
Langkah 2: Mengirim permintaan dan menganalisis responsnya
Kami membuatnya payload Objek yang berisi kunci API kami dan URL G2 yang ingin kami pindai. Itu payload kemudian digunakan untuk mengirim a get() Minta API scraping kami, yang menangani kompleksitas web scraping seperti IP cerdas dan rotasi header, pemrosesan CAPTCHA, dan banyak lagi menggunakan pembelajaran mesin dan analisis statistik.
payload = {"api_key": API_KEY, "url": url}
html = requests.get("https://api.scraperapi.com", params=payload)
Lalu kita bisa menggunakannya BeautifulSoup untuk mengurai respons HTML dan menyimpannya sebagai soup Objek – sehingga kita dapat menavigasi pohon yang diurai menggunakan pemilih CSS.
soup = BeautifulSoup(html.text, "lxml")
Langkah 3: Ekstrak ulasan perangkat lunak G2
Langkah ini melibatkan inisialisasi kamus untuk menyimpan hasil dan mengekstraksi nama produk, jumlah ulasan, dan data peringkat pengguna dari respons HTML yang diurai.
Kita mulai dengan membuat kamus bernama “Hasil” untuk menyimpan data yang kita ekstrak.
results = {"product_name": "", "number_of_reviews": "", "reviews": ()}
Di Sini, product_name Dan number_of_reviews adalah string yang berisi nama produk atau jumlah total ulasan reviews adalah daftar kamus, masing-masing mewakili satu ulasan.
Setelah kamus kami siap, kami mengekstrak nama produk dari HTML yang diurai.
Kami menggunakan BeautifulSoup select_one() Metode untuk memilih elemen pertama yang cocok dengan pemilih CSS .product-head__title a. Kami kemudian mendapatkan teks elemen ini dan menetapkannya results('product_name').
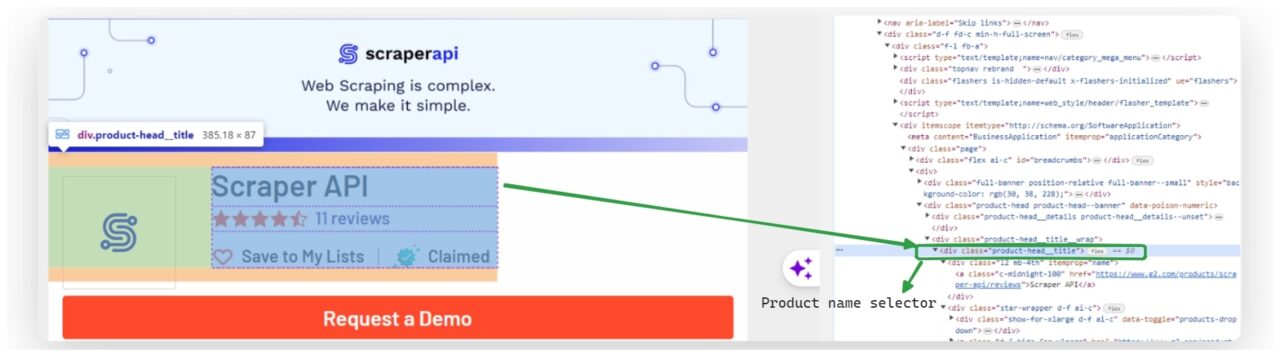
product_name_element = soup.select_one(".product-head__title a")
results("product_name") = product_name_element.get_text(strip=True) if product_name_element else "Product name not found"
Demikian pula, kami mengekstrak jumlah ulasan dengan memilih elemen menggunakan pemilih CSS li.list--piped__li dan dapatkan pesannya.

reviews_element = soup.find("li", {"class": "list--piped__li"})
results("number_of_reviews") = reviews_element.get_text(strip=True) if reviews_element else "Number of reviews not found"
Lalu kami memeriksa semua ulasan di situs. Setiap ulasan dipilih menggunakan pemilih .paper.paper--white.paper--box. Kami mengekstraknya Nama belakang, Ringkasan, ulasan lengkap, Tanggal, URLDan Evaluasi Untuk setiap ulasan, Anda kemudian menyimpan informasi ini dalam kamus baru yang diberi nama review_data.
