
Pelajari cara melakukan QA data menggunakan Python. Itu Penyempurnaan data adalah masalah besar bagi ilmuwan data dan analis data. Seperti yang telah kami sebutkan berkali-kali, sebagian besar profesional data menghabiskan 50 hingga 80 persen waktunya untuk menyempurnakan data. Untuk mengatasi rintangan ini, kami memiliki berbagai sistem untuk memastikan kualitas data Anda yang tertinggi.
Di salah satu artikel kami sebelumnya, kami mempelajari cara mengekstrak data dari web menggunakan Python. Dari banyak wawasan yang kami peroleh, kesimpulan terpentingnya adalah menangani data dalam jumlah besar bukanlah proses yang mudah.
Dalam kebanyakan kasus, kami tidak menggunakan data setelah crawler selesai mengekstraksi data.
Kami harus mengatasi beberapa kerumitan sebelum data siap untuk diterapkan. Untuk memverifikasi integritas kumpulan data dengan benar, berbagai teknik jaminan kualitas digunakan.
Dalam artikel ini, kita akan melihat beberapa cara Pythonic untuk memastikan kualitas kumpulan data yang unggul dan mengatasi masalah yang terkait dengan kasus penggunaan bisnis Anda.
Mengapa menggunakan Python untuk jaminan kualitas data Anda?
Python adalah bahasa pemrograman tujuan umum yang sangat intuitif untuk digunakan. Ini memiliki komunitas yang luas dan banyak perpustakaan termasuk namun tidak terbatas pada: panda, scikit-learnDan pyspark.
Pustaka ini dapat memenuhi hampir semua kebutuhan analisis dan manipulasi data Anda. Tepatnya, pyspark menyediakan API untuk Apache Spark yang memungkinkan pemrosesan data skala besar secara real time.
Oleh karena itu, Python adalah pilihan optimal untuk pemrosesan dan validasi data. Untuk pemahaman yang lebih baik kami menggunakan pandas untuk sisa blog ini.
Pengujian kotak hitam QA data dengan Python
Black box secara umum adalah suatu metode pengujian perangkat lunak yang menguji fungsionalitas suatu aplikasi tanpa melihat struktur internal atau cara kerjanya.
Terinspirasi oleh metode pengujian perangkat lunak yang sangat sukses ini, kami membuat kotak hitam kami sendiri, yang bisa dikatakan sebagai Kotak Hitam Data QA.
Di Grepsr, ini adalah titik awal dari semua proses jaminan kualitas kami. Kami menggunakannya untuk pengujian otomatis guna menandai anomali dalam kumpulan data.
Tim QA menjalankan setiap proyek data individu melalui kotak hitam. Ini memberikan contoh laporan berdasarkan proses statistik dan logis yang telah ditetapkan sebelumnya. Dengan menggunakan contoh laporan, kami mendapatkan wawasan yang berarti dan membuat perubahan yang diperlukan.
Karena tidak masuk akal untuk menggeneralisasi integritas data menggunakan proses yang sama, kami sering kali menyesuaikan kotak hitam dengan persyaratan. Anda dipersilakan untuk menyampaikan kekhawatiran Anda. Kami dapat memperbarui skrip Black Box sesuai saran Anda.
Hal ini tidak diragukan lagi memungkinkan tim QA memecahkan masalah anomali kumpulan data dan menemukan cara untuk mengatasinya.
Dari sini adalah test_dataset.csv akan menjadi dataset utama yang akan kami kerjakan. Mari kita mulai memuat ke dalam pandas.DataFrame.
import pandas as pd
import chardet
import re
import numpy as np
with open("./test_dataset.csv", "rb") as f:
enc = chardet.detect(f.read())
df = pd.read_csv("./test_dataset.csv", encoding= enc("encoding"))
df.dropna(how="all",axis=0,inplace=True)Hal pertama yang pertama: Anda mendapatkan data dalam pengkodean yang Anda inginkan. Kami memiliki naskah kami sendiri untuk mengatasi permasalahan tersebut.
Analisis persyaratan untuk proyek QA data Anda dengan Python
Langkah pertama dalam proses QA adalah memeriksa apakah kumpulan data memenuhi kebutuhan Anda. Mari kita lihat beberapa kasus penggunaan:
1. Perbandingan daftar masukan
Dalam banyak kasus penggunaan yang kami temui, pelanggan mengharapkan kami merayapi produk dengan SKU tertentu. Untuk memenuhi persyaratan, kami mencocokkan SKU yang masuk dengan daftar SKU yang telah ditentukan sebelumnya.
