
Sekarang setelah Anda memiliki akun ScraperAPI, mari mulai berbisnis!!
Langkah 1: Impor perpustakaan Anda
Agar ini berfungsi, Anda perlu mengimpor perpustakaan Python yang diperlukan json, requestDan BeautifulSoup.
import json
from datetime import datetime
import requests
from bs4 import BeautifulSoup
Selanjutnya, buat variabel untuk menyimpan kunci API Anda
scraper_api_key = 'ENTER KEY HERE'
Langkah 2: Dapatkan postingan Reddit
Mari kita mulai dengan menambahkan URL asli kita ke reddit_query dan kemudian membangun milik kita get() Permintaan melalui titik akhir default ScraperAPI.
reddit_query = f"https://www.reddit.com/t/valheim/"
scraper_api_url = f'http://api.scraperapi.com/?api_key={scraper_api_key}&url={reddit_query}'
r = requests.get(scraper_api_url)
Selanjutnya, mari kita menganalisis kode HTML Reddit (dengan BeautifulSoup), sebuah... Membuat soup Objek yang sekarang dapat kita gunakan untuk memilih elemen tertentu pada halaman:
soup = BeautifulSoup(r.content, 'html.parser')
articles = soup.find_all('article', class_='m-0')
Secara khusus, kami mencari semua orang article Elemen dengan kelas CSS m-0 Penggunaan find_all() Metode. Daftar item yang dihasilkan ditugaskan ke variabel articles yang berisi setiap kontribusi.
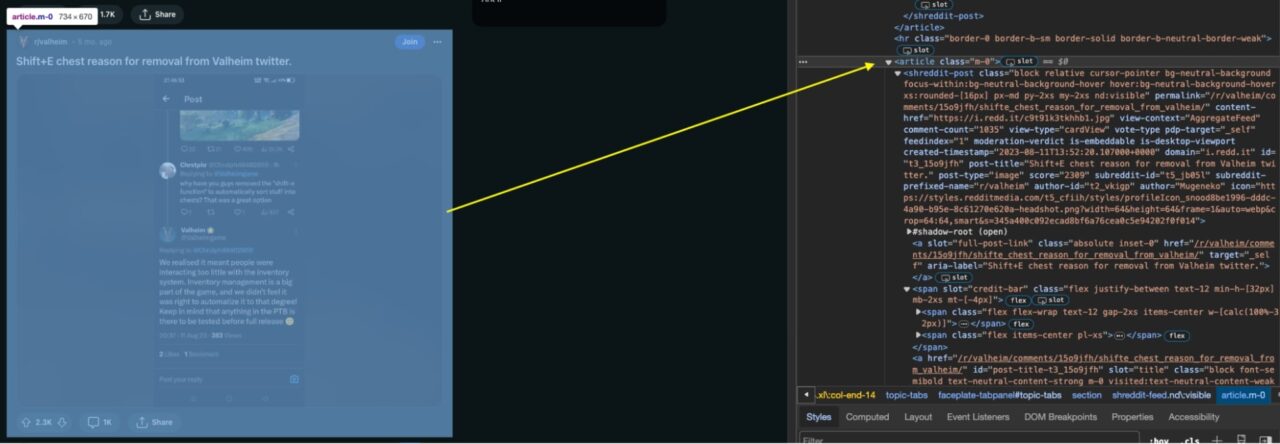
Langkah 3: Ekstrak Informasi Posting Reddit
Sekarang setelah Anda menghapusnya article Elemen yang berisi setiap postingan subreddit di halaman Reddit, sekarang saatnya mengekstrak setiap postingan beserta informasinya dari dalamnya
# Initialize a list to store parsed posts
parsed_posts = ()
for article in articles:
post = article.find('shreddit-post')
# Extract post details
post_title = post('post-title')
post_permalink = post('permalink')
content_href = post('content-href')
comment_count = post('comment-count')
score = post('score')
author_id = post.get('author-id', 'N/A')
author_name = post('author')
# Extract subreddit details
subreddit_id = post('subreddit-id')
post_id = post("id")
subreddit_name = post('subreddit-prefixed-name')
# Append the parsed post to the list
parsed_posts.append({
'post_title': post_title,
'post_permalink': post_permalink,
'content_href': content_href,
'comment_count': comment_count,
'score': score,
'author_id': author_id,
'author_name': author_name,
'subreddit_id': subreddit_id,
'post_id': post_id,
'subreddit_name': subreddit_name
})
Pada kode di atas, Anda mengidentifikasi postingan individual dengan mencari elemen dengan kelasnya shreddit-post. Untuk setiap postingan ini, Anda kemudian mengekstrak detail seperti:
- judul
- tautan permanen
- Tautan konten
- Jumlah komentar
- skor
- ID Penulis
- Nama penulis
Dengan mengacu pada elemen HTML tertentu yang terkait dengan setiap informasi.
