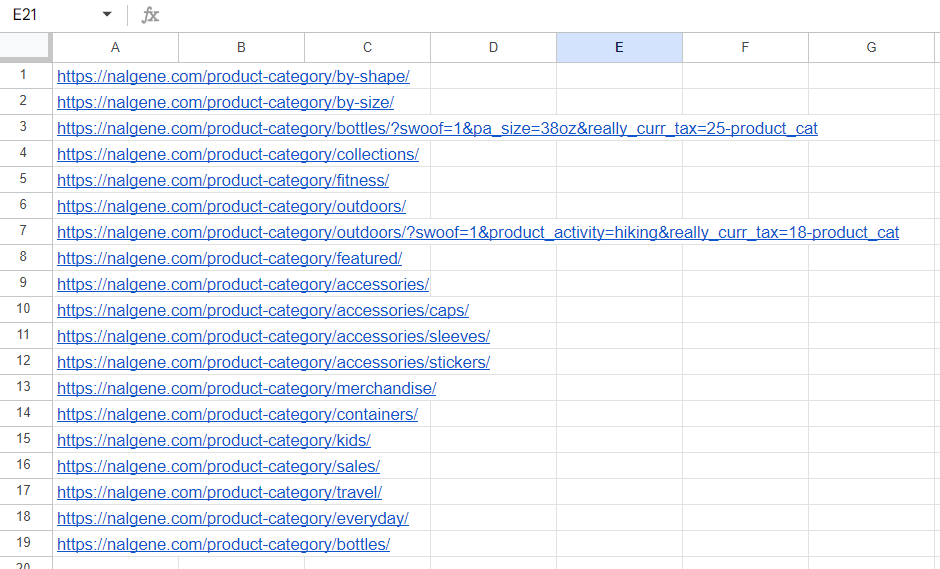
Sayangnya, fungsi IMPORTXML() tidak mendukung array. Oleh karena itu kami tidak dapat menentukan kolom link dan mendapatkan data untuk semua produk. Oleh karena itu, kami masih harus mengganti tautan secara manual, tetapi sekarang kami memiliki tautan ke semua kategori.
Hapus data produk dari toko WooCommerce
Kami terus mengumpulkan data tentang produk di halaman kategori. Terkadang kita tidak memerlukan teks dari sebuah tag, namun atribut dari tag tersebut. Untuk melakukan ini, tentukan atribut di akhir XPath Anda dan ambil isinya menggunakan simbol “@”. Misalnya, mari kita dapatkan link ke artikel. Pertama, lihat tag tautan item:
<div class="add-on-product">
<a href="https://nalgene.com/product/32oz-wide-mouth-bottle-tritan/">
…
</a>
</div>Tulis XPath yang sesuai:
//div(@class="add-on-product")/a/@hrefSeperti yang Anda lihat, semuanya sangat sederhana. Mari tuliskan XPath untuk dua elemen terakhir:
- Harga: //div(@class="wadah-harga")
- Gambar: //div(@class="add-on-product__image-container")/img/@src
