
TL;DR: Pengikis harga produk
Jika Anda sudah menggunakan Pengikisan web Jika Anda sudah familiar dan hanya ingin solusi cepat, berikut kode Python yang saya gunakan untuk mengikis harga produk Zara menggunakan Scrapy dan Beautifulsoup:
import scrapy
from urllib.parse import urlencode
from bs4 import BeautifulSoup
def get_scraperapi_url(url):
APIKEY = "YOUR_SCRAPERAPI_KEY"
payload = {'api_key': APIKEY, 'url': url, 'render': True}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
class ZaraProductSpider(scrapy.Spider):
name = "zara_products"
def start_requests(self):
urls = (
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=2',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=3'
)
for url in urls:
yield scrapy.Request(url=get_scraperapi_url(url), callback=self.parse)
def parse(self, response):
soup = BeautifulSoup(response.body, 'html.parser')
for product in soup.select('div.product-grid-product-info'):
product_name = product.select_one('h2').get_text(strip=True) if product.select_one('h2') else None
price = product.select_one('span.money-amount__main').get_text(strip=True) if product.select_one('span.money-amount__main') else None
yield {
'product_name': product_name,
'price': price,
}
Sebelum menjalankan script, pastikan Scrapy sudah terinstall (pip install scrapy). Juga, buat akun ScraperAPI gratis dan ganti “YOUR_SCRAPERAPI_KEY” dengan kunci API Anda yang sebenarnya – dengan cara ini kami berhasil menghindari tantangan apa pun dalam memangkas harga produk Zara.
Mengapa mengikis harga?
Mengawasi harga pesaing sangat penting untuk kesuksesan bisnis. Dengan mengotomatiskan proses pengumpulan dan analisis data harga, Anda dapat tetap mendapat informasi tentang strategi pesaing dan membuat keputusan yang lebih baik untuk bisnis Anda.
Berikut tiga kasus penggunaan besar untuk data harga:
- Penetapan harga dinamis: Akses ke data harga kompetitif real-time memungkinkan Anda menerapkan strategi harga dinamis. Anda dapat menyesuaikan harga berdasarkan fluktuasi pasar, tren permintaan, dan promosi pesaing untuk memaksimalkan keuntungan Anda.
- Riset dan wawasan pasar: Pengikisan harga lebih dari sekadar menentukan harga pesaing Anda. Ini dapat membantu Anda mengidentifikasi tren harga di industri Anda, memahami struktur biaya, dan mendapatkan wawasan tentang perilaku pembeli.
- Kelincahan dan kemampuan beradaptasi: Dinamika pasar dapat berubah dengan cepat, dan perubahan harga sering kali mengikuti tren ini. Dengan memeriksa harga secara rutin, Anda dapat terus mengikuti perkembangan perubahan ini dan merespons dengan cepat, baik dengan menyesuaikan harga sendiri atau pesan pemasaran Anda.
Tentu saja, masih banyak kasus penggunaan lain untuk data harga produk. Namun, Anda harus terlebih dahulu membuat kumpulan data untuk dianalisis sebelum Anda dapat melakukan apa pun.
Mengikis harga produk dengan Python
Untuk proyek ini, kami akan membuat web scraper untuk mengekstrak data harga dari koleksi kemeja pria Zara. Meskipun kami berfokus pada Zara, konsep dalam panduan ini dapat diterapkan pada situs eCommerce mana pun.
Mari kita mulai!
Persyaratan proyek
Ini adalah alat dan perpustakaan yang Anda perlukan untuk proyek ini:
Anda dapat menginstalnya dengan pip:
pip install scrapy beautifulsoup4
Scrapy adalah rangkaian lengkap untuk merayapi web, mengunduh, memproses, dan menyimpan data yang dihasilkan dalam format yang dapat diakses. Ia bekerja dengan laba-laba, yang merupakan kelas Python yang menentukan cara situs web dinavigasi.
BeautifulSoup adalah pustaka Python yang menyederhanakan penguraian konten HTML di halaman web. Ini adalah alat penting untuk mengekstraksi data.
Catatan: Jika Anda perlu menginstal ulang semuanya dari awal, ikuti tutorial kami tentang dasar-dasar Scrapy dengan Python. Saya akan menggunakan pengaturan yang sama, jadi selesaikan dan kembali lagi.
