
Saat melakukan scraping data, langkah pertama adalah menemukan data itu sendiri. Hal ini dapat dilakukan dengan banyak cara - melalui atribut unik, nama kelas, ID, atau pemilih CSS. Namun karena adanya elemen dinamis, terkadang pencarian data dan identifikasi elemen HTML menjadi lebih sulit. Di sinilah XPath berperan.
Ketika halaman web dimuat ke browser, itu menghasilkan struktur DOM (Document Object Model). Pada saat yang sama, XPath adalah bahasa kueri yang menanyakan objek di DOM. Hal ini menjadikan XPath cara yang baik untuk mencari elemen web di situs web menggunakan Selenium juga.
Sintaks XPath
XML Path atau biasa dikenal dengan XPath adalah bahasa query untuk dokumen XML. Ini memungkinkan penulisan alur navigasi dokumen XML untuk mencari elemen web apa pun.
Sintaks XPath terdiri dari atribut dan tag DOM, sehingga memungkinkan untuk menemukan elemen apa pun di halaman web menggunakan DOM. Umumnya, XPath dimulai dengan “//” dan terlihat seperti ini:
//tag_name(@Attribute_name = "Value")/child nodesDimana nama tag adalah nama node, @ berarti awal nama atribut yang dipilih dan nilainya membantu memfilter hasilnya.
Contoh XPath adalah sebagai berikut:
//*(@id="w-node")/div/a(1)Jenis XPath
Hanya ada dua jenis XPath di Selenium: XPath absolut dan XPath relatif.
Contohnya menggunakan halaman web dengan kode HTML berikut:
<!DOCTYPE html>
<html>
<head>