Mari masukkan semua rumus ke dalam tabel (hanya XPath yang diubah) dan lihat hasilnya:
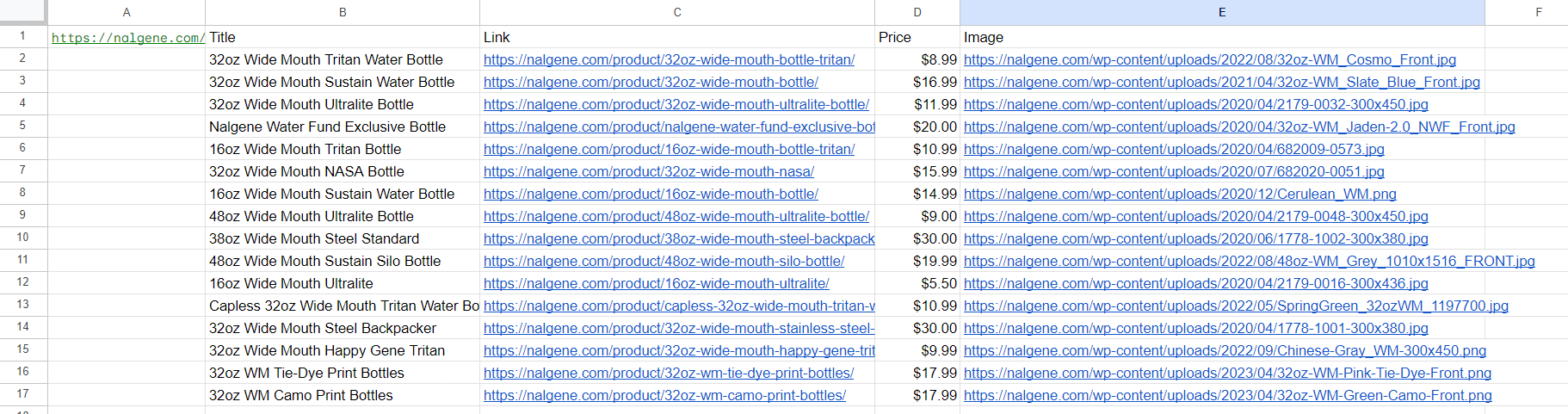
Sekarang mari tambahkan deskripsi produk. Kami sudah memiliki link ke halaman produk di kolom C, jadi mari gunakan itu. Pada kolom F, masukkan rumus untuk mendapatkan gambaran:
=IMPORTXML(C4,"//div(@class="product-description__wrap")")Hasilnya, kami mendapatkan tabel lengkap berisi data tentang produk dan deskripsinya. Kalau kita biarkan begitu saja maka deskripsinya akan terbagi menjadi beberapa kolom, sama seperti pembagian paragraf pada website. Untuk menggabungkannya kita menggunakan fungsi CONCATENATE() :
=concatenate(IMPORTXML((C2),"//div(@class="product-description__wrap")"))Hasilnya adalah tabel dengan deskripsi:
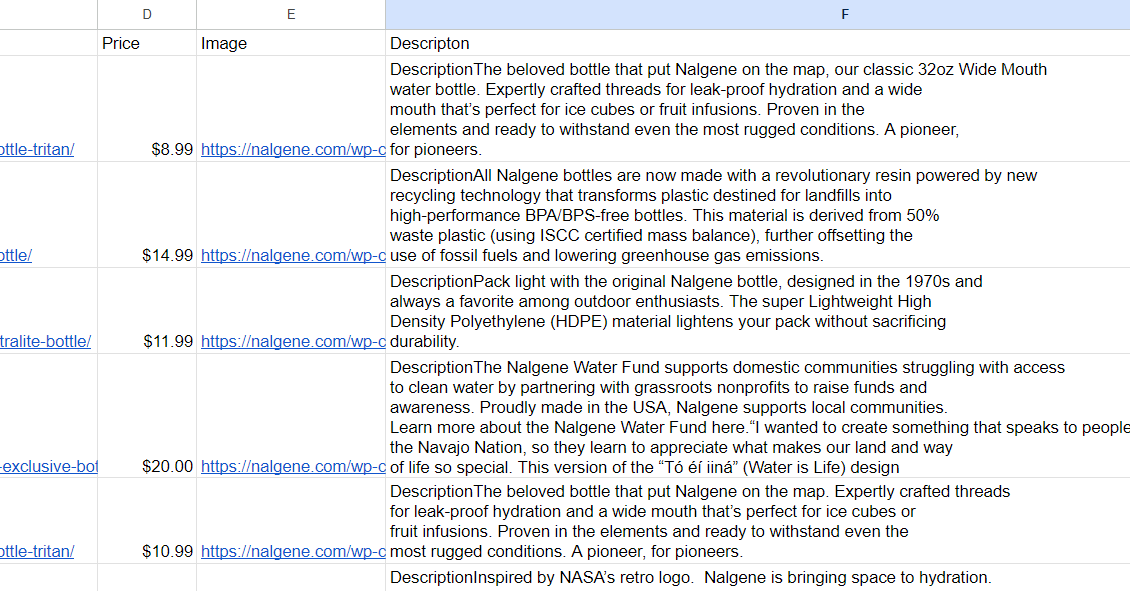
Sayangnya, fungsi CONCATENATE() memiliki satu kelemahan utama: fungsi ini menghubungkan bagian-bagian tanpa pemisah sehingga tidak terlalu praktis. Karena data dikembalikan sebagai array dan bukan string, kita tidak dapat menggunakan fungsi TEXTJOIN() yang memungkinkan kita menentukan pembatas.