Langkah 1: Siapkan Scrapy
Pertama, mari kita siapkan Scrapy. Mulailah dengan membuat proyek Scrapy baru:
scrapy startproject price_scraper
Perintah ini membuat yang baru Pengikis harga Direktori dengan file yang diperlukan untuk proyek yang sulit.
Sekarang jika Anda membuat daftar isi direktori ini, Anda akan melihat struktur berikut:
$ cd price_scraper
$ tree
.
├── price_scraper
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
└── scrapy.cfg
Menyiapkan proyek Scrapy kami selesai!
Langkah 2: Ikhtisar struktur situs web Zara
Sebelum Anda mulai mengkodekan laba-laba, penting untuk memahami struktur situs web yang ingin Anda gores.
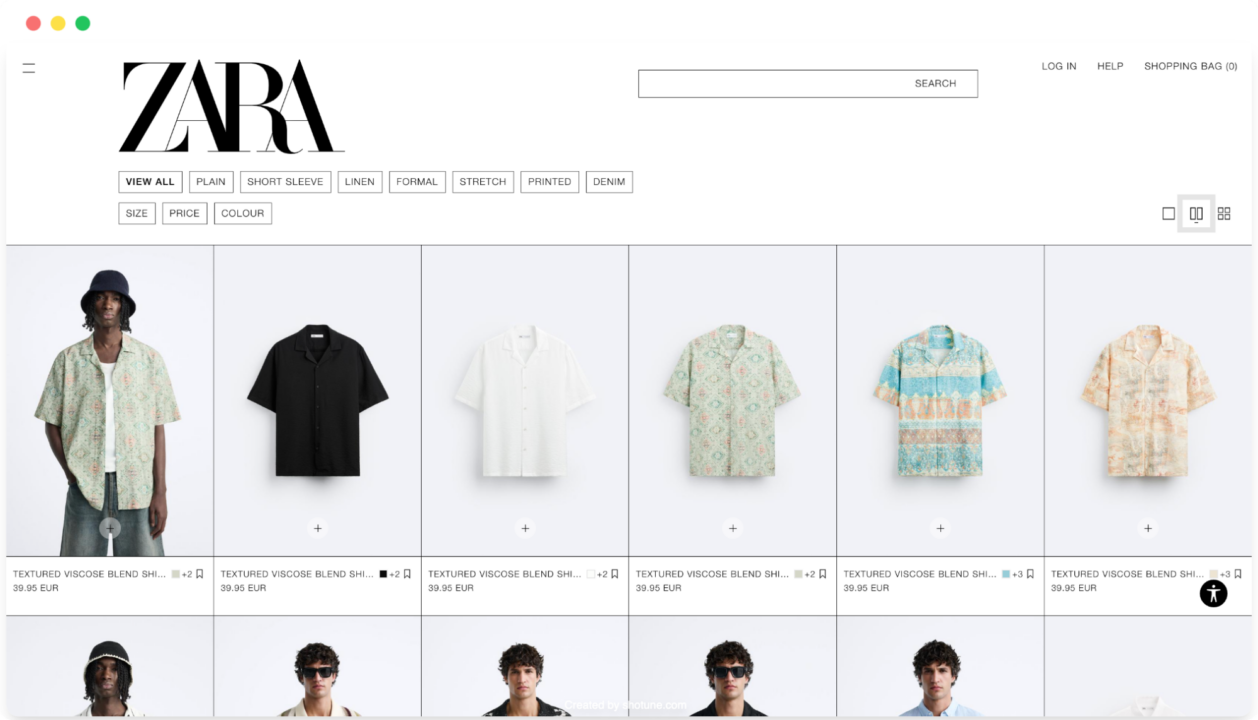
Buka bagian kemeja pria di situs Zara di browser Anda, klik kanan dan pilih "Memeriksa” untuk membuka alat pengembang.
Lihat kode sumber HTML untuk mengidentifikasi pemilih HTML yang diperlukan. Secara khusus, carilah elemen yang mengandung nama produk dan harga.