Selain itu, ketika menangani detail postingan subreddit, kodenya juga menggunakan elemen seperti shreddit-id, idDan subreddit-prefixed-name untuk mengumpulkan informasi yang relevan.
Pada dasarnya, kode tersebut secara terprogram menavigasi struktur HTML postingan Reddit, mengumpulkan detail penting untuk setiap postingan dan menyimpannya dalam daftar untuk digunakan atau dianalisis lebih lanjut.
Langkah 4: Ambil komentar postingan Reddit
Untuk mengekstrak komentar dari postingan, Anda harus mengirimkan permintaan ke ScraperAPI atau berisiko diblokir oleh mekanisme anti-scraping Reddit.
Mari kita buat yang pertama fetch_comments_from_post() Berfungsi untuk mengirim request ke ScraperAPI dengan API KEY anda (jangan lupa ganti YOUR_SCRAPER_API_KEY dengan API KEY Anda yang sebenarnya) dan URL posting.
def fetch_comments_from_post(post_data):
payload = { 'api_key': 'YOUR_SCRAPER_API_KEY', 'url': 'https://www.reddit.com//r/valheim/comments/15o9jfh/shifte_chest_reason_for_removal_from_valheim/' }
r = requests.get('https://api.scraperapi.com/', params=payload)
soup = BeautifulSoup(r.content, 'html.parser')
Permintaan ini kemudian diteruskan ke BeautifulSoup untuk dianalisis.
Kemudian kita dapat mengidentifikasi semua komentar di subReddit dengan mencari div Unsur yang mempunyai a data-type Atribut disetel ke comment.
# Find all comment elements
comment_elements = soup.find_all('div', class_='thing', attrs={'data-type': 'comment'})
Setelah Anda menemukan komentar, saatnya mengekstraknya.
# Initialize a list to store parsed comments
parsed_comments = ()
for comment_element in comment_elements:
try:
# Extract relevant information from the comment element, handling potential NoneType errors
author = comment_element.find('a', class_='author').text.strip() if comment_element.find('a', class_='author') else None
dislikes = comment_element.find('span', class_='score dislikes').text.strip() if comment_element.find('span', class_='score dislikes') else None
unvoted = comment_element.find('span', class_='score unvoted').text.strip() if comment_element.find('span', class_='score unvoted') else None
likes = comment_element.find('span', class_='score likes').text.strip() if comment_element.find('span', class_='score likes') else None
timestamp = comment_element.find('time')('datetime') if comment_element.find('time') else None
text = comment_element.find('div', class_='md').find('p').text.strip() if comment_element.find('div', class_='md') else None
# Skip comments with missing text
if not text:
continue # Skip to the next comment in the loop
# Append the parsed comment to the list
parsed_comments.append({
'author': author,
'dislikes': dislikes,
'unvoted': unvoted,
'likes': likes,
'timestamp': timestamp,
'text': text
})
except Exception as e:
print(f"Error parsing comment: {e}")
return parsed_comments
Dalam kode di atas kita memanggil parsed_comments Daftar untuk menyimpan informasi yang diekstraksi. Kode kemudian melewati masing-masing kode comment_element dalam koleksi comment Elemen.
Di dalam loop yang kami gunakan find() untuk mengekstrak detail yang relevan dari setiap komentar, seperti:
- Nama penulis
- Tidak suka
- Menghitung tanpa memilih
- Suka
- cap waktu
- Isi teks komentar
Untuk menangani kasus-kasus di mana beberapa informasi mungkin hilang (mengakibatkan NoneType kesalahan), kami menggunakan pernyataan kondisional. Jika sebuah komentar tidak memiliki konten teks, komentar tersebut akan dilewati dan perulangan berlanjut ke komentar berikutnya. Ini menghemat waktu kita dan menghentikannya NoneType Kesalahan.
Data yang diekstraksi kemudian disusun dan ditambahkan ke kamus untuk setiap komentar parsed_comments Daftar.
Setiap kesalahan yang terjadi selama proses analisis ditangkap dan dicetak.
Terakhir, daftar komentar yang dianalisis dikembalikan, memberikan representasi terstruktur dari informasi komentar penting untuk digunakan atau dianalisis lebih lanjut.
Setelah komentar diekstraksi untuk setiap postingan subreddit, Anda dapat menyimpan komentar tersebut ke postingan pertama parsed_post data dengan menambahkan kode berikut.
comments = fetch_comments_from_post(post)
Langkah 5: Konversikan ke JSON
Sekarang setelah Anda mengekstrak semua data yang diperlukan, saatnya menyimpannya ke file JSON agar lebih mudah digunakan.
# Save the parsed posts to a JSON file
output_file_path = 'parsed_posts.json'
with open(output_file_path, 'w', encoding='utf-8') as json_file:
json.dump(parsed_posts, json_file, ensure_ascii=False, indent=2)
print(f"Data has been saved to {output_file_path}")
Itu output_file_path Variabel diatur ke nama file diurai_posts.json. Kode kemudian membuka file ini dalam mode tulis ('w') dan menggunakan json.dump() Berfungsi untuk menulis isi parsed_posts daftar ke dalam file dalam format JSON.
Itu ensure_ascii=False Argumen tersebut memastikan bahwa karakter non-ASCII diproses dengan benar indent=2 Menambahkan lekukan agar mudah dibaca di file JSON.
Setelah menulis data, sebuah pesan dicetak ke konsol yang menunjukkan bahwa data berhasil disimpan ke file JSON yang ditentukan (diurai_posts.json).
Menguji pengikis
Menguji scraper ini cukup sederhana: Anda cukup menjalankan kode Python dan semua postingan data dan komentar di subreddit yang disediakan akan dihapus dan diubah menjadi file JSON bernama diurai_post.json.
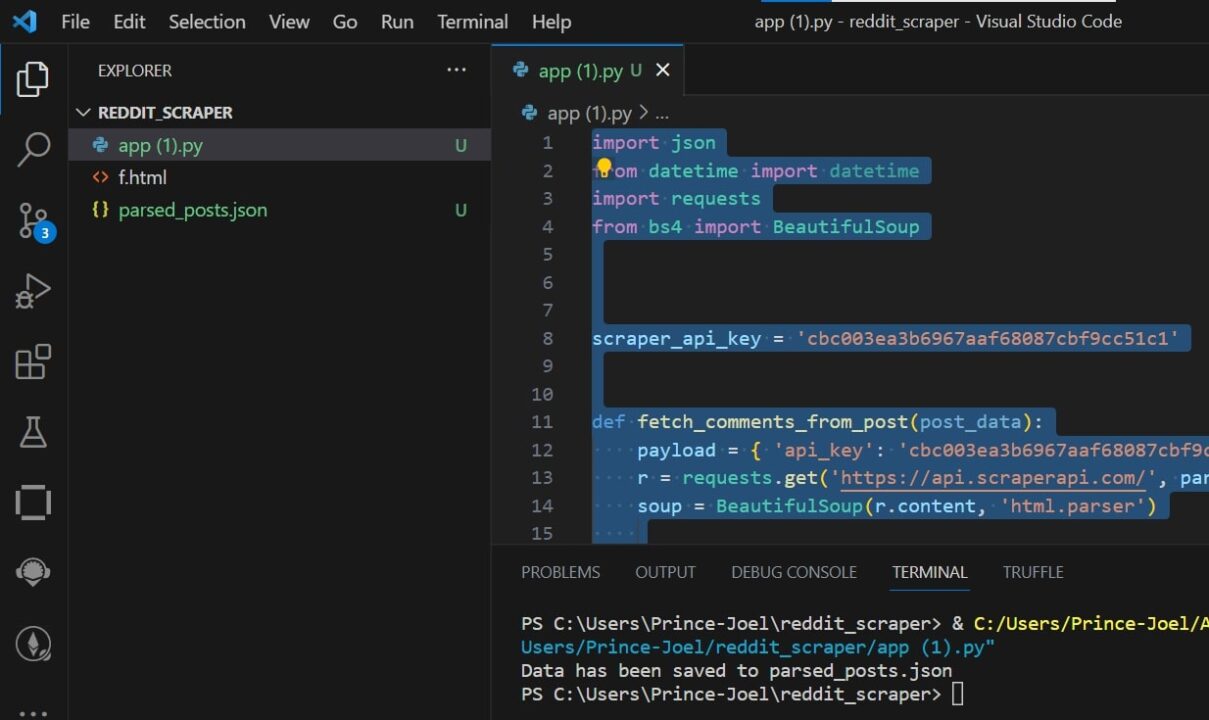
Selamat, Anda telah berhasil mengambil data dari Reddit dan dapat menggunakan data tersebut sesuai keinginan!
Ringkasan
Tutorial ini memperkenalkan pendekatan langkah demi langkah untuk mengambil data dari Reddit dan menunjukkan cara melakukannya
- Kumpulkan 25 postingan terbaru di subreddit
- Telusuri semua postingan untuk mengumpulkan komentar
- Kirimkan permintaan Anda melalui ScraperAPI untuk menghindari penangguhan
- Ekspor semua data yang diekstraksi ke file JSON terstruktur
Saat kami mengakhiri perjalanan penuh wawasan ini ke dalam dunia scraping Reddit, kami harap Anda mendapatkan wawasan berharga tentang kekuatan Python dan ScraperAPI dalam membuka kekayaan informasi Reddit.
Tetaplah penasaran dan ingat: Dengan keterampilan menggores yang hebat, ada tanggung jawab yang besar.
Sampai jumpa lagi, selamat menggores!