Mari kita lihat apakah SKU-nya identik:
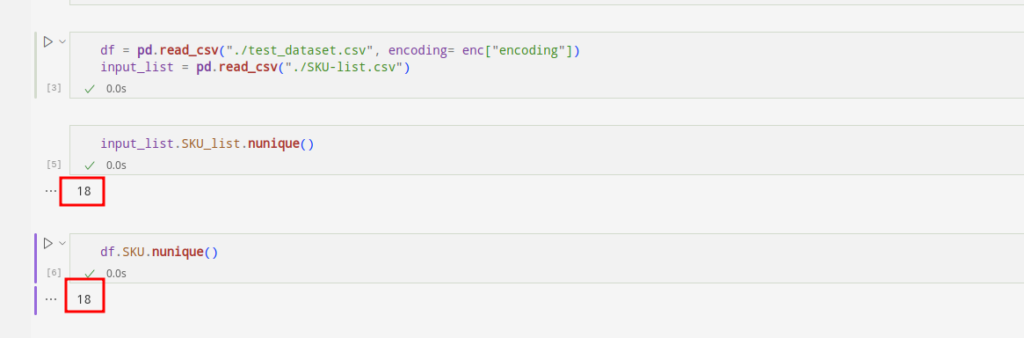
df(~df.SKU.isin(input_list.SKU_list.unique().tolist())).loc(:,"SKU").unique().tolist()input_list(~input_list.SKU_list.isin(df.SKU.unique().tolist())).loc(:,"SKU_list").unique().tolist()
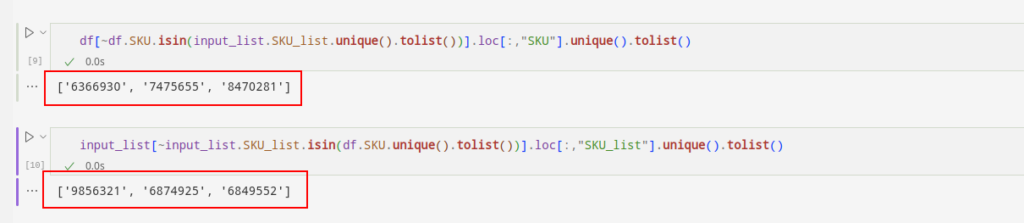
Kita dapat melihat bahwa daftar SKU pertama menunjukkan SKU yang hilang. Yang hilang ada di lembar masukan, tapi tidak di kumpulan data. Daftar SKU kedua menghadirkan dilema sebaliknya.
Hal ini memungkinkan kami mengidentifikasi SKU yang hilang dan menambahkannya ke kumpulan data asli yang Anda perlukan.
2. Ikuti aturannya
Jika ada kolom dalam kumpulan data Anda yang aturannya dapat kami tentukan, kami menerapkan aturan tersebut dalam skrip kami. Dengan menjalankan skrip ini kami dapat memastikan integritas kumpulan data Anda.
Katakanlah Anda menarik product_code dari situs e-commerce yang berisi kombinasi alfabet dan empat angka. Dengan menerapkan skrip kita dapat menandai produk yang tidak mengikuti aturan.

Bagian yang disorot di atas adalah anomali dalam kumpulan data kami. Mereka tidak mengikuti aturan. Dalam kasus khusus ini, kumpulan datanya kecil, sehingga kami dapat menemukan lokasi anomali tanpa banyak usaha. Namun semakin besar kumpulan datanya, semakin kompleks jadinya. Akan lebih sulit untuk menyaring keanehan seperti yang kita lakukan di sini.