Mengekstrak nama pengguna
Nama pengguna biasanya ada di jangkar (a) Label. Untuk mengekstraknya, kita mencari tag jangkar dengan kelas yang menunjukkan bahwa itu berisi nama pengguna.
Misalnya saja nama kelasnya adalah link--header-colormari kita gunakan BeautifulSoup untuk menemukannya a sorot dan kemudian ambil konten teks.

username_element = review.find("a", {"class": "link--header-color"})
review_data("username") = username_element.get_text(strip=True) if username_element else "No username found"
Mengekstrak ringkasan ulasan
Anda dapat menemukan ringkasan ulasannya di salah satunya h3 Menuju dengan kelas m-0 l2.
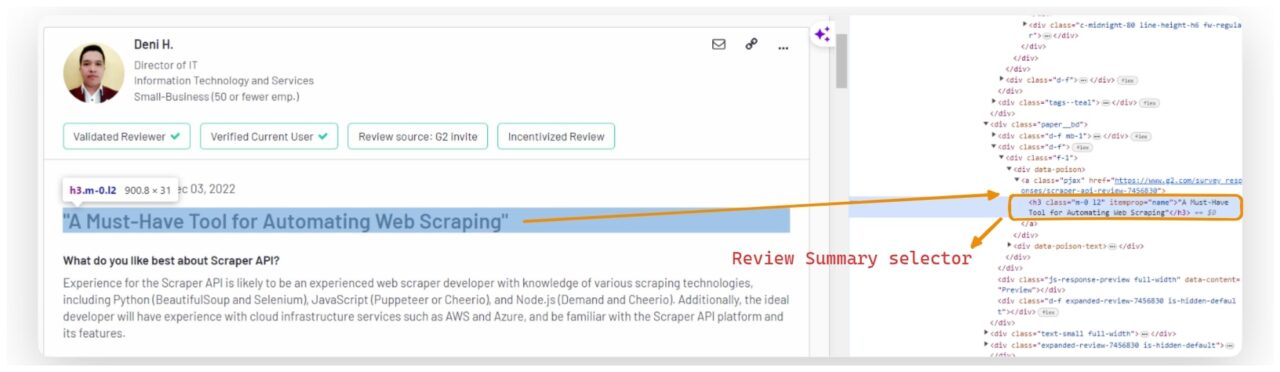
summary_element = review.find("h3", {"class": "m-0 l2"})
review_data("summary") = summary_element.get_text(strip=True).replace('"', "") if summary_element else "No summary found"
Mengekstrak teks ulasan
Teks lengkap ulasan biasanya disertakan dalam satu ulasan div dengan itemprop Atribut disetel ke reviewBody. Untuk mengekstrak teks ulasan, kami menemukan ini div dan mengambil konten teks.