Kelebihan dan Kekurangan IMPORTXML() untuk Web Scraping dengan Google Sheets
IMPORTXML() adalah alat canggih untuk mengumpulkan informasi dalam jumlah besar dengan cepat dan mudah di Google Spreadsheet. Ini membantu untuk menyalin data dari situs web langsung ke spreadsheet. Namun, penting untuk mempertimbangkan pro dan kontra sebelum memutuskan apakah ini pilihan yang tepat untuk Anda.
| Keuntungan | Kekurangan |
|---|---|
| Mudah digunakan tanpa memerlukan pengetahuan pemrograman | Jumlah kueri terbatas (1000 kueri per jam) |
| Dapat dengan cepat mengimpor data ke dalam spreadsheet | Terbatasnya kemampuan untuk menavigasi situs web dinamis |
| Bekerja dengan sebagian besar situs web | Bisa lambat saat mengambil data dalam jumlah besar |
| Penggunaan gratis | Hanya mengikis satu URL dalam rumus |
Rumus IMPORTXML sangat cocok untuk proyek web scraping di mana Anda memerlukan informasi spesifik untuk menganalisis tren atau menangani tugas lainnya. Oleh karena itu, ini adalah pilihan terbaik bagi mereka yang tidak pandai pemrograman. Namun, jika Anda merasa nyaman dengan pemrograman dan perlu melakukan tugas yang lebih kompleks, sekarang saatnya mempertimbangkan Google App Scripts.
Pengikisan Web dengan Skrip Aplikasi Google Sheets
Google Spreadsheet memiliki alat skrip yang canggih – Skrip Aplikasi. Alat ini memungkinkan Anda dengan cepat dan mudah mengotomatiskan banyak tugas yang biasanya memakan waktu berjam-jam. Dan jika Anda ingin mengakses data yang lebih kompleks daripada yang tersedia di antarmuka spreadsheet, Anda dapat menggunakan API web scraping.
Google App Scripts menggunakan JavaScript sebagai bahasa pemrogramannya. Dengan alat ini, pengguna memiliki akses ke fitur-fitur seperti membuat menu atau tombol khusus; akses ke layanan pihak ketiga; Edit dokumen yang disimpan di Drive; Kirim email langsung dari spreadsheet Anda atau bahkan akses sumber daya eksternal.
Untuk membuka panel Skrip Aplikasi, buka Ekstensi - Skrip Aplikasi.

Sebagai contoh, kita akan menggunakan API scraping web Scrape-It.Cloud. Setelah mendaftar, Anda akan menerima 1.000 kredit gratis untuk membantu Anda memulai.
Pertama, mari kita buat skrip sederhana yang mengambil semua kode halaman. Setelah memulai App Script, kita masuk ke jendela skrip.
Kita dapat memberi nama fungsi yang berbeda agar lebih mudah digunakan, atau kita dapat membiarkan nama yang sama. Ini memengaruhi cara kita merujuk skrip kita pada sheet. Nama fungsi adalah nama rumusnya.
Jika Anda tidak ingin mempelajari cara membuat skrip sendiri, tetapi ingin menggunakan hasil akhirnya, lanjutkan ke kode akhir dan penjelasan cara kerjanya.
Untuk menjalankan query, kita perlu mengatur parameternya. Anda dapat menemukan kunci API di akun Anda di area dasbor. Mari kita atur headernya terlebih dahulu:
var headers = {'contentType':'application/json','x-api-key': 'YOUR-API-KEY};Selanjutnya, kami menentukan isi permintaan. Karena kami memerlukan kode seluruh halaman, kami cukup menyediakan tautan ke situs tempat kami perlu mengumpulkan data:
var data ={'url': 'https://nalgene.com/water-bottles/wide-mouth/'};Terakhir, kami mengumpulkan kueri, menjalankannya, dan menampilkan hasilnya:
var options = {
'method': 'post',
'headers': headers,
'payload': data
};
var response = UrlFetchApp.fetch('https://api.scrape-it.cloud/scrape', options).getContentText();
Logger.log(response);Hasilnya, kami mendapatkan yang berikut:
Anda dapat mengonfigurasi pengaturan ekstraksi data di akun Anda di bagian Web Scraping API. Di sana Anda juga dapat mengonfigurasi kueri secara visual menggunakan fungsi khusus.