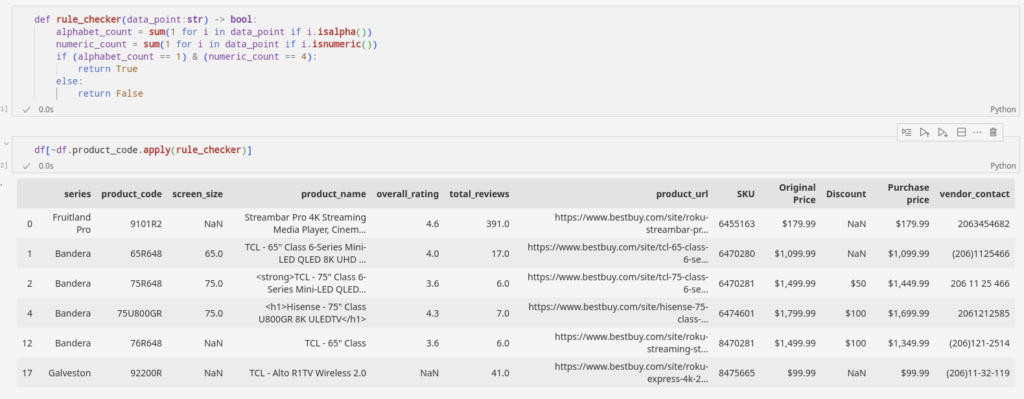
def rule_checker(data_point:str) -> bool:
alphabet_count = sum(1 for i in data_point if i.isalpha())
numeric_count = sum(1 for i in data_point if i.isnumeric())
if (alphabet_count == 1) & (numeric_count == 4):
return True
else:
return False
df(~df.product_code.apply(rule_checker))Alat praktis dengan Python ini dapat membantu kita melakukan pekerjaan berat. Kami dapat memfilter keanehan dari kumpulan data atau memperbarui crawler untuk memperbaiki masalah tersebut.
Identifikasi anomali dalam kumpulan data untuk jaminan kualitas
Sekarang langkah selanjutnya adalah menemukan kemungkinan ketidakberesan dalam kumpulan data kita. Penyimpangan di sini adalah titik data yang tidak sesuai dengan logika titik data kita. Mari kita lihat contoh berikut untuk memahami sepenuhnya inkonsistensi yang dapat terjadi dalam kumpulan data:
1. Bidang data tidak ada
Kemungkinan besar saat pertama kali Anda mengekstrak data, Anda akan menerima kolom data kosong. Kini saatnya tim QA memulai tugasnya.
Setelah menganalisis contoh kumpulan data yang dibuat oleh Black Box melalui analisis statistik komprehensif, mari kita mulai bekerja.
Kumpulan data contoh memperhitungkan semua bidang yang hilang dalam kumpulan data. Berdasarkan hal ini, kami memvalidasi poin yang hilang secara manual. Tapi bukan itu saja. Kami dapat menyesuaikan skrip untuk kasus tertentu dengan memprioritaskan kolom yang penting bagi Anda.
Misalnya, Anda tidak dapat memiliki ruang product_name Data dalam kumpulan data eCommerce. Oleh karena itu, kami menggunakan laporan sampel untuk menemukan variabel yang hilang.
Berikut adalah beberapa kode Python sederhana yang menyaring kelainan. Ini memungkinkan kita untuk memperhitungkan nilai yang hilang dalam kumpulan data. Kami akan membahas detailnya nanti di bagian “Pasca Pemrosesan”.

2. Tes logika
Simpul lain yang mengungkap kita dengan kotak hitam adalah verifikasi logis dari kolom-kolom dalam kumpulan data kita. Untuk pemahaman yang lebih baik, mari kita lihat kolom "Nomor telepon".
Aturan tetap mengenai kode negara dan nomor numerik berlaku untuk bidang data ini. Misalnya, nomor telepon Amerika terdiri dari sepuluh digit angka dan kode area. Setiap kali kami menemukan kolom dengan nomor telepon dan negara, kami mengambil informasi dari database metadata dan menerapkan logika yang sesuai.
Katakanlah kita menentukan, berdasarkan kode area yang tersedia dan melihat sekilas metadatanya, bahwa phone_numerical_count adalah 10. Jika kita melanjutkan informasi ini, kita dapat memisahkan titik data yang tidak mengikuti aturan ini.

phone_numeral_count = 10
df(df.vendor_contact.apply(lambda x: True if sum(1 for i in x if i.isnumeric())!=phone_numeral_count else False))
Ini adalah representasi sederhana tentang bagaimana kami membuat contoh berdasarkan logika bidang yang kami siapkan di skrip. Ada banyak operasi statistik dan logika yang ditulis ke dalam kotak hitam untuk membuat sampel anomali yang komprehensif.
Pasca-pemrosesan jaminan kualitas data
Poin data yang kami peroleh dari sumber web tidak selalu dapat digunakan dengan mudah. Beberapa anomali yang tertanam dapat memengaruhi integritas kumpulan data dan memperlambat pengambilan keputusan.