<title>Toko sampel</title>
</head>
<body>
<div class="product-item">
<img src="https://scrape-it.cloud/blog/example.com\item1.jpg">
<div class="product-list">
<h3>Pena</h3>
<span class="price">10$</span>
<a href="/id/example.com\item1.html/" class="button">Membeli</a>
</div>
</div>
<div class="product-item">
<img src="example.com\item2.jpg">
<div class="product-list">
<h3>Buku</h3>
<span class="price">20$</span>
<a href="/id/example.com\item2.html/" class="button">Membeli</a>
</div>
</div>
</body>
</html>XPath mutlak
Menggunakan XPath absolut membantu menemukan elemen tertentu secara akurat. Sebagai contoh, mari kita tuliskan XPath absolut untuk nama produk:
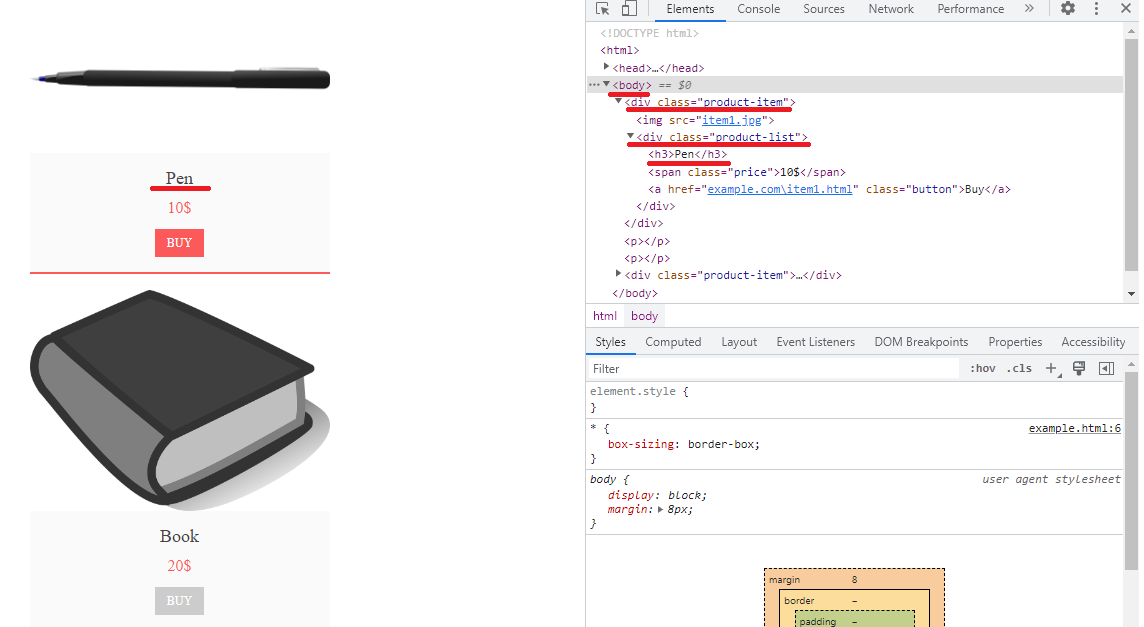
XPath Mutlak:
/html/body/div(1)/div/h3Untuk menyalin XPath dari Chrome DevTools (tekan F12 untuk membuka), cukup centang item (Ctrl+Shift+C atau centang di bawah):
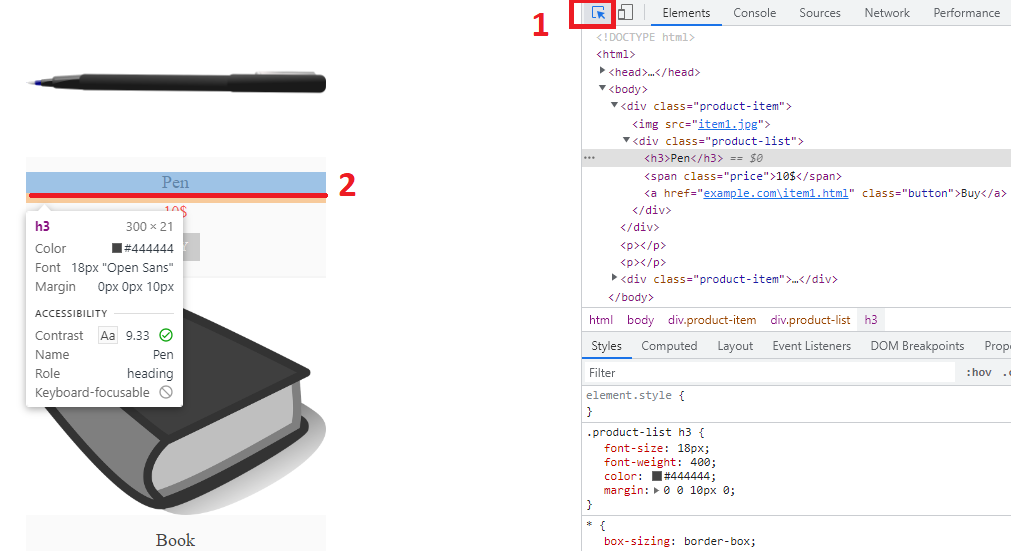
Kemudian klik kanan garis highlight di jendela item dan pilih Copy/Copy Full XPath:
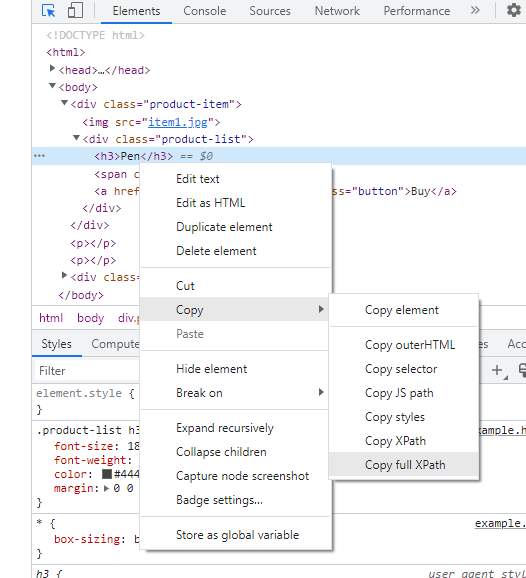
XPath yang dihasilkan dapat diperiksa di konsol:
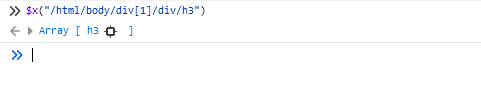
Di sini Anda juga dapat menyalin kode HTML elemen ini. Cukup klik kanan pada hasilnya dan pilih “Salin Objek”:

Hasil:
<h3>Pena</h3>Metode ini juga dikenal sebagai pencarian garis miring tunggal dan paling rentan terhadap perubahan kecil pada struktur halaman.