Misalnya, kita dapat menggunakan fitur Aturan Eksekusi untuk mengekstrak nama produk dan harga saja:
"extract_rules": {
"title": "h2.woocommerce-loop-product__title",
"price": "div.price-container"
},Menambahkan aturan baru ditentukan dalam format “nama”: “pemilih css”. Sangat tidak praktis untuk mengkodekan parameter-parameter ini ke dalam skrip. Untuk membuat rumus menjadi dinamis, akan lebih mudah untuk meneruskan parameter ini pada lembar. Jadi mari tambahkan data ini ke input. Parameter masukan diberikan dalam tanda kurung di sebelah nama fungsi.
function myFunction(...rules) {…}Artinya diperoleh beberapa parameter yang perlu dimasukkan ke dalam variabel kontrol. Untuk mempermudah, kami mengganti nama fungsi dan menambahkan parameter lain ke input - tautan ke halaman tempat data dikumpulkan.
function scrape_it(url, ...rules) {…}Sekarang mari kita deklarasikan variabel dan pilih header untuk tabel selanjutnya dari aturan ekstraksi yang kami terima:
var extract_rules = {};
var headers = true;
// Check if the last argument is a boolean
if (typeof rules(rules.length - 1) === "boolean") {
headers = rules.pop();
}Mari kita tulis aturan dalam formulir yang diperlukan ke dalam variabel ekstrak_rules:
for (var i = 0; i < rules.length; i++) {
var rule = rules(i).split(":");
extract_rules(rule(0)) = rule(1).trim();
}Mari kita ubah isi kueri dengan memasukkan variabel alih-alih nilai, lalu menjalankannya.
var data = JSON.stringify({
"extract_rules": extract_rules,
"wait": 0,
"screenshot": false,
"block_resources": true,
"url": url
});
var options = {
"method": "post",
"headers": {
"x-api-key": "YOUR-API-KEY",
"Content-Type": "application/json"
},
"payload": data
};
var response = UrlFetchApp.fetch("https://api.scrape-it.cloud/scrape", options);
Kueri ini mengembalikan data sebagai JSON dengan atribut yang berisi data yang diperlukan dan namanya sama dengan nama yang kita tetapkan dalam aturan ekstraksi. Untuk mendapatkan data ini, kami mengurai respons JSON:
var json = JSON.parse(response.getContentText());Mari kita atur variabel atribut yang berisi hasil aturan ekstraksi:
var result = json("scrapingResult")("extractedData");Temukan semua kunci dan panjang array terbesar untuk menemukan dimensinya:
// Get the keys from extract_rules
var keys = Object.keys(extract_rules);
// Get the maximum length of any array in extractedData
var maxLength = 0;
for (var i = 0; i < keys.length; i++) {
var length = Array.isArray(result(keys(i))) ? result(keys(i)).length : 1;
if (length > maxLength) {
maxLength = length;
}
}
Buat keluaran variabel di mana kita memasukkan baris data pertama, yang akan menjadi nama kolom tabel masa depan. Untuk melakukan ini, periksa judul dan kuncinya sehingga kita hanya dapat memasukkan kolom yang datanya ditemukan.
// Create an empty output array with the first row being the keys (if headers is true)
var output = headers ? (keys) : ();Mari kita telusuri semua elemen dari aturan ekstraksi dan menambahkannya ke variabel keluaran baris demi baris.