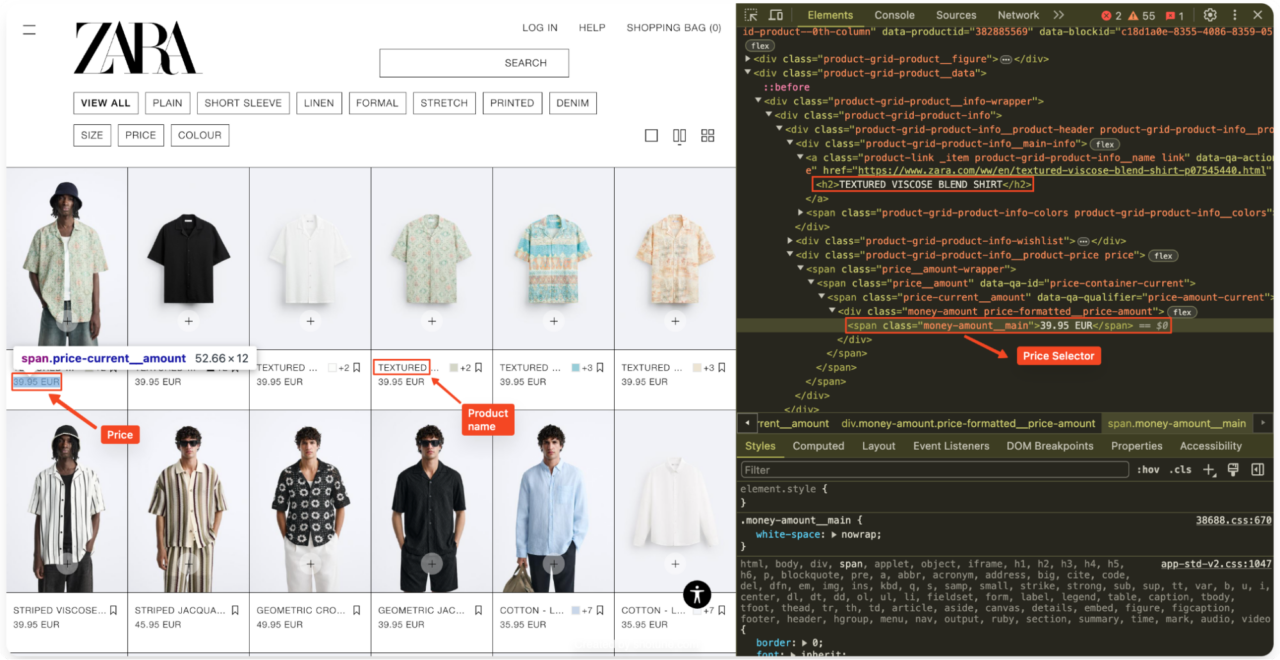
Di Zara informasi produk biasanya ada dalam satu
product-grid-product-infoNama produk biasanya ada di dalam a
hari, dan harganya dalam satumoney-amount__main.
Langkah 3: Membuat Laba-laba
Sekarang saya menavigasi ke spiders direktori di proyek saya dan buat file baru bernama zara_spider.py. File ini berisi logika untuk menggores situs web Zaras.
cd spiders
touch zara_spider.py
Langkah 4: Tentukan metode ScraperAPI
Saya akan menggunakan ScraperAPI untuk menangani kemungkinan pemblokiran dan masalah rendering JavaScript. Saya akan mengirimkan permintaan saya melalui server ScraperAPI dengan menambahkan URL permintaan saya ke URL proxy yang disediakan oleh ScraperAPI oleh
payload Dan urlencode.
Di atas zara_spider.pyimpor perpustakaan yang diperlukan:
import scrapy
from urllib.parse import urlencode
from bs4 import BeautifulSoup
Berikut kode untuk integrasi ScraperAPI:
APIKEY = "YOUR_SCRAPERAPI_KEY"
def get_scraperapi_url(url):
payload = {'api_key': APIKEY, 'url': url, 'render': True}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
Itu get_scraperapi_url() Fungsi ini mengambil URL sebagai masukan, menambahkan kunci ScraperAPI saya dan mengembalikan URL yang dimodifikasi. URL yang dimodifikasi ini mengalihkan permintaan kami melalui ScraperAPI, sehingga lebih sulit bagi situs web untuk mendeteksi dan memblokir aktivitas scraping kami.
Penting: Jangan lupa ganti".YOUR_SCRAPERAPI_KEY“ dengan kunci API Anda saat ini dari ScraperAPI.
Langkah 5: Menulis kelas Spider utama
Di Scrapy saya dapat membuat kelas berbeda, yang disebut laba-laba, untuk mengikis halaman atau grup situs tertentu. Dengan pengaturan ScraperAPI, saya bisa mulai menulis kelas Spider utama. Kelas ini menjelaskan bagaimana scraper kami akan berinteraksi dengan situs web Zara.