Dengan jaminan kualitas data pasca-pemrosesan, kami tidak hanya dapat mempertahankan kualitas data yang tinggi, namun juga memastikan pengiriman proyek data lebih cepat. Kami mencapai hal ini dengan mengurangi TAT (Turn Around Time) secara signifikan.
Mari kita lihat beberapa teknik pasca-pemrosesan yang sering digunakan oleh pakar kualitas kami.
1. Tag HTML di kolom teks
Kami sering mengirimkan data mentah yang kami kumpulkan dari Internet melalui berbagai tahap pemrosesan. Jika data mentah diekspos langsung melalui API, kita dapat berasumsi bahwa data tersebut tidak mengandung tag HTML. Namun, situasinya sangat berbeda ketika kita mengekstrak data dengan mengurai dokumen HTML.
Dalam keadaan seperti itu, keberadaan tag HTML dalam kumpulan data menimbulkan masalah besar. Analisis lebih lanjut mungkin rumit karena konten yang tertanam dalam tag HTML.
Tapi jangan khawatir. Anda dapat menerapkan ekspresi reguler di lapangan untuk menyimpan catatan. Di bawah ini cuplikan kode Python untuk menghapus tag HTML dari titik data Anda:
def remove_tags(raw_text):
CLEANR = re.compile('<.*?>')
cleantext = re.sub(CLEANR, '', str(raw_text))
return cleantext
Kumpulan data contoh memperhitungkan data akun yang disematkan dalam tag HTML:

Kami menerapkan itu remove_tags Fungsi untuk kolom yang berisi anomali. Ini menghapus tag HTML dan menghasilkan data bersih sebagai hasilnya.
Di sini kami menerapkan fungsi ini product_name Kolom untuk menghapus tag HTML:
df.product_name = df.product_name.apply(lambda x : remove_tags(x) if pd.notna(x) else np.nan)Ini akan menghapus tag HTML dari semua contoh di kolom, jika ada.

Kita dapat melihat dengan jelas bahwa nama produk dari baris kedua bebas dari tag HTML.
Demikian pula, kami dapat menghapus string, karakter, dan angka apa pun dari bidang data yang ditemukan membahayakan integritas kumpulan data.
2. Imputasi kolom kosong
Sebagian besar kumpulan data berada dalam format kategorikal dan numerik. Seperti yang telah kita bahas di atas, seringkali tidak dapat dihindari untuk mendapatkan field kosong dalam sebuah record.
Kami mengambil langkah khusus ini untuk memvalidasi bidang data yang hilang ketika titik data hilang bahkan dari situs web sumber.
Jika Anda meminta kami untuk memperhitungkan bidang data yang hilang agar kumpulan data dapat dipahami, kami dapat melakukannya.
Misalnya, Anda dapat menetapkan bidang yang hilang dalam data kategorikal dengan menetapkan nilai menggunakan nilai mode atau menggunakan pendekatan regresi.
Sedangkan untuk data numerik, Anda dapat menggunakan alat statistik seperti mean, median, dan regresi linier.
Mari lihat overall_rating kolom untuk kasus ini. Nilai negatif di lapangan dapat mendistorsi nilai imputasi. Oleh karena itu, langkah pertama adalah memastikan bahwa bidang tersebut dapat bernilai negatif. Kita tahu bahwa nilainya tidak boleh negatif dalam kasus ini.
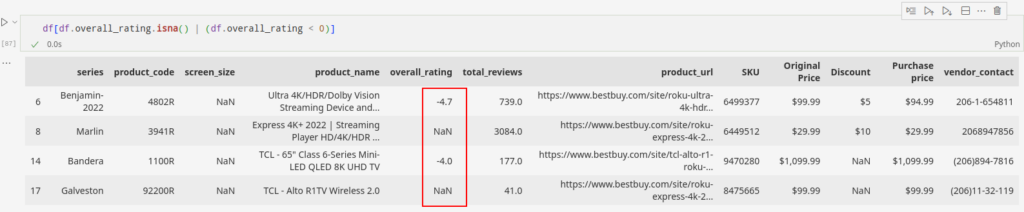
Data berisi nilai negatif dan kosong overall_rating Bidang. Mari simpan indeks bidang ini dan lanjutkan dengan solusinya.
overall_rating_flagged_index = df(df.overall_rating.isna() | (df.overall_rating < 0)).indexKode sederhana di bawah ini memastikan bahwa overall_rating bebas dari entri negatif apa pun.
df.overall_rating = df.overall_rating.abs()Sekarang mari kita ke akuntansi. Mari masukkan nilai median di kolom kolom yang hilang.
df.overall_rating.fillna(df.overall_rating.median(), inplace=True)Setelah menerapkan teknik sederhana ini, kami dapat melihat bahwa kami telah menyimpan informasi lapangan dengan cara terbaik.