// Loop over each item in the extractedData arrays and push them to the output array
for (var i = 0; i < maxLength; i++) {
var row = ();
for (var j = 0; j < keys.length; j++) {
var value = "";
if (Array.isArray(result(keys(j))) && result(keys(j))(i)) {
value = result(keys(j))(i);
} else if (typeof result(keys(j)) === "string") {
value = result(keys(j));
}
row.push(value.trim());
}
output.push(row);
}
Terakhir, kami menampilkan kembali hasilnya di halaman:
return output;Sekarang Anda dapat menyimpan skrip yang dihasilkan dan memanggilnya langsung dari lembar, dengan menentukan parameter yang diperlukan.
Kode akhir untuk web scraping dengan Google App Script
Sebelum kita mulai dengan skrip aplikasi bawaan, mari kita lihat apa yang harus dilakukan bagi mereka yang melewatkan bagian membuat skrip tetapi ingin menggunakannya.
Buka Google Spreadsheet dan buat spreadsheet baru.
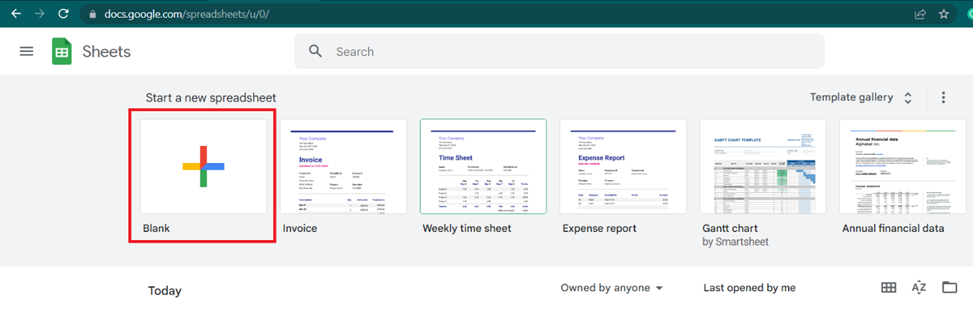
Buka Ekstensi dan buka Skrip Aplikasi. Di jendela yang muncul, pilih semua teks dan ganti dengan kode skrip kita:

Kode skrip:
function scrape_it(url, ...rules) {
var extract_rules = {};
var headers = true;
// Check if the last argument is a boolean
if (typeof rules(rules.length - 1) === "boolean") {
headers = rules.pop();
}
for (var i = 0; i < rules.length; i++) {
var rule = rules(i).split(":");
extract_rules(rule(0)) = rule(1).trim();
}
var data = JSON.stringify({
"extract_rules": extract_rules,
"wait": 0,
"screenshot": false,
"block_resources": true,
"url": url
});
var options = {
"method": "post",
"headers": {
"x-api-key": "YOUR-API-KEY",
"Content-Type": "application/json"
},
"payload": data
};
var response = UrlFetchApp.fetch("https://api.scrape-it.cloud/scrape", options);
var json = JSON.parse(response.getContentText());
var result = json("scrapingResult")("extractedData");
// Get the keys from extract_rules
var keys = Object.keys(extract_rules);
// Get the maximum length of any array in extractedData
var maxLength = 0;
for (var i = 0; i < keys.length; i++) {
var length = Array.isArray(result(keys(i))) ? result(keys(i)).length : 1;
if (length > maxLength) {
maxLength = length;
}
}
// Create an empty output array with the first row being the keys (if headers is true)
var output = headers ? (keys) : ();
// Loop over each item in the extractedData arrays and push them to the output array
for (var i = 0; i < maxLength; i++) {
var row = ();
for (var j = 0; j < keys.length; j++) {
var value = "";
if (Array.isArray(result(keys(j))) && result(keys(j))(i)) {
value = result(keys(j))(i);
} else if (typeof result(keys(j)) === "string") {
value = result(keys(j));
}
row.push(value.trim());
}
output.push(row);
}
return output;
}
Daripada “KUNCI API ANDA”, masukkan dan simpan kunci API Anda, yang dapat ditemukan di bagian dasbor Scrape-It.Cloud di akun Anda.
Sekarang mari kita lihat hasil pekerjaannya. Mari kembali ke sheet, masukkan link ke halaman di sel A1 dan di sel berikutnya tentukan rumusnya. Secara umum rumusnya seperti ini:
=scrape_it(URL, element1, (element2), (false))Di mana:
- URL adalah tautan ke halaman yang akan dikikis.