XPath Relatif
XPath Relatif lebih fleksibel dan tidak bergantung pada perubahan kecil pada struktur halaman. XPath relatif berikutnya menemukan elemen yang sama dengan XPath absolut di bawah ini:
//*(@class="product-list")/h3Mari kita periksa ini:

Hasil:
( {<h3>Pena</h3>}, {<h3>Buku</h3>} )XPath relatif dapat mulai mencari di mana saja dalam struktur DOM. Selain itu, ini lebih pendek dari Absolute XPath.
Pemilih XPath VS CSS
Seseorang yang telah membaca tentang penyeleksi CSS mungkin tidak dapat memilih di antara keduanya. Perbedaan utama antara pemilih XPath dan CSS adalah XPath memungkinkan Anda untuk bergerak maju dan mundur, sedangkan pemilih CSS hanya bergerak maju dan tidak melihat elemen induk. Namun, XPath berbeda di setiap browser, sehingga tidak dapat diterapkan secara universal.
Hal ini menunjukkan bahwa penyeleksi CSS paling baik digunakan ketika tujuannya adalah untuk mengurangi waktu atau menyederhanakan kode. XPath lebih cocok untuk tugas yang lebih kompleks. Anda dapat menemukan artikel lengkap tentang penyeleksi CSS di sini.
Cara menggunakan XPath di Selenium
Untuk mengikis data dengan Selenium, digunakan kelas By class. Ada dua metode yang berguna untuk menemukan elemen halaman yang dikombinasikan dengan kelas By untuk memilih atribut. Mereka:
find_elementmengembalikan contoh pertama dari beberapa elemen web dengan atribut tertentu di DOM. Jika tidak ada elemen yang ditemukan, metode akan memunculkan NoSuchElementException.find_elementsMengembalikan nilai kosong jika elemen tidak ditemukan, atau daftar semua contoh elemen web yang cocok dengan atribut yang ditentukan.
Jadi, untuk mencari nama produk pena menggunakan XPath di Selenium:
from selenium.webdriver.common.by import By
driver.find_element(By.XPATH, '//*(@class="product-list")/h3')Dan daftarnya berisi semua nama produk:
from selenium.webdriver.common.by import By
driver.find_elements(By.XPATH, '//*(@class="product-list")/h3')XPath Dinamis di Selenium
Untuk melakukan kueri tertentu, perintah khusus dan operator XPath dapat digunakan.
XPath dengan operator logika: OR & AND
Operator logika diperlukan untuk mencari elemen dengan lebih tepat tergantung pada kondisi yang ditentukan. XPath dapat menggunakan dua operator logika: atau & dan. Anda harus ingat bahwa ini peka huruf besar-kecil. Oleh karena itu, penggunaan “OR” dan “AND” adalah salah.
Operator logika ATAU
Kueri XPath ini mengembalikan turunan yang cocok dengan nilai pertama, nilai kedua, atau keduanya. Misalnya:
//tag_name(@Attribute_name = "Value" or @Attribute_name2 = "Value2")Ini mengembalikan:
| Atribut 1 | Atribut 2 | Hasil |
| SALAH | SALAH | Tidak ada elemen |
| BENAR | SALAH | Mengembalikan A |
| SALAH | BENAR | Pengembalian B |
| BENAR | BENAR | Mengembalikan keduanya |
Mari kita modifikasi contoh di atas dan periksa fungsi operator logika atau. Bayangkan pena disimpan dalam sebuah wadah:
<span time-in="150" class="price">10$</span>Dan harga buku:
<span time-in="100" class="price">20$</span>Gunakan operator logika atau:
//span(@time-in = "100" or @class = "price")Hasil:
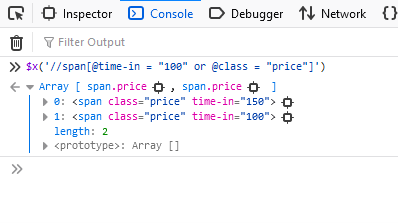
Kueri mengembalikan kedua produk karena keduanya memiliki kelas “Harga”.
