
LinkedIn, situs jejaring sosial profesional terbesar di dunia dengan 1 miliar anggota di lebih dari 200 negara dan wilayah di seluruh dunia. Ini adalah sumber daya yang berharga bagi bisnis dan individu karena menyediakan platform untuk membangun jaringan, mencari pekerjaan, dan belajar tentang industri baru.
Dalam artikel ini, kita akan melihat pengumpulan data LinkedIn dan menjelajahi metode dan alat untuk mengekstrak informasi berharga ini. Kami memberikan petunjuk langkah demi langkah dan alat siap pakai di Google Colaboratory yang memungkinkan Anda memanfaatkan kekuatan data LinkedIn untuk kebutuhan spesifik Anda.
Struktur LinkedIn dan objek data
Seperti disebutkan sebelumnya, LinkedIn adalah platform jaringan profesional tempat individu dapat membuat profil yang menunjukkan keahlian, pengalaman, dan pencapaian profesional mereka. Ini banyak digunakan oleh pencari kerja, perekrut, dan profesional yang ingin terhubung dengan orang lain di bidangnya.
Sebelum kita menyelami proses pengumpulan data, mari kita lihat lebih dekat LinkedIn dan identifikasi informasi yang dapat kita ekstrak. Berikut beberapa poin data penting yang tersedia di LinkedIn:
- Profil pengguna: Profil ini memberikan informasi lengkap tentang pengguna, termasuk nama, lokasi, pengalaman kerja saat ini dan sebelumnya, latar belakang pendidikan, keterampilan, dan rekomendasi.
- Tawaran pekerjaan: Fitur pencarian kerja LinkedIn menawarkan filter lanjutan untuk mempersempit hasil ke posisi paling relevan. Data yang dapat diambil dari lowongan pekerjaan mencakup detail perusahaan, lokasi, deskripsi pekerjaan, dan persyaratan kandidat tertentu.
- Pembelajaran LinkedIn: Platform ini menawarkan banyak kursus online dan tutorial video. Data yang dapat diekstraksi mencakup judul kursus, deskripsi, instruktur, dan tautan ke materi kursus.
- artikel LinkedIn: Bagian Artikel Umum berisi artikel yang ditulis oleh pengguna dan pakar, dikategorikan berdasarkan topik atau penulis. Ekstraksi data dapat menangkap judul artikel, penulis, ringkasan konten, dan tanggal publikasi.
Mengikis berbagai elemen platform memberikan akses cepat ke data berharga tentang pengguna dan perusahaan. Data pengguna dapat membantu mengidentifikasi profesional yang berkualifikasi dan berpengalaman untuk tujuan perekrutan, dan data perusahaan dapat membantu menemukan calon pelanggan, mitra, atau peluang kerja di masa depan.
Jenis pencakar LinkedIn
Sebelum mengumpulkan data, penting untuk menentukan metode pengumpulan data yang tepat. Berdasarkan pendekatan yang dipilih, ada dua jenis utama LinkedIn scraper:
- Pencakar LinkedIn berbasis proxy. Pencakar ini menggunakan kumpulan proksi untuk menutupi alamat IP Anda dan mencegah deteksi oleh LinkedIn. Metode ini memungkinkan ekstraksi data skala besar tanpa risiko penangguhan akun. Namun, akses ke data tertentu mungkin tidak dapat dilakukan karena pembatasan LinkedIn.
- Pencakar LinkedIn berbasis cookie. Pencakar ini menggunakan cookie sesi LinkedIn Anda yang ada untuk meniru aktivitas penjelajahan Anda. Metode ini menyediakan pengumpulan data yang ditargetkan dan akses ke informasi yang dipersonalisasi. Namun, hal ini bergantung pada akun Anda, yang dapat mengakibatkan penangguhan akun jika LinkedIn mendeteksi aktivitas mencurigakan.
Pada artikel ini, kita akan membahas lebih detail tentang setiap metode dan memberikan contoh kode untuk mendemonstrasikan penerapannya. Kami juga mendiskusikan manfaat dan keterbatasan setiap pendekatan untuk membantu Anda memilih pendekatan yang paling sesuai dengan kebutuhan pengikisan spesifik Anda.
persyaratan
Untuk menggunakan contoh dalam artikel ini, Anda memerlukan Python 3.10 atau lebih baru, tidak termasuk akun LinkedIn. IDE Python direkomendasikan untuk pengalaman yang efisien, tetapi editor kode apa pun dengan penyorotan sintaksis dan Python yang diinstal dapat digunakan.
Lingkungan virtual bersifat opsional jika Anda tidak ingin meningkatkan keamanan scraping Anda. Kami telah membahas cara mengatur dan menggunakannya di artikel scraping Python.
Pada artikel ini kita akan menggunakan beberapa perpustakaan. Instal menggunakan manajer paket:
pip install beautifulsoup4 requests selenium requests_oauthlib jsonAnda mungkin juga memerlukan driver web untuk menggunakan Selenium. Artikel tentang pengikisan selenium memberikan petunjuk tentang di mana menemukan dan menggunakannya.
Mari jelajahi berbagai metode untuk mengekstrak data dari LinkedIn. Terlepas dari metode yang dipilih, proses pengikisan tetap sama kecuali untuk penggunaan API LinkedIn. Perbedaannya hanya pada skrip asli untuk mendapatkan kode sumber halaman.
Menggunakan API LinkedIn
Seperti banyak platform data besar lainnya, LinkedIn menawarkan API untuk akses data. Namun metode ini mempunyai kelebihan dan kekurangan.
Misalnya, menggunakan LinkedIn menjamin akses mudah dan cepat ke semua data yang Anda perlukan dalam format yang nyaman. Namun, bekerja dengan LinkedIn API bisa jadi lebih sulit dari perkiraan awal. Rintangan pertama adalah menyiapkan server untuk menghasilkan token, yang bisa menjadi sangat rumit tanpa keahlian yang diperlukan.
Selain itu, LinkedIn menetapkan batas permintaan harian untuk panggilan API. Hal ini dapat menyebabkan masalah skalabilitas pada aplikasi yang sering mengakses API.