Ini kode untuk kita ZaraProductSpider Kelas:
class ZaraProductSpider(scrapy.Spider):
name = "zara_products"
def start_requests(self):
urls = (
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=2',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=3'
)
for url in urls:
yield scrapy.Request(url=get_scraperapi_url(url), callback=self.parse)
Dalam kode ini saya memiliki kelas bernama ZaraProductSpideryang mewarisi karakteristik dari basis Scrapy Spider Kelas. Warisan ini membuat kelas kita menjadi 'Gores laba-laba'.
Di dalam kelas, name = "zara_products" mendefinisikan nama laba-laba kita. Kami akan menggunakan nama ini nanti untuk menjalankan laba-laba dari terminal kami. Itu
start_requests Metode ini menentukan titik awal laba-laba dengan menentukan URL yang ingin kita kikis. Dalam hal ini, saya menargetkan tiga halaman pertama bagian kemeja pria di situs Zara.
Kode kemudian mengulang setiap URL di urls Buat daftar dan gunakan objek Permintaan Scrapy untuk mengambil konten HTML setiap halaman. Itu
callback=self.parse Argumen memberitahu Scrapy untuk menggunakan
parse Metode (yang akan kita definisikan selanjutnya) untuk memproses konten yang diunduh.
Langkah 6: Mengurai respons HTML
Saatnya untuk mendefinisikan, parse Metode yang memproses konten HTML yang saya unduh dari Zara.
def parse(self, response):
soup = BeautifulSoup(response.body, 'html.parser')
for product in soup.select('div.product-grid-product-info'):
product_name = product.select_one('h2').get_text(strip=True) if product.select_one('h2') else None
price = product.select_one('span.money-amount__main').get_text(strip=True) if product.select_one('span.money-amount__main') else None
yield {
'product_name': product_name,
'price': price,
}
Metode Parse menerima konten HTML yang diunduh sebagai objek respons. Saya kemudian membuat objek BeautifulSoup bernama soup untuk mengurai respons HTML ini.
Kode kemudian melewati semuanya
kelas
product-grid-product-infoyang sebelumnya saya identifikasi sebagai wadah informasi produk.
Untuk setiap produk saya mengekstrak nama produk dari
hari dan harga dari
hari bersama kelas money-amount__main.
saya menggunakan get_text(strip=True) untuk menghapus spasi ekstra dari teks yang diekstraksi. Jika tag tidak ditemukan, saya menetapkan nilai yang sesuai (nama produk atau harga). None.
Terakhir, saya membuat kamus dengan produk yang diekstraksi
name Dan price for each product. Hal ini memungkinkan Scrapy mengumpulkan dan memproses data lebih lanjut, misalnya menyimpannya ke file.
Langkah 7: Menjalankan Laba-laba
Ketika laba-laba saya sudah dikodekan sepenuhnya, saya dapat menjalankannya dengan perintah berikut:
scrapy crawl zara_products
Perintah ini memberitahu Scrapy untuk menjalankan laba-laba zara_products. Scrapy sekarang mengirimkan permintaan ke situs web Zara, memproses HTML yang diunduh, mengekstrak data produk berdasarkan logika yang saya tentukan dan mengeluarkan data ke konsol.
Langkah 8: Simpan data harga
Meskipun melihat data yang diekstraksi di konsol berguna untuk debugging, saya lebih suka menyimpan data untuk digunakan nanti. Scrapy menyederhanakan proses ini dengan dukungan bawaan untuk mengekspor data ke berbagai format, termasuk CSV.
Untuk menyimpan data yang saya ekstrak ke file CSV, saya menggunakan perintah berikut:
scrapy crawl zara_products -o zara_mens_prices.csv
Perintah ini mengeksekusi zara_products Spider dan menyimpan data yang diekstraksi dalam file bernama zara_mens_prices.csv. Itu
-o Opsi menunjukkan bahwa saya ingin mengeluarkan file. Itu membuat file baru dan memasukkan data yang tergores ke dalamnya.
Langkah 9: Lengkapi Kode dan Hasil.
Berikut ini kode lengkap untuk laba-laba saya:
import scrapy
from urllib.parse import urlencode
from bs4 import BeautifulSoup
def get_scraperapi_url(url):
APIKEY = "YOUR_SCRAPERAPI_KEY"
payload = {'api_key': APIKEY, 'url': url, 'render': True}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
class ZaraProductSpider(scrapy.Spider):
name = "zara_products"
def start_requests(self):
urls = (
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=2',
'https://www.zara.com/ww/en/man-shirts-l737.html?v1=2351464&page=3'
)
for url in urls:
yield scrapy.Request(url=get_scraperapi_url(url), callback=self.parse)
def parse(self, response):
soup = BeautifulSoup(response.body, 'html.parser')
for product in soup.select('div.product-grid-product-info'):
product_name = product.select_one('h2').get_text(strip=True) if product.select_one('h2') else None
price = product.select_one('span.money-amount__main').get_text(strip=True) if product.select_one('span.money-amount__main') else None
yield {
'product_name': product_name,
'price': price,
}
Penting: Ingatlah untuk mengganti
YOUR_SCRAPERAPI_KEY dengan kunci API Anda saat ini dari Scraper API.
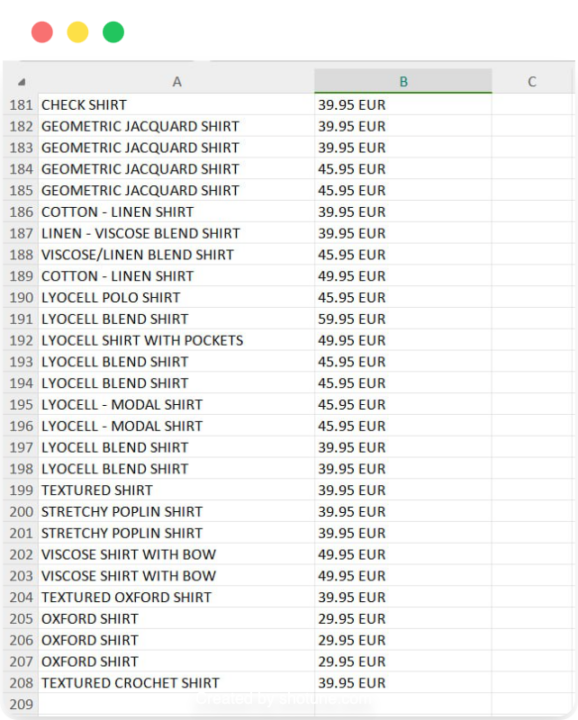
Dan itu dia! Anda sekarang memiliki file CSV yang berisi nama produk dan harga dari tiga halaman pertama bagian kemeja pria Zara, siap untuk dianalisis lebih lanjut atau digunakan di aplikasi lain.
Mengikis harga dengan ScraperAPI SDEs
Titik Akhir Data Terstruktur (SDE) ScraperAPI menyederhanakan proses pemotongan harga produk dengan menyediakan data terstruktur dalam format JSON. Daripada berurusan dengan penguraian HTML dan modifikasi situs web yang rumit, SDE menyediakan data terstruktur, sering kali dalam format JSON atau CSV yang mudah digunakan, membuat ekstraksi data lebih cepat dan mengurangi rawan kesalahan.
catatan: Periksa dokumentasi SDE.
Mari jelajahi bagaimana Anda dapat menggunakan ScraperAPI SDE untuk mengurangi harga produk dari platform eCommerce utama:
Harga produk Amazon
Mengabaikan mekanisme anti-bot Amazon saat menambang data produk dalam skala besar bukanlah hal yang mudah. Tantangan yang mungkin Anda hadapi mencakup pemblokiran IP, CAPTCHA, dan perubahan yang sering terjadi pada halaman produk.
Untungnya, Amazon SDE ScraperAPI dirancang untuk mengatasi tantangan ini dan menyediakan data produk yang bersih, termasuk harga yang sering diminta.
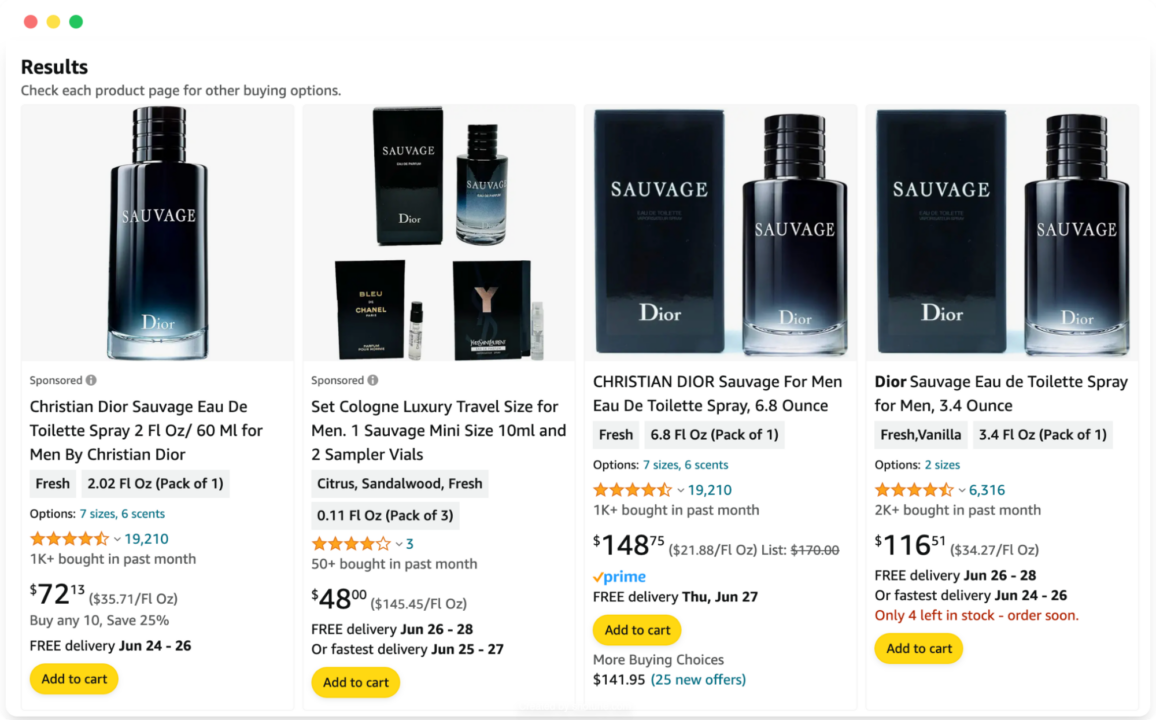
Mengikis harga produk dari Amazon menggunakan Amazon Search API sangatlah mudah. Anda dapat mengumpulkan data terstruktur dalam format JSON dengan membuat permintaan API sederhana:
import requests
import json
APIKEY= "YOUR_SCRAPER_API_KEY" # Replace with your ScraperAPI key
QUERY = "Sauvage Dior"
payload = {'api_key': APIKEY, 'query': QUERY, 'country': 'us'}
r = requests.get('https://api.scraperapi.com/structured/amazon/search', params=payload)
# Parse the response text to a JSON object
data = r.json()
with open('amazon_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in amazon_results.json")
Dalam kode ini, pertama-tama kita mendefinisikan kunci API dan permintaan pencarian kita. Kami kemudian merancang payload dengan api_key, querydan opsional country_code Parameter.
catatan: Anda juga dapat mengatur TLD tertentu untuk mendapatkan lebih banyak data yang dilokalkan.
Permintaan dikirim ke titik akhir ScraperAPI dan jika berhasil, responsnya diurai menjadi objek JSON. Objek JSON ini berisi semua informasi produk, termasuk harga produk. Terakhir, data disimpan dalam file bernama. amazon_results.json.
{
"results": (
{
"type": "search_product",
"position": 1,
"asin": "B014MTG78S",
"name": "Christian Dior Sauvage Eau de Toilette for Men, 2 Ounce",
"image": "https://m.media-amazon.com/images/I/4140FetAgkL.jpg",
"has_prime": true,
"is_best_seller": false,
"is_amazon_choice": false,
"is_limited_deal": false,
"purchase_history_message": "800+ bought in past month",
"stars": 4.6,
"total_reviews": 19210,
"url": "https://www.amazon.com/Sauvage-Christian-Dior-Toilette-Ounce/dp/B014MTG78S/ref=sr_1_1?dib=eyJ2IjoiMSJ9.Fx8LrOyO3CO4VY3zYWkqSe6-HzohovLm08Mkg8Nhgv3folygQwBLui6jDIIPKugSKh4IuQoglcYFl-hTDoa_asMO1TR0AmgUv4w_kLY2WzF8Hf3XuPzIOe97F9kk71M75FofVmcOnoN7U_XYoAw4fddsl9uF8aFAOxfIP0O4Q_GU-BJbRZ7bZrwKqJb_dFHYzNxp-OYwpQBcWStRkJnHiLPgqqG1H4Nh9y8mngo4tnE-5ZWlz3AfcCWueqdASDLKB0ec3OhGATmQ70-yJILtXRjJ6OBuuyChX7HNIEBzEcg.i29lFhcRatBkMJ6pkTgb33fotRSWWjCUhV87WGhB1Wo&dib_tag=se&keywords=Sauvage+Dior&qid=1718868400&sr=8-1",
"availability_quantity": 1,
"spec": {},
"price_string": "$86.86",
"price_symbol": "$",
"price": 86.86,
"original_price": {
"price_string": "$92.99",
"price_symbol": "$",
"price": 92.99
}
}, //TRUNCATED
}
Anda dapat menyesuaikan pengumpulan data dengan menggunakan parameter tambahan dalam permintaan API, seperti: B. dengan menentukan negara untuk domain Amazon (country), mengatur format keluaran (output_format) dan implementasi penomoran halaman (page) untuk mengambil hasil dari beberapa halaman.
Dokumentasi Amazon Search API menyediakan daftar lengkap parameter yang tersedia dan kasus penggunaan tingkat lanjut.
Kiat profesional
Jika Anda hanya ingin mengambil harga produk, Anda dapat menggunakan kunci JSON untuk memilih nilai tertentu. Untuk contoh ini, mari kita ambil nama, harga, mata uang, dan URL untuk setiap produk:
Pertama, mari buat daftar kosong di bagian atas file kita:
Selanjutnya kita simpan semua hasil produk organik (dalam file
resultskunci) menjadi satuall_productsVariabel:all_products = data('results')Sekarang kami dapat mengulangi setiap produk dan mengekstrak informasi spesifik yang menarik minat kami.
Namun ada satu hal. Di halaman hasil pencarian Amazon, beberapa produk tidak memiliki harga, begitu pula ScraperAPI
priceKunci. Untuk menghindari masalah, kami memeriksa apakahpriceKuncinya ada pada informasi produk sebelum nilainya ditambahkan ke daftar kosong kami.for product in all_products: product_name = product('name') product_url = product('url') #checking if the product has the price key if 'price' in product: product_price = product('price') product_currency = product('price_symbol') #appeding the product information to our list product_prices.append({ 'name': product_name, 'price': product_price, 'currency': product_currency, 'url': product_url }) else: product_prices.append({ 'name': product_name, 'price': 'not found', 'url': product_url })Dengan menggunakan pasangan nilai kunci JSON, mudah untuk mendapatkan titik data spesifik dari respons. Sekarang yang perlu kita lakukan hanyalah
dump()Itu
product_pricesDaftar ke dalam file JSON seperti yang kita lakukan sebelumnya:with open('amazon_results.json', 'w') as json_file: json.dump(product_prices, json_file, indent=4) print("Results have been stored in amazon_results.json")Anda dapat menggunakan prosedur serupa untuk SDE lainnya.
sumber: Pelajari cara mengikis data produk Amazon menggunakan Python dan ScraperAPI.
Harga produk Walmart
Seperti Amazon, Walmart menghadirkan tantangan terhadap metode pengikisan tradisional karena tindakan deteksi bot dan struktur situs web yang selalu berubah. API Walmart ScraperAPI melewati hambatan ini dan memberi Anda data produk terstruktur, termasuk harga, secara langsung.
Berikut adalah contoh sederhana yang menunjukkan cara mendapatkan harga produk dari Walmart:
import requests
import json
APIKEY= "YOUR_SCRAPER_API_KEY" # Replace with your ScraperAPI key
QUERY = "Sauvage Dior"
payload = {'api_key': APIKEY, 'query': QUERY, 'page': '2'}
r = requests.get('https://api.scraperapi.com/structured/walmart/search', params=payload)
data = r.json()
# Write the JSON object to a file
with open('walmart_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in walmart_results.json")
Dalam kode ini kita mendefinisikan milik kita api_key dan itu
query dan berikan itu page Nomor untuk penomoran halaman. Permintaan dikirim ke titik akhir Walmart Search API dan jika berhasil, respons diurai menjadi objek JSON dan disimpan di
walmart_results.json.
{
"items": (
{
"availability": "In stock",
"id": "52HDEPYCF0WO",
"image": "https://i5.walmartimages.com/seo/Dior-Sauvage-Eau-de-Parfum-300ml_3bb963cb-2769-4c61-b2b7-9bc5fc35e864.119f0ebb7fea31368d709ea899cbe13f.jpeg?odnHeight=180&odnWidth=180&odnBg=FFFFFF",
"sponsored": true,
"name": "Dior Sauvage Eau de Parfum 300ml",
"price": 245.95,
"price_currency": "$",
"rating": {
"average_rating": 0,
"number_of_reviews": 0
},
"seller": "Ultimate Beauty SLU",
"url": "https://www.walmart.com/ip/Dior-Sauvage-Eau-de-Parfum-300ml/2932396976"
}, //TRUNCATED
),
"meta": {
"page": 2,
"pages": 25
}
}
Anda dapat menyesuaikan ekstraksi data menggunakan parameter seperti
output_format untuk menentukan keluaran CSV atau JSON. Untuk daftar lengkap parameter dan penggunaannya, lihat dokumentasi Walmart Search API.
sumber: Pelajari cara mengikis data produk Walmart menggunakan Python dan ScraperAPI.
Harga produk Google Belanja
Karena pemuatan konten yang dinamis dan mekanisme anti-scraping, mungkin sulit untuk mengikis Google Shopping secara efektif menggunakan metode tradisional. Google Shopping API ScraperAPI sangat menyederhanakan proses ini dengan menyediakan data produk yang bersih dan terstruktur, termasuk harga.
Berikut adalah contoh sederhana yang menunjukkan cara mengekstrak data produk dari Google Shopping:
import requests
import json
APIKEY= "YOUR_SCRAPER_API_KEY" # Replace with your ScraperAPI key
QUERY = "Chop sticks"
payload = {'api_key': APIKEY, 'query': QUERY, 'country_code': 'jp'}
r = requests.get('https://api.scraperapi.com/structured/google/shopping', params=payload)
# Parse the response text to a JSON object
data = r.json()
# Write the JSON object to a file
with open('google_results.json', 'w') as json_file:
json.dump(data, json_file, indent=4)
print("Results have been stored in google_results.json")
Di sini saya mendefinisikan kunci API dan permintaan pencarian saya. Setelah saya membuat payload, permintaan dikirim ke SDE Google Shopping.
Jika respons berhasil, data diurai menjadi objek JSON dan disimpan
google_results.json.
{
"search_information": {},
"ads": (),
"shopping_results": (
{
"position": 1,
"docid": "9651870852817516154",
"link": "https://www.google.co.jp/url?url=https://www.amazon.co.jp/GLAMFIELDS-Fiberglass-Chopsticks-Reusable-Dishwasher/dp/B08346GNS5%3Fsource%3Dps-sl-shoppingads-lpcontext%26ref_%3Dfplfs%26ref_%3Dfplfs%26psc%3D1%26smid%3DA1IXFONC0DTBL5&rct=j&q=&esrc=s&opi=95576897&sa=U&ved=0ahUKEwjjwoXJ2-mGAxXonYQIHebrDoAQ2SkIxQg&usg=AOvVaw0dYnZyMtnWgRJvjmYNuAx0",
"title": "GLAMFIELDS 10 Pairs Fiberglass Chopsticks, Reusable Japanese Chinese Chop Sticks ...",
"source": "Amazon\u516c\u5f0f\u30b5\u30a4\u30c8",
"price": "\uffe52,240",
"extracted_price": 22.4,
"thumbnail": "https://encrypted-tbn0.gstatic.com/shopping?q=tbn:ANd9GcTMdg46wyytkT3p9bvEKBZwtpdyRI97OGHmJBLQIyDjX1JC6Hm3WPEZUrGzJLqnB3Y3tKA6cFbq0gYUJF0XcBlh77VPy7xWVY79HyTtujQdohmytfoKZWnm&usqp=CAE",
"delivery_options": "\u9001\u6599 \uffe5642",
"delivery_options_extracted_price": 6.42
}, //TRUNCATED
}
Untuk penjelasan mendetail tentang semua parameter yang tersedia, lihat dokumentasi Google Shopping API.