Operator logika DAN
Kueri XPath ini mengembalikan turunan yang hanya cocok dengan kedua nilai. Misalnya:
//tag_name(@Attribute_name = “Value” and @Attribute_name2 = “Value2”)Ini mengembalikan:
| Atribut 1 | Atribut 2 | Hasil |
| SALAH | SALAH | Tidak ada elemen |
| BENAR | SALAH | Tidak ada elemen |
| SALAH | BENAR | Tidak ada elemen |
| BENAR | BENAR | Mengembalikan keduanya |
Untuk memeriksanya, cukup gunakan contoh di atas dan ubah operator OR menjadi AND:

XPath dengan Mulai-Dengan()
Metode ini membantu menemukan item yang dimulai dengan cara tertentu. Misalnya, di sini Anda dapat menemukan artikel “Pengikisan web dengan Python: Dari dasar hingga latihan”.
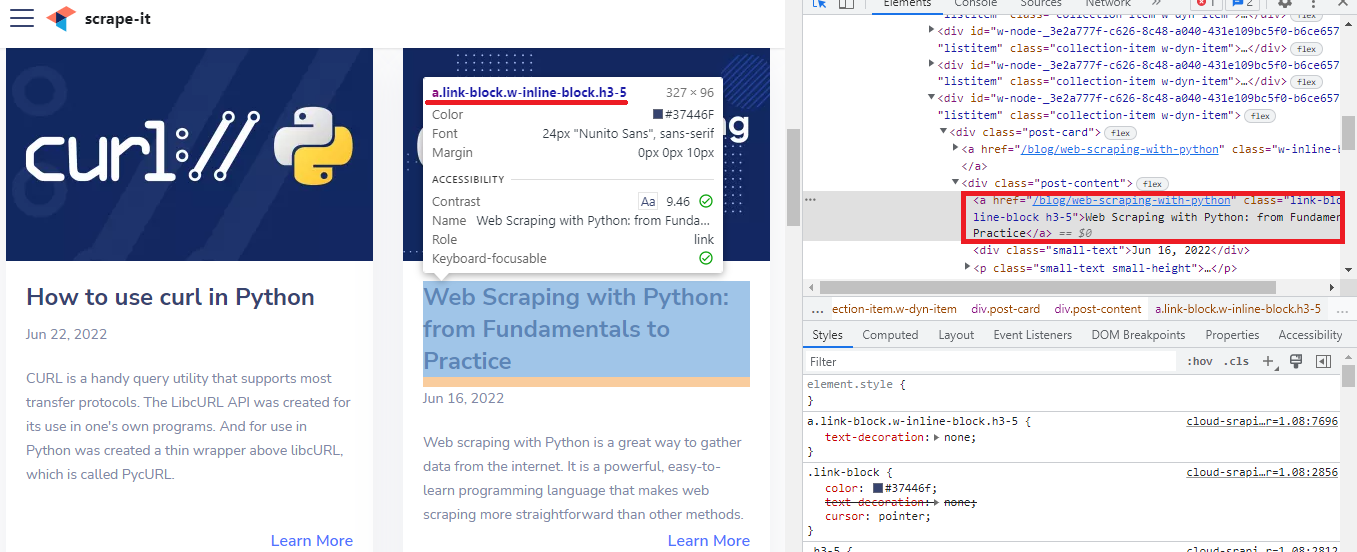
XPath akan menjadi yang berikutnya:
//a(starts-with(text(),'Web Scraping'))atau
//a(starts-with(text(),'Web'))Mari kita periksa ini:
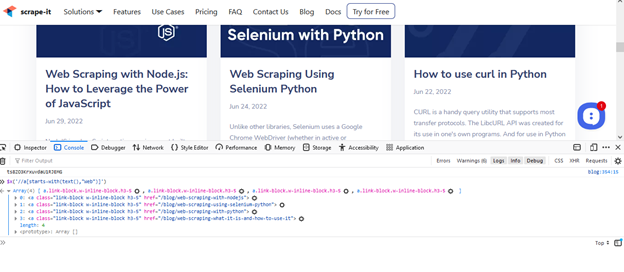
Tapi yang berikutnya salah:
//a(starts-with(text(),'Scraping with Python'))Metode ini dapat digunakan tidak hanya untuk elemen statis, tetapi juga untuk elemen dinamis (sebagai tombol). Misalnya:
//span(starts-with(@class, 'read-more-link'))XPath dengan indeks
Metode ini berguna ketika Anda perlu mencari elemen tertentu di DOM. Misalnya:
//tag(@attribute_name="value")(element_num)Mari kembali ke contoh operator OR dan coba temukan hasil pertama saja:
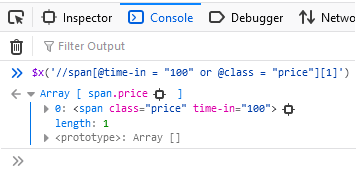
XPath dengan yang berikut ini
Metode ini digunakan untuk mencari elemen web atau elemen yang mengikuti elemen yang diketahui. Sintaks berikut adalah yang berikutnya:
//tag(@attribute_name="value")//following::tagNamun, tag tersebut tidak boleh berada di sebelah tag yang dikenal atau pada level yang sama. Selenium memilih yang terdekat:
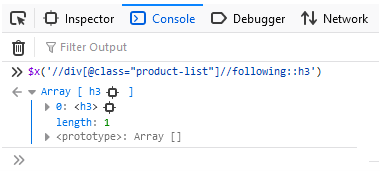
XPath dengan saudara berikut
Metode ini menemukan elemen terdekat dengan induk yang sama. Ini memiliki sintaks berikut:
//tag(@attribute_name="value")//following-sibiling::tag
Hasilnya sama dengan contoh sebelumnya.
XPath dengan Sebelumnya
Metode sebelumnya menemukan semua elemen sebelum node saat ini:
//tag(@attribute_name="value")//preceding::tagMencari yang terdekat di semua tingkatan.
XPath dengan saudara sebelumnya
Sama seperti yang sebelumnya, tetapi mencari elemen sebelum node saat ini dengan node induk yang sama:
//tag(@attribute_name="value")//preceding-sibling::tagXPath dengan Anak
Metode ini digunakan untuk menemukan semua anak dari node tertentu:
//tag(@attribute_name="value")//child::tag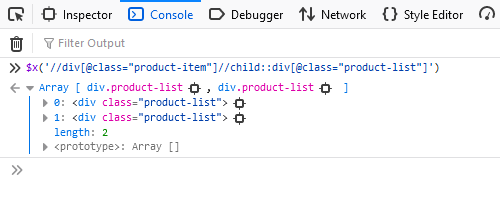
XPath dengan Orang Tua
Metode ini digunakan untuk menemukan semua orang tua dari node tertentu:
//tag(@attribute_name="value")//parent::tagXPath dengan keturunan
Metode ini digunakan untuk menemukan semua keturunan (simpul anak, simpul cucu, dll.) dari simpul tertentu:
//tag(@attribute_name="value")//descendants::tagXPath dengan leluhur
Metode ini digunakan untuk menemukan semua leluhur (simpul induk, simpul kakek-nenek, dll.) dari suatu simpul tertentu:
//tag(@attribute_name="value")//ancestors::tagKesimpulan dan temuan
Jadi XPath di Selenium dapat membantu menemukan elemen untuk pengikisan lebih lanjut. Ini dapat bekerja dengan data statis dan dinamis. Selain itu, tidak seperti penyeleksi, XPath dapat beroperasi di semua tingkat struktur DOM, termasuk elemen induk.