Mengenai data yang dapat diakses melalui API, tidak semua data LinkedIn dapat diekstraksi melalui API. Misalnya, akses ke daftar tawaran pekerjaan yang tersedia tidak diizinkan. Selain itu, sebagai pengembang individu, Anda harus menentukan perusahaan pengujian saat membuat aplikasi, dan penggunaan perusahaan tersebut membatasi akses ke titik akhir tertentu.
Jika Anda masih memutuskan untuk mencoba metode ini, buka halaman pengembang dan buat aplikasi Anda. Untuk mendapatkan kunci yang diperlukan, Anda harus mengisi formulir. Kemudian di bagian “Auth” Anda akan menemukan “ID Klien” pribadi Anda dan “Rahasia Klien” Anda.
Buat proyek Python baru, impor perpustakaan yang diperlukan dan masukkan kredensial yang diperoleh:
from requests_oauthlib import OAuth2Session
cl_id = 'PUT-YOUR-CLIENT-ID'
cl_secret="PUT-YOUR-CLIENT-SECRET"Kemudian kami membuat variabel untuk menyimpan tautan yang diperlukan untuk mendapatkan token dan otorisasi:
redirect_url="http://localhost:8080/callback"
base_url="https://www.linkedin.com/oauth/v2/authorization"
token_url="https://www.linkedin.com/oauth/v2/accessToken"Buka sesi:
linkedin = OAuth2Session(cl_id, redirect_uri=redirect_url)Hasilkan tautan otorisasi dan tampilkan di layar:
authorization_url, state = linkedin.authorization_url(base_url)
print('Go to:', authorization_url)Selanjutnya, Anda perlu mengikuti tautan di browser Anda secara manual. Alternatifnya, Anda dapat mengintegrasikan Selenium untuk mengotomatiskan proses pengambilan token. Setelah Anda memiliki token, kembalikan tautan lengkap ke skrip:
response = input('Put full URL: ')Kemudian dapatkan tokennya:
linkedin.fetch_token(token_url, client_secret=cl_secret, authorization_response=response)Dengan token yang Anda terima, kini Anda dapat mengakses data yang Anda perlukan melalui API LinkedIn. Dokumentasi API LinkedIn yang komprehensif memberikan informasi mendetail tentang berbagai titik akhir yang tersedia.
Menggunakan Permintaan dan BeautifulSoup
Cara lain untuk mendapatkan data adalah dengan menggunakan perpustakaan permintaan reguler dan proxy atau cookie. Seperti yang kami sebutkan sebelumnya, selama LinkedIn tidak menganggap aktivitas Anda mencurigakan, Anda dapat mengakses data apa pun yang tersedia untuk umum tanpa izin. Namun, dalam kasus ini, risiko penyumbatannya tinggi.
Di sisi lain, Anda dapat terus mengubah proxy untuk menghindari pemblokiran alamat IP asli Anda. Atau Anda dapat menggunakan cookie dan header asli untuk membuat permintaan Anda tidak terlalu mencurigakan. Mari pertimbangkan kedua opsi tersebut dan mulai menggunakan proxy.
Kami telah menulis secara rinci tentang penggunaan proxy dengan perpustakaan Permintaan dengan Python, jadi kami tidak akan membahasnya secara rinci dan memberi Anda contoh siap pakai untuk mengeksekusi permintaan menggunakan proxy:
import requests
url ="https://www.linkedin.com/jobs/search?position=1&pageNum=0"
proxies = {
'http': 'http://45.95.147.106:8080',
'https': 'https://37.187.17.89:3128'
}
response = requests.get(url, proxies=proxies)Anda dapat mengatur sendiri rotasi proxy atau menggunakan server proxy. Untuk daftar penyedia proxy yang andal, lihat 10 Penyedia Proxy Perumahan Teratas kami.
Jika Anda ingin menggunakan cookie Anda yang sebenarnya, buka halaman LinkedIn, masuk dan buka DevTools (F12 atau klik kanan dan periksa). Lalu buka tab Jaringan dan temukan bidang yang Anda inginkan:
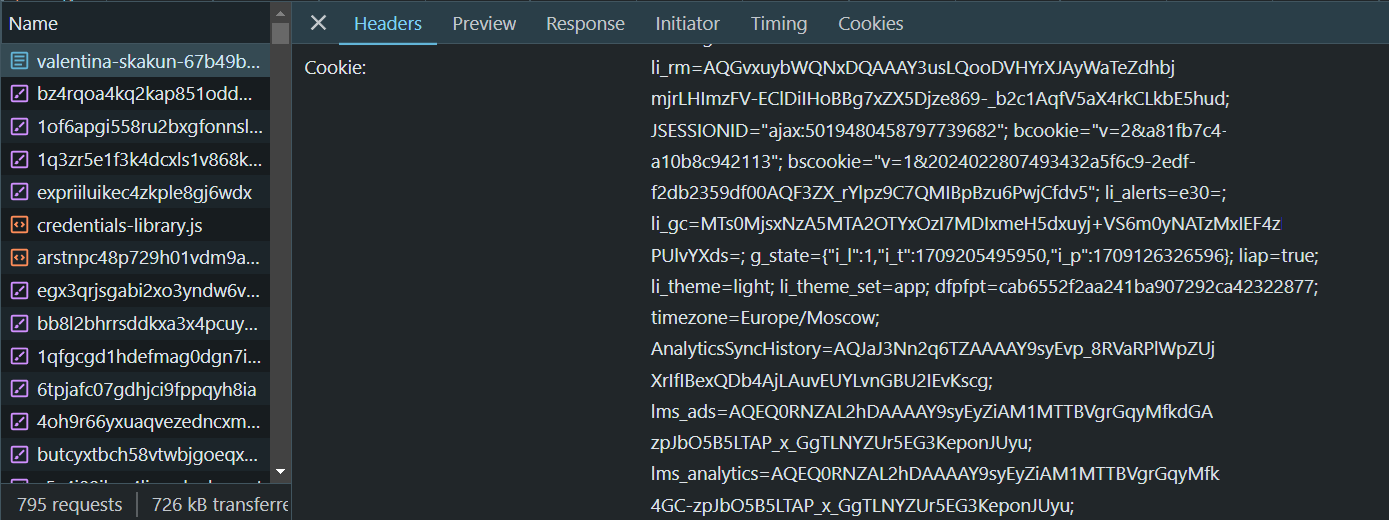
Selain header di atas, Anda harus menyertakan beberapa header lain termasuk string agen pengguna yang valid. Anda dapat menggunakan contoh kami, tetapi Anda harus mengganti nilai placeholder dengan cookie Anda dan string agen pengguna terbaru sebelum menggunakannya.
cookies = "YOUR-COOKIES"
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'Connection':'keep-alive',
'accept-encoding': 'gzip, deflate, br',
'Referer':'http://www.linkedin.com/',
'accept-language': 'en-US,en;q=0.9',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36',
'Cookie': cookies
}Saat membuat permintaan, pastikan untuk menyertakan header berikut:
response = requests.get(url, headers=headers)Anda bebas memilih salah satu opsi yang dipertimbangkan karena keduanya akan memberikan data yang diperlukan.