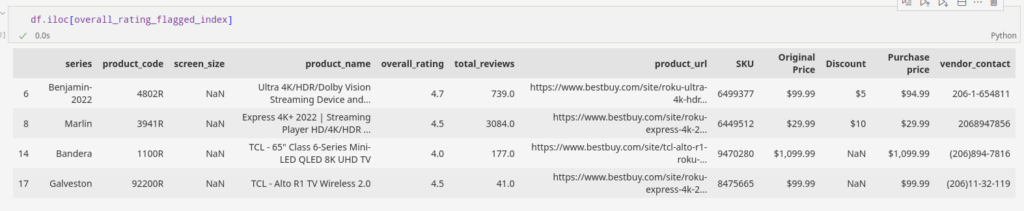
Kita dapat memperhitungkan bidang data yang hilang melalui berbagai teknik univariat dan multivariat. Selain itu, kami kebanyakan menggunakan teknik imputasi tetangga terdekat.
3. Hubungan lintas kolom
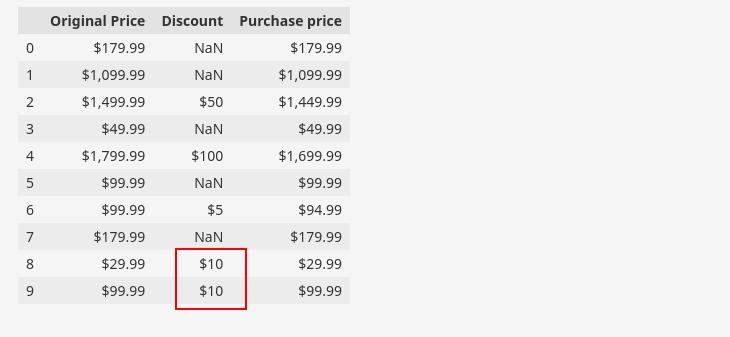
Kita sering menemukan record dengan dua kolom atau lebih yang berhubungan satu sama lain berdasarkan logika field. Secara khusus, dalam contoh data yang diberikan terdapat kolom dengan atribut “Diskon“ dapat diturunkan dari atribut “Harga asli" Dan "Harga pembelian“.
Alternatifnya, kita dapat mengatakan bahwa “Harga pembelianAtribut berasal dari atribut.Harga asli" Dan "Diskon“. Berikut adalah bagian dari kumpulan data kami untuk menunjukkan hubungan di atas.
df(('Original Price', 'Discount', 'Purchase price')).head(10)
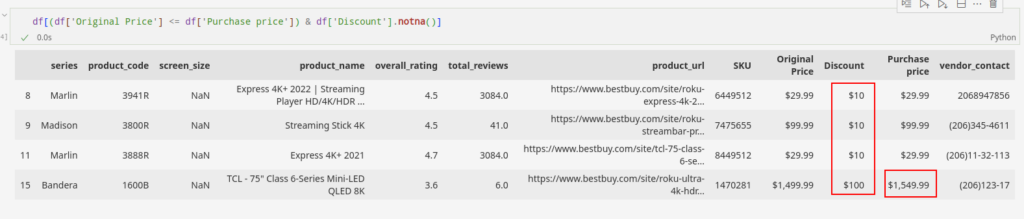
Kami dapat menggunakan hubungan tersebut untuk memverifikasi keakuratan data kami. Pada gambar, kami telah menyoroti contoh yang tidak valid, yang menunjukkan bahwa data menunjukkan bahwa harga beli atau harga diskon tidak valid untuk baris tersebut.
Menggunakan Python untuk jaminan kualitas data
Kita dapat mengidentifikasi baris tersebut menggunakan kode Python seperti yang ditunjukkan di bawah ini:
df((df('Original Price') <= df('Purchase price')) &
df('Discount').notna())
Setelah memeriksa hubungan yang tidak valid tersebut di Internet oleh tim manual kami, kami dapat menentukan apakah diskon, harga pembelian, atau harga asli tidak valid.