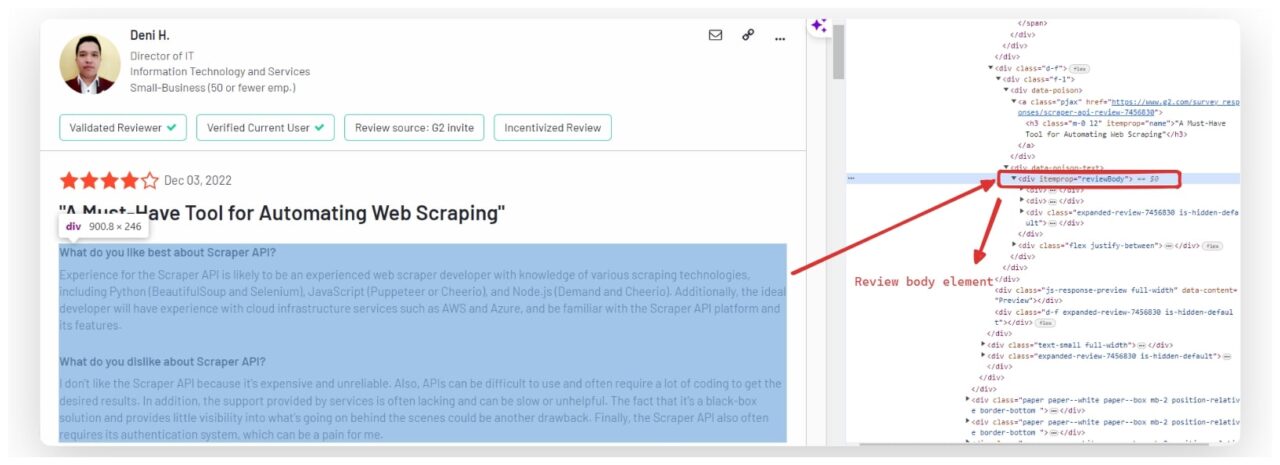
user_review_element = review.find("div", itemprop="reviewBody")
review_data("review") = user_review_element.get_text(strip=True) if user_review_element else "No review found"
Mengekstrak tanggal peninjauan
Tanggal peninjauan sering kali berada dalam a time Elemen.
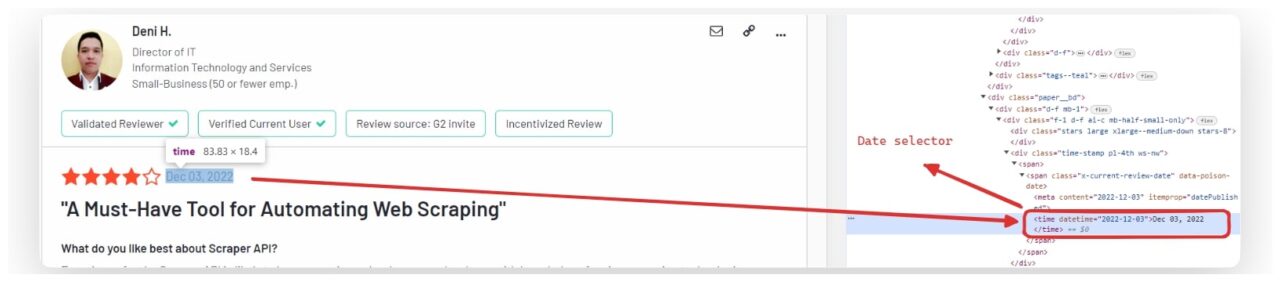
review_date_element = review.find("time")
review_data("date") = review_date_element.get_text(strip=True) if review_date_element else "No date found"
Ekstrak URL ulasan
Untuk mengekstrak URL setiap ulasan, kami mencari tag jangkar yang berisi berikut ini href Atribut. Secara khusus, itulah yang kami minati a Tag dengan kelas pjaxkarena ini adalah kelas yang digunakan G2 untuk tautan ke setiap ulasan.
Inilah cara kami memasukkan ini ke dalam proses ekstraksi kami:
review_url_element = review.find("a", {"class": "pjax"})
review_data("url") = review_url_element("href") if review_url_element else "No URL found"
Mengekstraksi peringkat
Ulasan dapat ditemukan dalam a meta Tandai dengan atribut itemprop mengatur ratingValue. Kami mencari tag ini dan mengekstraknya content Atribut untuk mendapatkan nilai rating.
rating_element = review.find("meta", itemprop="ratingValue")
review_data("rating") = rating_element("content") if rating_element else "No rating found"
Setiap bagian data kemudian disimpan dalam kamus yang disebut review_data. Setelah kami mengekstrak data untuk setiap ulasan, kami menambahkannya review_data Ke results('reviews').
results("reviews").append(review_data)
Di akhir langkah ini, hasilnya adalah kamus yang berisi nama produk, jumlah review, dan daftar kamus yang masing-masing mewakili satu review.