Menggunakan Profil di Selenium
Pilihan lainnya adalah menggunakan profil Selenium. Anda dapat menggunakan profil browser yang ada tempat Anda masuk ke LinkedIn atau membuat profil baru dan mengotomatiskan proses login menggunakan fitur perpustakaan Selenium.
Anda juga dapat dengan mudah masuk dengan Selenium tanpa menggunakan profil. Namun, dalam hal ini Anda harus melakukan ini setiap kali menjalankan skrip Anda.
Oleh karena itu, lebih mudah untuk masuk ke profil tertentu satu kali dan kemudian mengumpulkan data. Dalam hal ini, otorisasi disimpan setelah skrip dimulai ulang. Selain itu, Anda dapat masuk ke akun Anda secara manual melalui Google dan kemudian menggunakan profil dengan otorisasi selesai.
Untuk melakukan ini, impor perpustakaan:
from selenium import webdriverTentukan jalur profil dan atur opsi driver web:
profile_path = r'C:\Users\Admin\AppData\Local\Google\Chrome\User Data\Profile 1'
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument(f'--user-data-dir={profile_path}')Setelah perpustakaan yang diperlukan diimpor dan driver browser diinisialisasi, Anda dapat membuat objek WebDriver:
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://www.linkedin.com/jobs/search?position=1&pageNum=0')Opsi ini cocok jika Anda ingin menggunakan profil yang sudah Anda masuki di LinkedIn. Jika Anda ingin masuk melalui skrip, Anda harus pergi ke halaman lain:
driver.get("https://linkedin.com/uas/login")Untuk memasukkan nama pengguna dan kata sandi, kami mengidentifikasi kolom input:
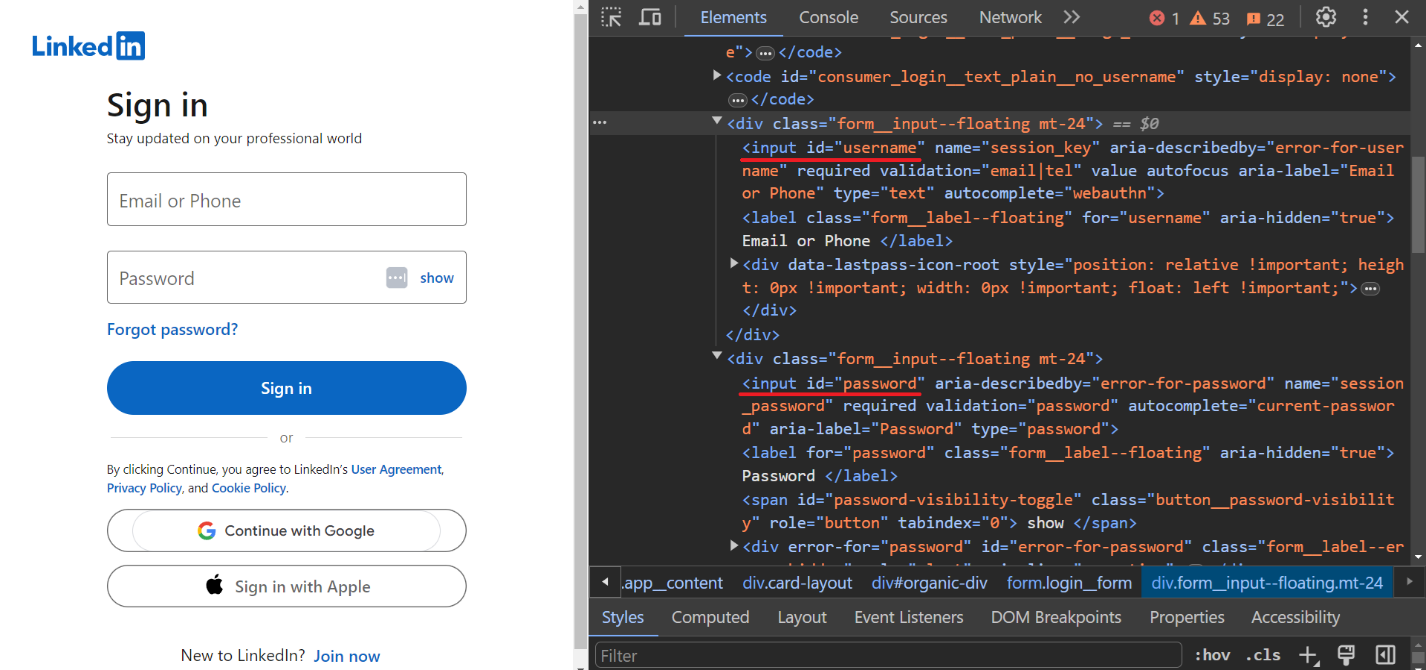
Masukkan kredensial login dan kata sandi pengguna:
username = driver.find_element(By.ID, "username")
username.send_keys("PUT-YOUR-LOGIN")
password = driver.find_element(By.ID, "password")
password.send_keys("PUT-YOUR-PASSWORD") Konfirmasikan datanya:
driver.find_element(By.XPATH, "//button(@type="submit")").click()Otorisasi ini akan disimpan di profil Anda saat ini dan Anda dapat mengikisnya tanpa langkah ini.
Gunakan API Pengikisan Web
Cara termudah dan teraman untuk mengekstrak data dari LinkedIn adalah dengan menggunakan API web scraping. Ini menangkap data yang diperlukan dan hanya memberikan hasil akhir. Hal ini memungkinkan Anda menghindari penggunaan proxy dan kekhawatiran tentang masalah pemblokiran, karena permintaan ke LinkedIn dibuat di sisi layanan API, bukan di sisi klien.
Mari kita pertimbangkan opsi ini menggunakan web scraping API HasData sebagai contoh. Untuk menggunakannya, masuk ke situs web kami dan salin kunci API pribadi Anda, yang dapat Anda temukan di akun Anda.
Selanjutnya, kita membuat proyek baru dan mengimpor perpustakaan yang diperlukan:
import requests
import jsonBerikan tautan ke postingan pekerjaan dan kunci API yang baru saja disalin:
ln_url = "https://www.linkedin.com/jobs/search?position=1&pageNum=0"
api_key = "PUT-YOUR-API-KEY"Tentukan titik akhir API dan parameter permintaan, termasuk jenis proksi yang akan digunakan:
url = "https://api.hasdata.com/scrape/web"
payload = json.dumps({
"url": ln_url,
"proxyCountry": "US",
"proxyType": "datacenter",
"blockResources": True,
"blockAds": True,
"screenshot": True,
"jsRendering": True,
"extractEmails": True
})
headers = {
'Content-Type': 'application/json',
'x-api-key': api_key
}Buat permintaan:
response = requests.request("POST", url, headers=headers, data=payload)Hasilnya, API pengikisan web HasData mengembalikan semua data, termasuk header, konten, dan tangkapan layar halaman.
Mengikis data dari LinkedIn
Mari jelajahi proses menyalin berbagai halaman LinkedIn dengan contoh. Pendekatan umumnya tetap sama, kecuali untuk URL halaman dan strukturnya.
Kami menggunakan API pengikisan web HasData untuk mengambil halaman, menghilangkan kebutuhan akan proxy dan menghindari masalah pemblokiran. Selain itu, kami menggunakan perpustakaan BeautifulSoup untuk menganalisis kode halaman yang diekstraksi. Anda dapat menggunakan salah satu metode yang telah dibahas sebelumnya untuk mendapatkan kode HTML halaman. Namun langkah pemrosesan dan analisisnya tetap sama.
Mengikis postingan pekerjaan LinkedIn
Mari kita mulai dengan mengekstraksi data dari lowongan pekerjaan. Anda dapat menemukan skrip scraper yang sudah jadi di Google Colaboratory. Mari kita masuk ke halaman pencarian kerja dan melihat data apa saja yang bisa kita ekstrak.
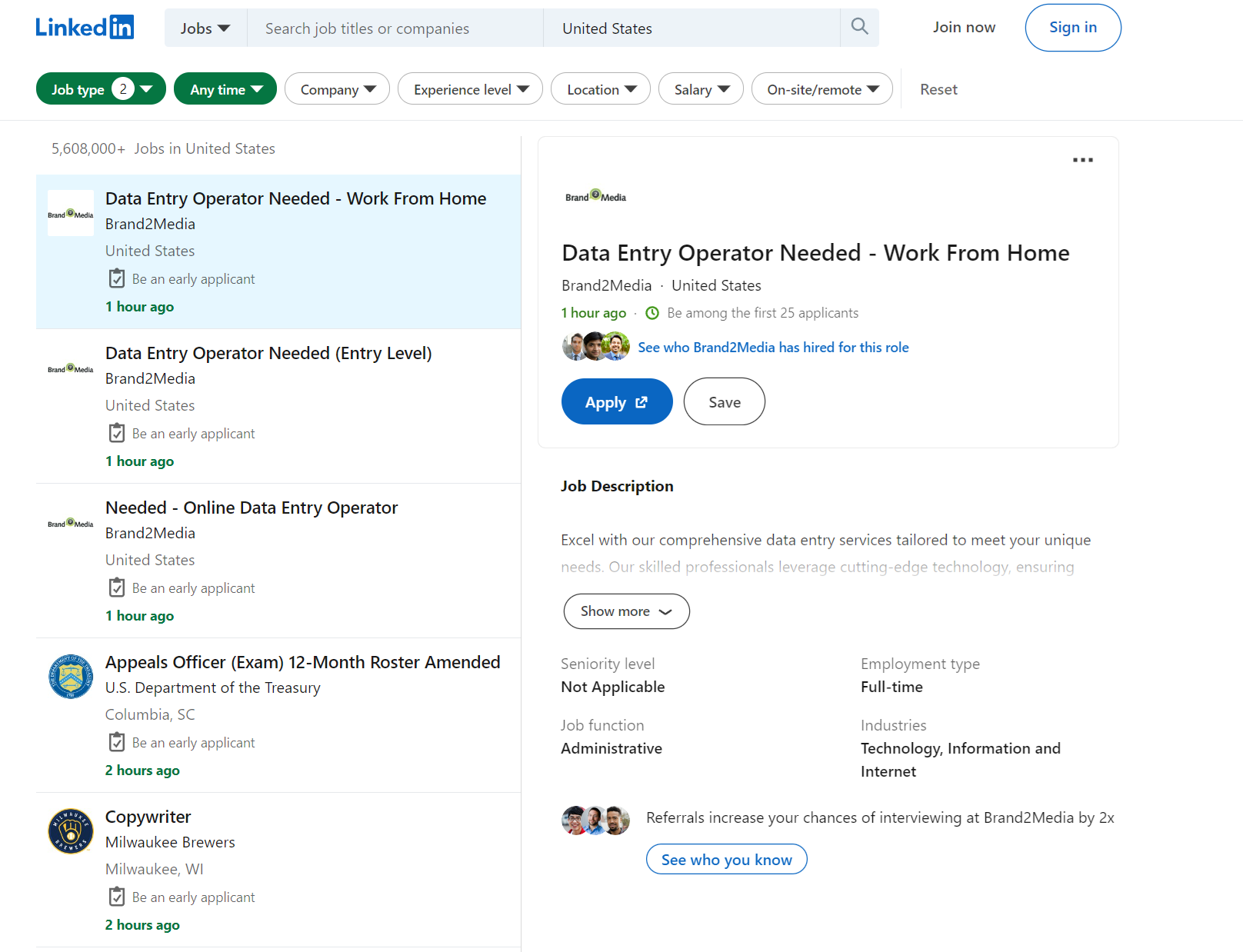
Mari kita uraikan filter yang dapat kita gunakan:
f_SB2: Gaji level 1 sampai 5, mulai 40.000 $ dengan kenaikan 20.000 $.f_E: Tingkat pendidikan dari 1 hingga 5, pilihan ganda dimungkinkan.f_TPR: Periode. Jika kosong, lowongan akan ditampilkan selamanya.location: Lokasi. Negara atau kota dapat ditentukan.keywords: Kata kunci untuk mencari lowongan.f_JT: Jenis pesanan. Huruf pertama digunakan sebagai parameter, mis. B. Penuh waktu sebagai F atau paruh waktu sebagai P. Beberapa opsi dapat ditentukan.position: Nomor posisi lowongan yang rinciannya ditampilkan.pageNum: Temukan nomor halaman.
Dengan mengekstraksi data dari satu halaman untuk semua lowongan pekerjaan yang tersedia tanpa harus menelusuri setiap halaman, kami hanya dapat mengekstrak data tentang perusahaan, jabatan, lokasi, dan jumlah tanggapan.
Buat skrip baru dan ambil data ini. Pertama kita mengimpor perpustakaan yang diperlukan:
import requests
import json
from bs4 import BeautifulSoup
import csvKemudian atur pengaturan pekerjaan dan buat tautan:
f_SB2 = 1 # Salary level from 40k to $120k
f_E = 1 # Expirience level 1 (e.g., Internship)
f_TPR = "" # Vacancies displayed for all time periods
location = "United States" # Country or city
keywords = "Data Scientist" # Keywords for search
f_JT = "F" # Employment type - Full-time
position = 1 # Job position number for details
pageNum = 0 # Page number of search results
# Constructing the URL
ln_url = f"https://www.linkedin.com/jobs/search?f_SB2={f_SB2}&f_E={f_E}&f_TPR={f_TPR}&location={location}&keywords={keywords}&f_JT={f_JT}&position={position}&pageNum={pageNum}"Setel kunci API HasData Anda:
api_key = "PUT-YOUR-API-KEY"Dapatkan data daftar pekerjaan LinkedIn menggunakan web scraping API:
url = "https://api.hasdata.com/scrape/web"
payload = json.dumps({
"url": ln_url,
"proxyCountry": "US",
"proxyType": "datacenter",
"blockResources": True,
"blockAds": True,
"screenshot": True,
"jsRendering": True,
"extractEmails": True
})
headers = {
'Content-Type': 'application/json',
'x-api-key': api_key
}
response = requests.request("POST", url, headers=headers, data=payload)
job_content = response.json()('content')Parsing kode HTML halaman:
soup = BeautifulSoup(job_content, 'html.parser')Dapatkan data untuk setiap pesanan:
job_list = soup.find('ul', class_='jobs-search__results-list')
if job_list:
jobs = job_list.find_all('li')
job_data = ()
for job in jobs:
print(job)
job_title = job.find('h3', class_='base-search-card__title').get_text(strip=True) if job.find('h3', class_='base-search-card__title') else '-'
company = job.find('h4', class_='base-search-card__subtitle').get_text(strip=True) if job.find('h4', class_='base-search-card__subtitle') else '-'
location = job.find('span', class_='job-search-card__location').get_text(strip=True) if job.find('span', class_='job-search-card__location') else '-'
job_link = job.find('a')('href') if job.find('a') else '-'
posted_date = job.find('time', class_='job-search-card__listdate')('datetime') if job.find('time', class_='job-search-card__listdate') else '-'
job_info = {
'job_title': job_title,
'company': company,
'location': location,
'job_link': job_link,
'posted_date': posted_date
}
job_data.append(job_info)Cetak hasilnya di layar:
if job_data:
for job in job_data:
print("Job Title:", job('job_title'))
print("Company:", job('company'))
print("Location:", job('location'))
print("Job Link:", job('job_link'))
print("Posted Date:", job('posted_date'))
print("-" * 50)Atau simpan data ini dalam format CSV:
with open("job_data.csv", 'w', newline="", encoding='utf-8') as csvfile:
fieldnames = ('job_title', 'company', 'location', 'job_link', 'posted_date')
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for job in job_data:
writer.writerow(job)Hasilnya kita mendapatkan:
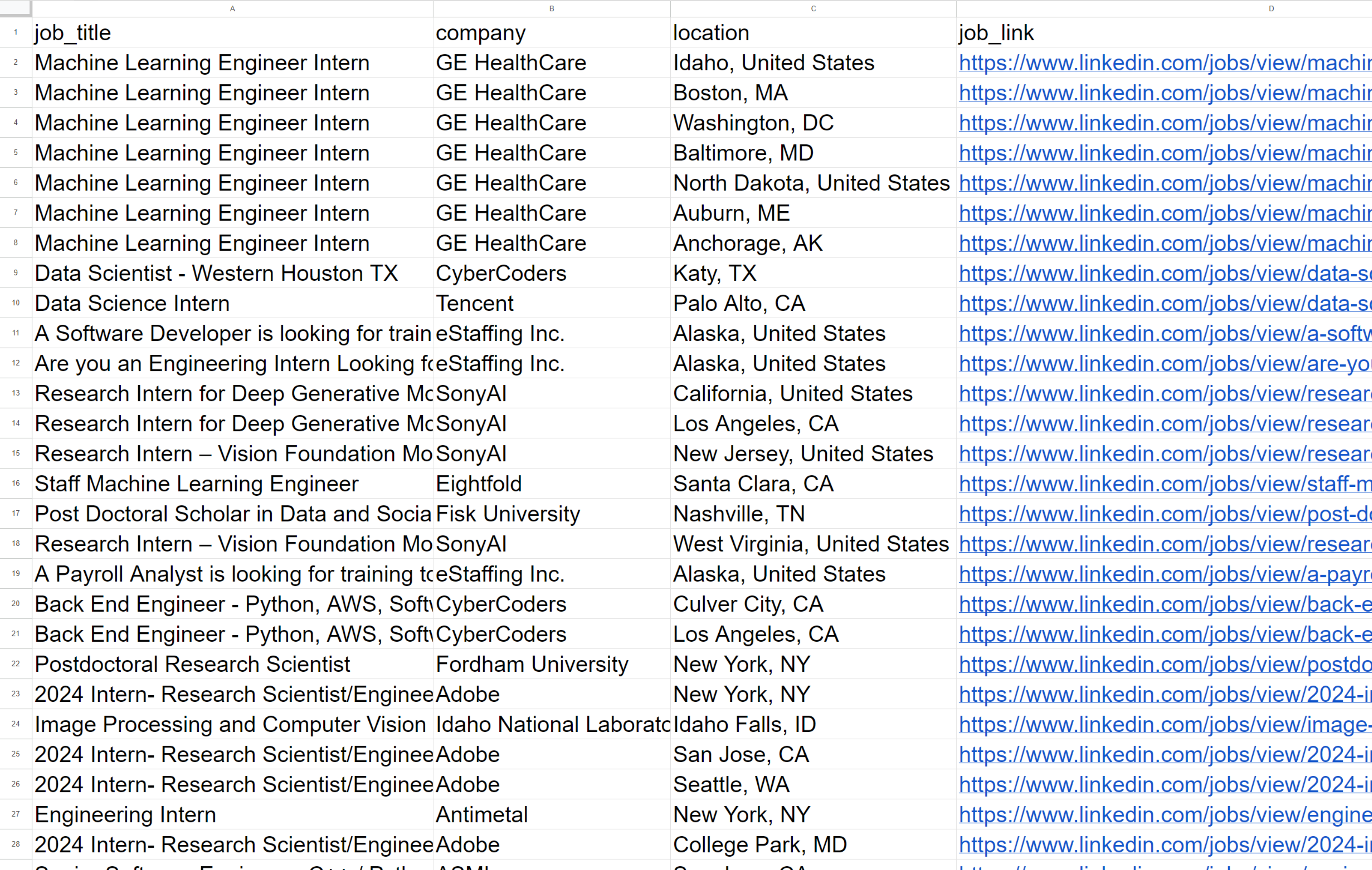
Seperti yang Anda lihat, setelah menjalankan skrip, kami menerima data tentang 60 lowongan, yang dikembalikan dalam format yang nyaman. Sayangnya, untuk mendapatkan data terperinci tentang setiap lowongan pekerjaan, Anda harus menelusuri masing-masing lowongan, yang mungkin rumit karena memerlukan banyak pertanyaan.
Kikis Pembelajaran LinkedIn
LinkedIn Learning menawarkan kursus ekstensif dan tutorial video tentang berbagai topik. Selain itu, skrip siap pakai tersedia di Google Colaboratory.
Mari navigasikan halaman Pembelajaran LinkedIn dan jelajahi filter dan opsi ekstraksi data yang tersedia.
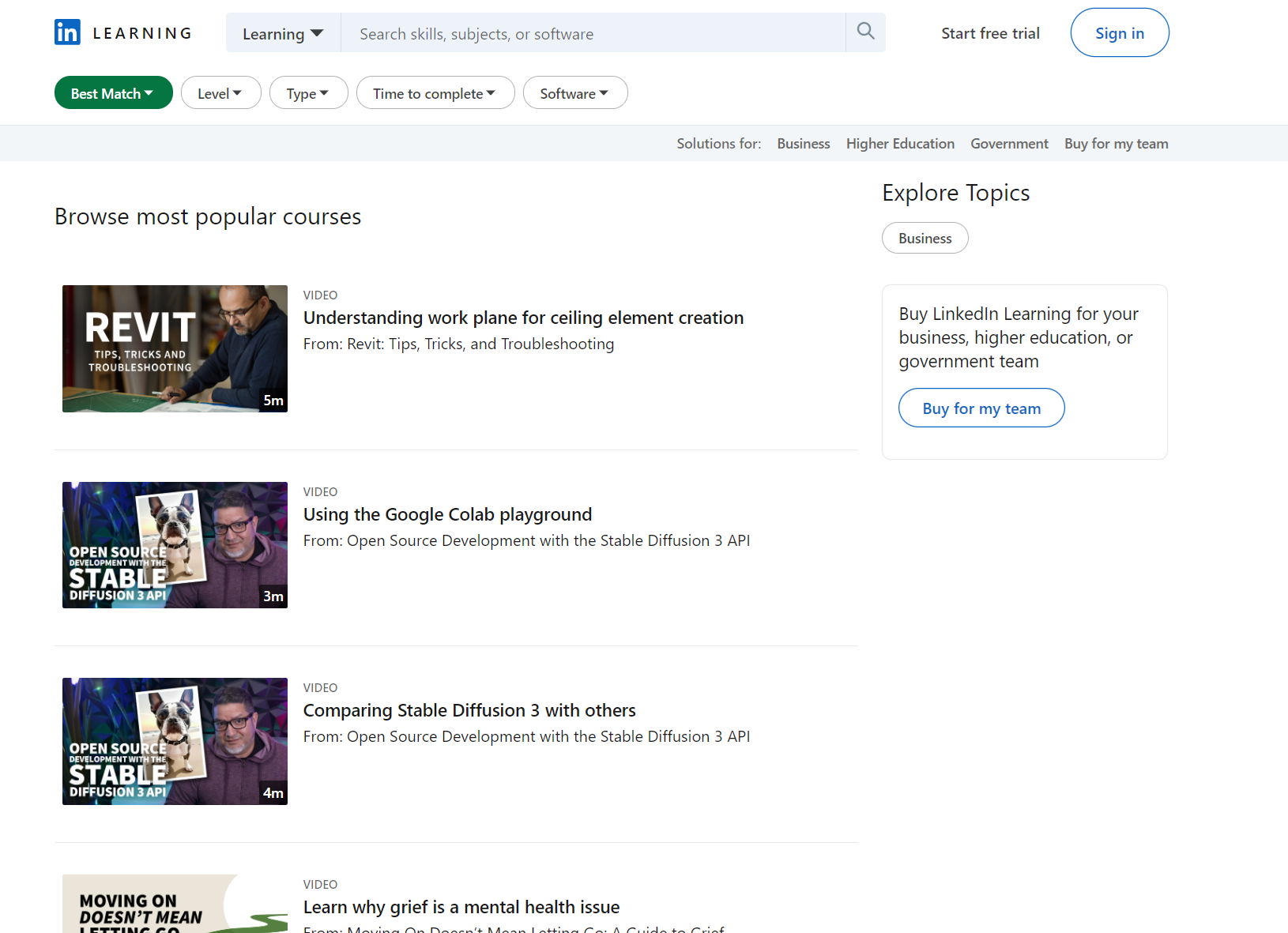
Situs ini memiliki lebih sedikit filter. Mari kita lihat lebih dekat:
sortBy: Metode pengurutan hasil. Misalnya “RELEVANCE” untuk mengurutkan berdasarkan relevansi.difficultyLevel: Tingkat kesulitan kursus. Misalnya “PEMULA” untuk level pemula.entityType: Jenis entitas yang akan dikembalikan dalam hasil pencarian. Dalam hal ini, ini adalah “KURSUS” untuk kursus.durationV2: Durasi kursus. Contoh: “BETWEEN_0_TO_10_MIN” untuk kursus dengan durasi 0 hingga 10 menit.softwareNames: Nama perangkat lunak yang terkait dengan kursus tersebut. Misalnya, “Power+Platform” untuk kursus yang terkait dengan Power Platform.
Di halaman ini kita dapat mengekstrak judul dan link ke kursus, penulisnya dan jenis materi pembelajaran. Mari kita ambil kode sebelumnya sebagai dasar dan ganti parameter untuk menghasilkan tautan:
sortBy = "RELEVANCE"
difficultyLevel = "BEGINNER"
entityType = "COURSE"
durationV2 = ""
softwareNames = ""
# Constructing the URL
ln_url = f"https://www.linkedin.com/learning/search?trk=content-hub-home-page_guest_nav_menu_learning&sortBy={sortBy}&difficultyLevel={difficultyLevel}&entityType={entityType}&durationV2={durationV2}&softwareNames={softwareNames}"Dan penyeleksi untuk mengurai halaman:
learn_list = soup.find('ul', class_='results-list')
if learn_list:
learns = learn_list.find_all('li')
learn_data = ()
for learn in learns:
title = learn.find('h3', class_='base-search-card__title').text.strip() if learn.find('h3', class_='base-search-card__title') else '-'
subtitle = learn.find('h4', class_='base-search-card__subtitle').text.strip() if learn.find('h4', class_='base-search-card__subtitle') else '-'
identifier = learn.find('p', class_='base-search-card__identifier').text.strip() if learn.find('p', class_='base-search-card__identifier') else '-'
learn_link = learn.find('a')('href') if learn.find('a') else '-'
job_info = {
'title': title,
'subtitle': subtitle,
'identifier': identifier,
'learn_link': learn_link,
}
learn_data.append(job_info)Kode lainnya tetap sama. Ini akan membuat file dengan daftar kursus yang tersedia:
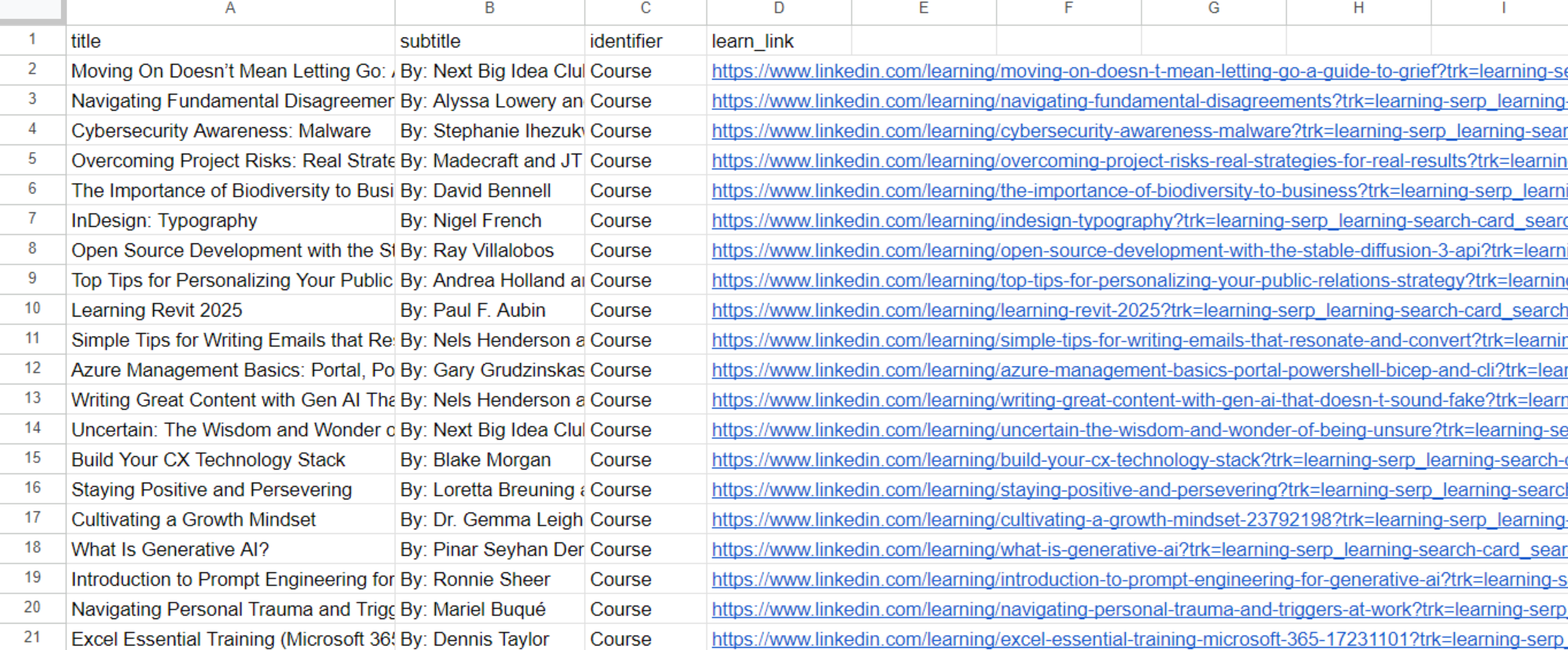
Kami menerima file berisi 50 materi pembelajaran ramah pemula, termasuk kursus dan video tutorial berdurasi antara 0 hingga 10 menit.
Kikis artikel LinkedIn
Bagian lain yang mungkin perlu segera dihapus adalah artikel LinkedIn. Anda dapat menemukan skrip yang sudah jadi di Google Colaboratory.
Mari buka halaman Artikel LinkedIn dan lihat lebih dekat:
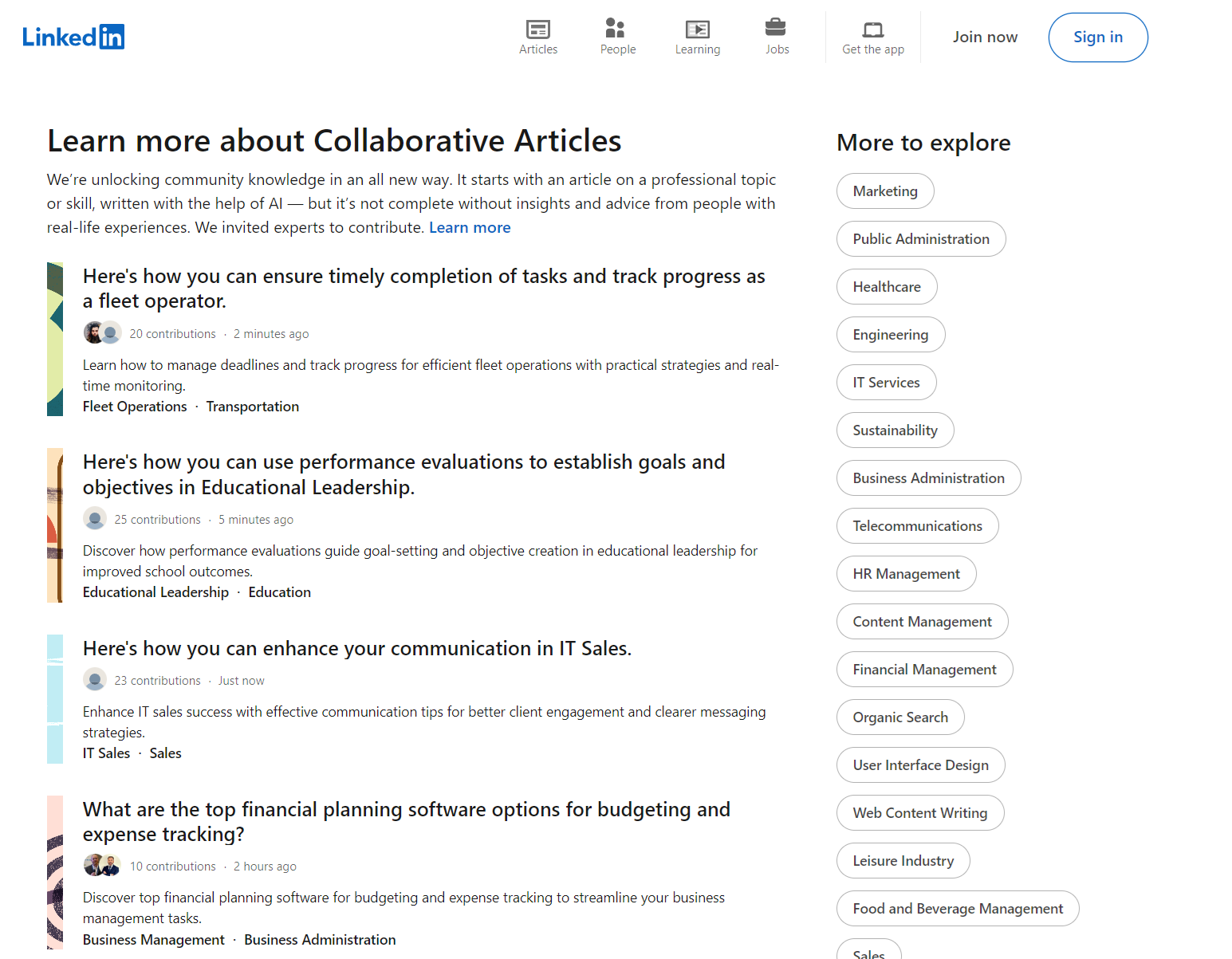
Berbeda dengan contoh sebelumnya, tidak ada filter yang dapat disesuaikan di sini. Namun, Anda dapat memilih kategori atau subkategori mana pun di sebelah kanan. Sebagai contoh, kami akan menggunakan tautan ke bagian root:
ln_url = f"https://www.linkedin.com/pulse/topics/home/"Dan ubah pemilih:
article_list = soup.find('div', class_='content-hub-home-core-rail')
if article_list:
articles = article_list.find_all('div', class_='content-hub-entity-card-redesign')
article_data = ()
for article in articles:
title = article.find('h2').text.strip() if article.find('h2') else '-'
description = article.find('p', class_='content-description').text.strip() if article.find('p', class_='content-description') else '-'
contributions = article.find('span').text.strip() if article.find('span') else '-'
timestamp = article.find_all('span')(-1).text.strip() if article.find('span') else '-'
article_link = article.find('a')('href') if article.find('a') else '-'
article_info = {
'title': title,
'description': description,
'contributions': contributions,
'timestamp': timestamp,
'article_link': article_link,
}
article_data.append(article_info)Bagian skrip lainnya tetap sama seperti contoh sebelumnya dan menghasilkan file CSV berikut:

Total kami menerima 100 link artikel tentang topik yang ditentukan. Jika perlu, skrip dapat disempurnakan untuk mengumpulkan data yang lebih detail dengan mencari semua link dalam antrian. Hal ini memungkinkan kami mengambil konten artikel, informasi penulis, tautan ke profil dan panelis mereka.
Diploma
Dalam artikel ini, kami memeriksa berbagai metode untuk mengakses data di LinkedIn dan mengeksplorasi pendekatan berbeda untuk menerapkan scraper. Selain itu, kami telah menyediakan contoh kode siap pakai dan mengunggahnya ke Google Colaboratory untuk kemudahan akses dan eksekusi berbasis cloud.
Itu sebabnya kami mengembangkan beberapa alat praktis yang mempermudah pengambilan data yang dipersonalisasi dari LinkedIn, baik data tersebut diambil dari halaman kursus atau halaman daftar pekerjaan. Untuk mengilustrasikan dan menyederhanakan pengumpulan data, kami menggunakan API HasData, yang memungkinkan pengumpulan data tanpa risiko diblokir oleh LinkedIn dan tanpa harus masuk ke profil Anda.