Setelah kami mengidentifikasi atribut spesifik yang tidak valid, kami dapat melanjutkan dengan langkah pasca-pemrosesan untuk memastikan validitas instance.
Langkah-langkah pasca-pemrosesan meliputi pencarian data yang benar dan imputasi untuk menggantikan nilai yang tidak valid.
Dalam contoh dataset kita, keberadaan karakter "$" di instance yang tidak kosong menyebabkan instance di kolom Harga Asli, Diskon, dan Harga Pembelian menjadi instance string.
Untuk melakukan perhitungan atau perbandingan dengan nilai-nilai ini, string harus dikonversi ke format numerik dengan menghilangkan simbol mata uang.
df('Original Price') = pd.to_numeric(df('Original Price').str.replace('(^d.)', '', regex=True), errors="coerce")
df('Discount') = pd.to_numeric(df('Discount').str.replace('(^d.)', '', regex=True), errors="coerce")
df('Purchase price') = pd.to_numeric(df('Purchase price').str.replace('(^d.)', '', regex=True), errors="coerce")
Sekarang nilai harga telah diubah menjadi float, kita dapat melanjutkan ke perhitungan lebih lanjut. Berdasarkan pemeriksaan manual terhadap data sampel, kami menganggap diskon dan harga asli adalah valid. Oleh karena itu, kita dapat melakukan penghitungan dan analisis menggunakan nilai-nilai tersebut.
Dengan cara ini Anda dapat menemukan indeks yang memiliki baris yang tidak valid.
index_=list(df((df('Original Price')<=df('Purchase price')) & df('Discount').notna()).index)

Sekarang kita ganti harga beli yang tidak valid dengan harga yang benar, yaitu harga beli = harga asli – diskon.
Kode Python untuk operasi tersebut adalah:
df.loc(index_,'Purchase price')=df.loc(index_,'Original Price') - df.loc(index_,'Discount')Kita dapat memeriksa validitas nilai yang diperbarui dengan memeriksa indeks dari baris yang sebelumnya tidak valid.
df.loc(index_,('Original Price','Discount','Purchase price'))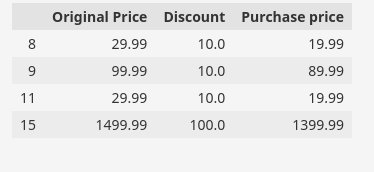
Pengembangan tangkas dalam pengujian kotak hitam QA data
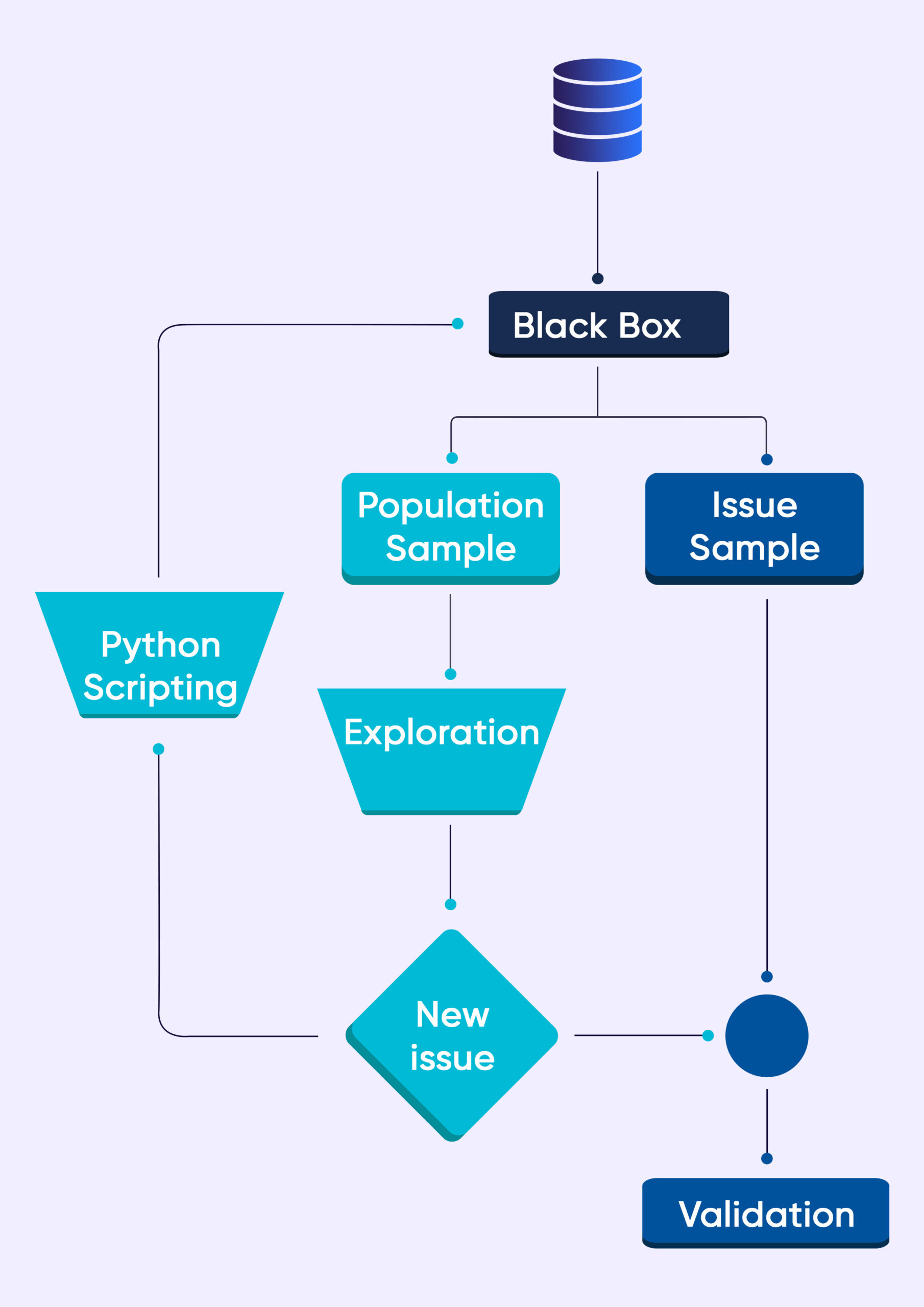