- Elemen (Anda dapat menentukan lebih dari satu). Elemen ditentukan dalam format “Judul: CSS_Selector @attribute”. Alih-alih judul, tentukan nama elemen, lalu gunakan titik dua untuk menentukan pemilih CSS elemen dan, jika perlu, gunakan spasi dan @ untuk menentukan atribut yang nilainya diperlukan. Jika hanya teks elemen yang diperlukan, tidak ada atribut yang ditentukan. Misalnya:
- “Judul: h2” – untuk mendapatkan nama produk.
- “link: a @href” – untuk mendapatkan link produk.
- (SALAH). Ini adalah parameter opsional yang digunakan secara default BENAR. Ini menunjukkan apakah judul kolom harus disimpan atau tidak. Jika Anda tidak menentukan apa pun, header ditentukan di sel pertama dan diambil dari parameter Elemen. Jika Anda menentukan SALAHJudul kolom tidak ditentukan dan disimpan.
Sekarang, dengan menggunakan semua keterampilan yang telah kita pelajari, mari buat tabel yang identik dengan yang kita dapatkan dengan IMPORTXML, tetapi menggunakan rumus scrape_it:
=scrape_it(A1,"title: h2.woocommerce-loop-product__title", "price: div.price-container","link:div.add-on-product>a @href", "Image:div.add-on-product__image-container>img @src")Hasilnya, kami mendapatkan tabel berikut:
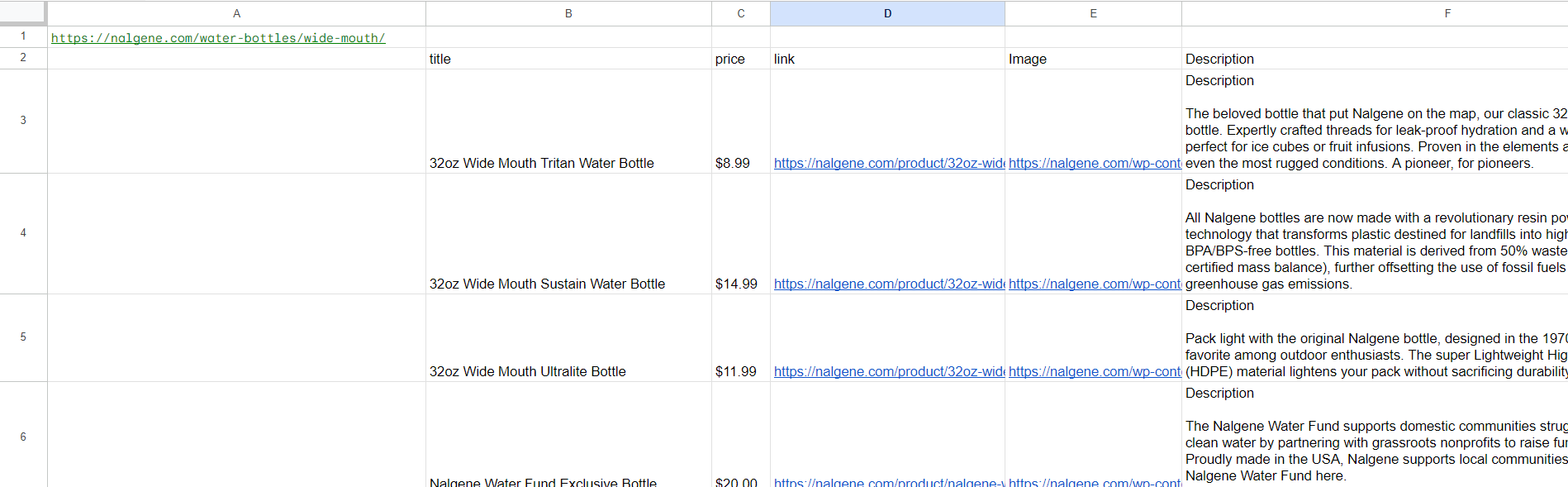
Namun, kita perlu mendapatkan deskripsi dari masing-masing halaman produk, jadi kita tidak perlu memberikan judul. Dalam hal ini kita perlu menentukan parameter tambahan ketiga SALAH, di akhir rumus:
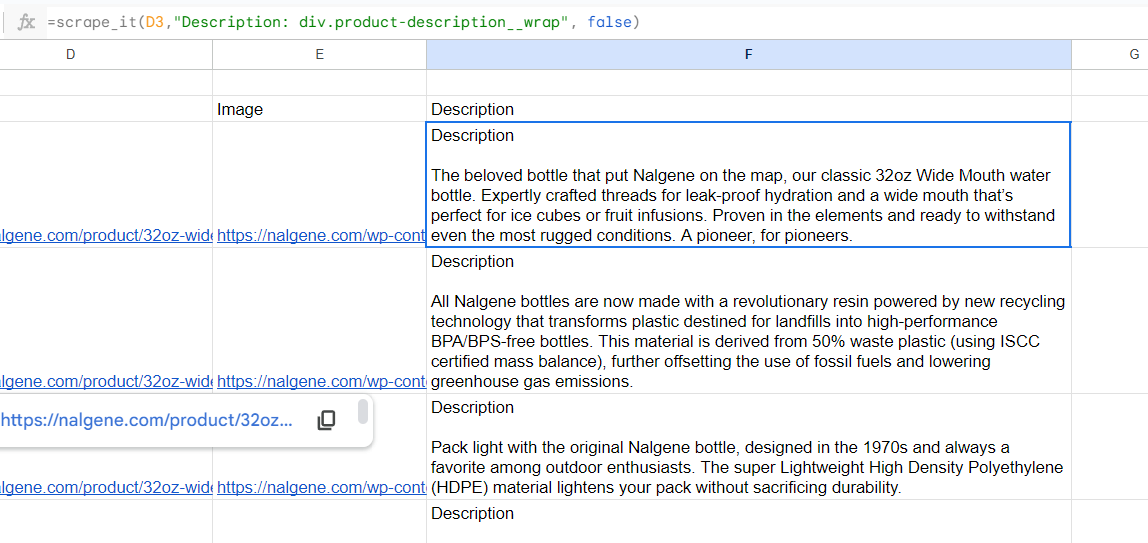
Mengikis dengan Google Spreadsheet dan App Script dapat menjadi alat pengumpulan dan analisis data yang hebat. Dengan bantuan bahasa skrip Google, Anda dapat dengan mudah mengakses situs web eksternal untuk mengambil informasi, menggunakan API web scraping untuk mengotomatiskan proses, atau bahkan memanipulasi hasil dengan cara yang sesuai dengan tujuan Anda.
Akan lebih mudah jika IMPORTXML tidak dapat digunakan. Misalnya, Anda tidak dapat menggunakan IMPORTXML untuk situs web rendering dinamis. Namun, menggunakan Google App Script bersama dengan Web Scraping API dapat mengatasi masalah ini. Skrip yang dipertimbangkan cocok untuk menggores situs mana pun, terlepas dari platform apa yang mendasarinya, apakah situs tersebut memiliki rendering dinamis atau tidak.
Kesimpulan dan temuan
Pengambilan data web dengan Google Spreadsheet adalah cara terbaik untuk mengumpulkan dan mengatur data dari situs web dengan cepat. Ini adalah alat ramah pengguna yang dapat digunakan oleh siapa saja, bahkan mereka yang tidak memiliki pengetahuan atau pengalaman pemrograman. Dengan langkah yang tepat, Anda dapat membuat web scraper yang canggih hanya dalam beberapa menit. Dari sana, terserah Anda bagaimana Anda ingin menggunakan informasi yang baru dikumpulkan - apakah untuk riset pasar atau membuat laporan khusus Anda sendiri.
Dengan alat pengikis seperti Google Spreadsheet, setiap orang memiliki akses ke data situs web yang berharga tanpa memerlukan sumber daya tambahan atau program perangkat lunak yang mahal. Selain itu, fitur bawaan membuat pembersihan kumpulan data yang berantakan menjadi cepat dan mudah – menghemat waktu pada tugas manual sehingga Anda dapat fokus pada hal yang paling penting: memanfaatkan wawasan yang diperoleh dari data yang Anda simpan.