Seperti semua proses lainnya di Grepsr, pengembangan Data QA Black Box dilakukan dengan cara yang tangkas.
Diagram alur di atas menunjukkan prosedur sederhana. Saat kami memasukkan data ke dalam kotak hitam, dua kumpulan data sampel dihasilkan.
Sampel 1 merupakan hasil sampel acak. Contoh 2 terdiri dari data yang membantu kita memeriksa masalah (seperangkat aturan yang telah ditentukan sebelumnya yang sudah ada di kotak hitam bertanggung jawab untuk hal ini).
Pakar QA manual kami meninjau sampel populasi. Ketika kami menemukan masalah yang sebelumnya tidak diketahui, pakar otomatisasi QA kami menulis skrip baru (mekanisme deteksi masalah) yang dimasukkan ke dalam Data QA Black Box.
Lebih baik lagi jika kita tidak menemukan masalah apa pun dalam kumpulan data sampel. Tim QA kami melakukan eksplorasi dan manipulasi data lebih lanjut. Dalam banyak kasus, kami menyampaikan temuan kami kepada teknisi pengiriman.
Para insinyur kemudian meningkatkan crawler untuk memberikan ruang bagi penemuan baru.
Mekanisme Data QA Black Box bekerja dengan kerangka probabilistik yang ketat dan secara cermat memeriksa data yang tercatat untuk mengetahui adanya ketidakseimbangan atau anomali. Kami menggunakan teknik matematika tingkat lanjut untuk mengenali pola probabilistik.
Hal ini memungkinkan kami melakukan penjaminan kualitas yang tepat pada data dalam jumlah besar dan secara radikal meningkatkan TAT (Turn Around Time) kami.
Menyimpulkan
Blog ini hanya menjelaskan sebagian kecil proses dan alat yang kami gunakan untuk menjamin kualitas data.
Pendekatan pengujian black box kami, yang didukung oleh Python dan pustakanya, memungkinkan kami memecahkan masalah kualitas data yang kompleks secara efektif.
Kami dapat menyesuaikan skrip kotak hitam untuk memenuhi persyaratan kualitas data spesifik Anda.
Apapun itu, Anda dapat mengandalkan Grepsr untuk memberikan Anda kualitas data berkualitas tinggi memberikan yang memenuhi tujuan bisnis Anda.
Bacaan Terkait:
