
Immobilienscout24 adalah portal real estate terkemuka di Jerman dengan database properti yang sangat besar. Mirip dengan platform populer AS seperti Redfin dan Zillow, Immobilienscout24 menawarkan antarmuka yang ramah pengguna untuk mencari dan membandingkan apartemen, rumah, ruang komersial, dan tanah. Opsi filter yang luas memudahkan Anda menemukan penawaran yang tepat.
Berbeda dengan rekan-rekannya di Amerika, Immobilienscout24 berfokus secara khusus pada pasar real estat Jerman, yang terkenal dengan stabilitasnya. Akses terhadap data ini sangat berharga bagi para analis, investor, dan agen real estat, menjadikan Immobilienscout24.de target yang menarik untuk pengumpulan data.
Pengantar pengikisan Immobilienscout24.de
Seperti telah disebutkan, Immobilienscout24.de adalah sumber yang bagus untuk mencari properti di Jerman. Sayangnya situs ini sebagian besar berbahasa Jerman. Ada area pengembang dengan dokumentasi untuk API resmi Immobilienscout24.de, tapi kita akan membahasnya lebih detail nanti. Sebelum kita mempelajari ekstraksi data Immobilienscout24.de, mari kita kenali istilah-istilah penting yang biasa digunakan dalam listingan. Meskipun antarmuka situs ini cukup ramah pengguna, memahami istilah-istilah ini akan sangat meningkatkan kemampuan kita untuk mengekstrak informasi yang kita perlukan secara akurat dan efisien. Istilah yang paling penting meliputi:
- Sewa – Sewa. Ini menunjukkan biaya bulanan untuk menyewa properti.
- Harga pembelian. Ini menunjukkan total biaya pembelian properti.
- Biaya tambahan – Biaya tambahan. Ini adalah biaya tambahan yang ditambahkan ke harga sewa atau pembelian dasar (misalnya biaya tambahan).
- ruang hidup. Ini mengacu pada total meter persegi seluruh ruang hidup di properti tersebut.
- RuangJumlah kamar merupakan faktor penting ketika mencari real estat.
Memahami istilah-istilah ini akan membantu Anda mengoptimalkan proses ekstraksi data dan mengekstrak informasi paling relevan dari entri.
Persiapan untuk pengikisan web
Sebelum kita membuat alat ekstraksi data, kita harus terlebih dahulu mengidentifikasi data spesifik yang ingin kita kumpulkan. Ini termasuk menentukan lokasi tepatnya di situs target dan memahami struktur dasarnya. Analisis awal ini akan membantu kita memilih teknik ekstraksi data yang paling tepat.
Untuk memulai, kami melakukan studi menyeluruh terhadap struktur situs web. Ini membantu kami mengidentifikasi elemen halaman yang berisi data yang diinginkan. Setelah kami memiliki pemahaman yang jelas tentang organisasi data, kami dapat menjelajahi berbagai metode web scraping dan memilih pendekatan yang paling efektif untuk kasus penggunaan spesifik kami.
Analisis struktur situs web
Mari kita buka situsnya dan lihat jenis data apa yang bisa kita peroleh dari kolom:
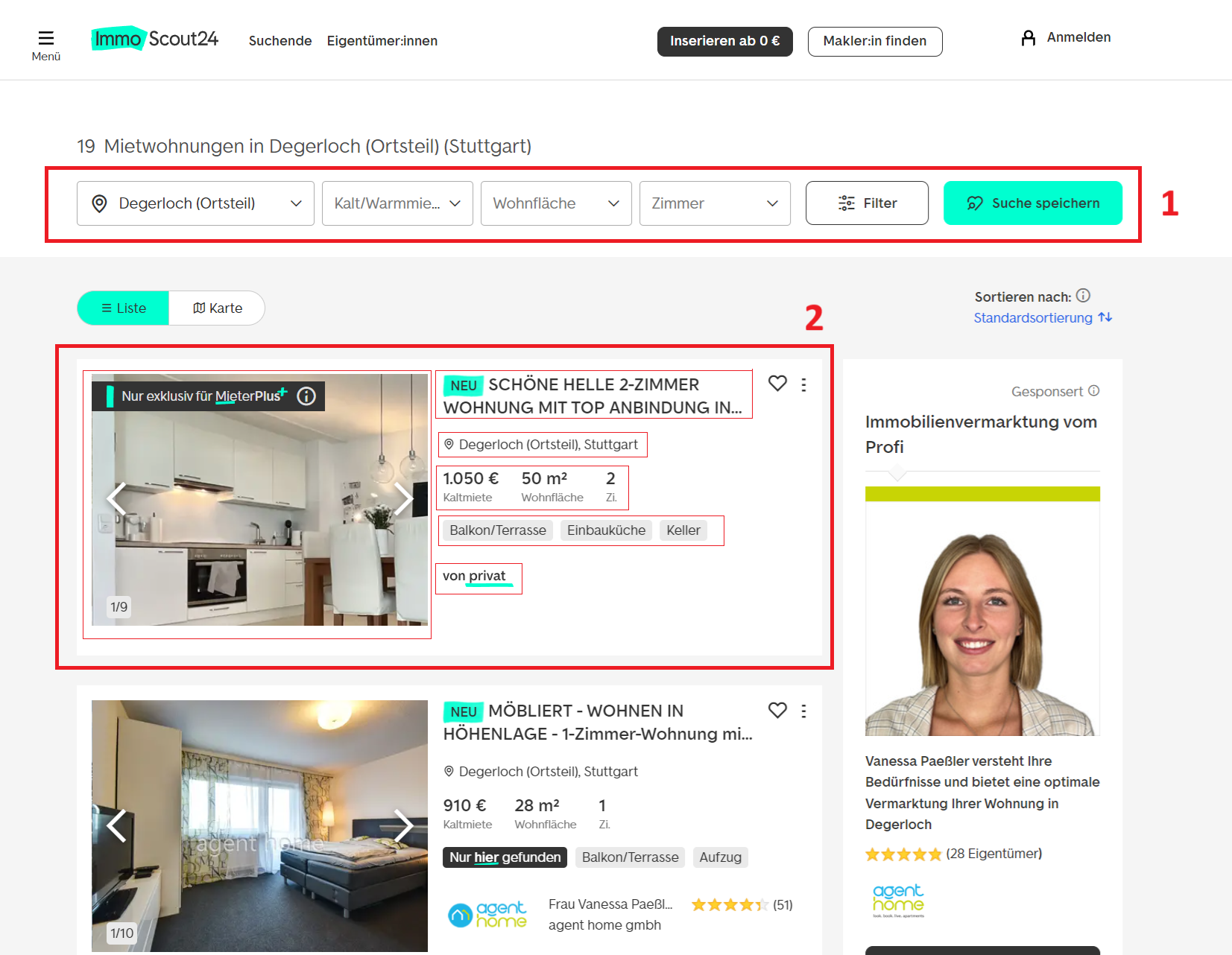
Komponen terpenting bagi kami adalah:
- Saring: Ini memungkinkan kami mempersonalisasi pencarian kami dan mengambil data yang kami perlukan.
- Kutipan: Setiap entri di situs berisi semua informasi yang diperlukan, mulai dari judul dan alamat hingga detail agensi, biaya, fasilitas, dan parameter lainnya.
Mari kita mulai dengan filter di halaman. Sebenarnya ada lebih banyak opsi filter yang tersedia daripada yang ditunjukkan di atas. Jika kami menavigasi ke halaman filter khusus, kami menemukan kriteria yang jauh lebih luas. Filter ini memungkinkan Anda menyaring pencarian berdasarkan jenis properti, lokasi, kisaran harga, jumlah kamar, dan detail tambahan seperti apakah hewan peliharaan diperbolehkan, tahun pembangunan, atau jenis sistem pemanas.
Opsi lanjutan mencakup pengecualian jenis properti tertentu, pemfilteran berdasarkan efisiensi energi, atau bahkan menentukan kecepatan internet minimum. Fleksibilitas ini memungkinkan Anda dengan mudah mengekstrak data yang Anda butuhkan untuk analisis Anda.
Untuk mempersonalisasi kueri sesuai dengan filter yang diperlukan, alamat kueri perlu diubah. Secara default, string pencarian terlihat seperti ini:
https://www.immobilienscout24.de/Suche/de/Mari siapkan skrip dasar yang memungkinkan kita membuat tautan yang diperlukan secara dinamis. Kebanyakan filter dasar ditempatkan sebagai variabel. Kami memilih Python sebagai bahasa pemrograman karena paling cocok untuk mengembangkan skrip scraping.
Untuk memulai, kita akan membuat variabel tempat kita menyimpan URL dasar untuk pencarian properti:
base_url = "https://www.immobilienscout24.de/Suche/de/"Selanjutnya, kami memperkenalkan variabel untuk mewakili filter pencarian yang berbeda. Kami juga akan menambahkan komentar untuk menjelaskan tujuannya:
state = "baden-wuerttemberg" # State in Germany
city = "stuttgart" # City
district_1 = "degerloch" # Main district
district_2 = "degerloch" # Sub-district (optional)
property_type = "wohnung" # Property type (e.g., 'wohnung' for apartment)
features = "mit-balkon" # Specific features (e.g., 'mit-balkon' for with balcony)
action = "mieten" # Action (e.g., 'mieten' for rent, 'kaufen' for buy)
price_type = "rentpermonth" # Pricing type (e.g., 'rentpermonth', 'totalprice')
origin = "result_list" # Origin of the search (usually 'result_list' when the search comes from the result list)Pada akhirnya kami akan menggabungkan variabel-variabel ini menjadi tautan umum:
constructed_url = (
f"{base_url}{state}/{city}/{district_1}/{district_2}/"
f"{property_type}-{features}-{action}?"
f"pricetype={price_type}&enteredFrom={origin}"
)Pendekatan ini memungkinkan kami menyesuaikan kueri secara lebih efektif di masa mendatang hanya dengan mengubah variabel. Ini adalah metode yang lebih nyaman dan mengurangi pekerjaan manual. Namun jika perlu, Anda tetap dapat memasukkan URL pengumpulan data akhir secara manual. Jika halaman hasil pencarian tidak memberikan informasi yang cukup, Anda selalu bisa mendapatkan data yang diperlukan dari halaman daftar tertentu. Secara umum, halaman properti individual berisi informasi berikut:
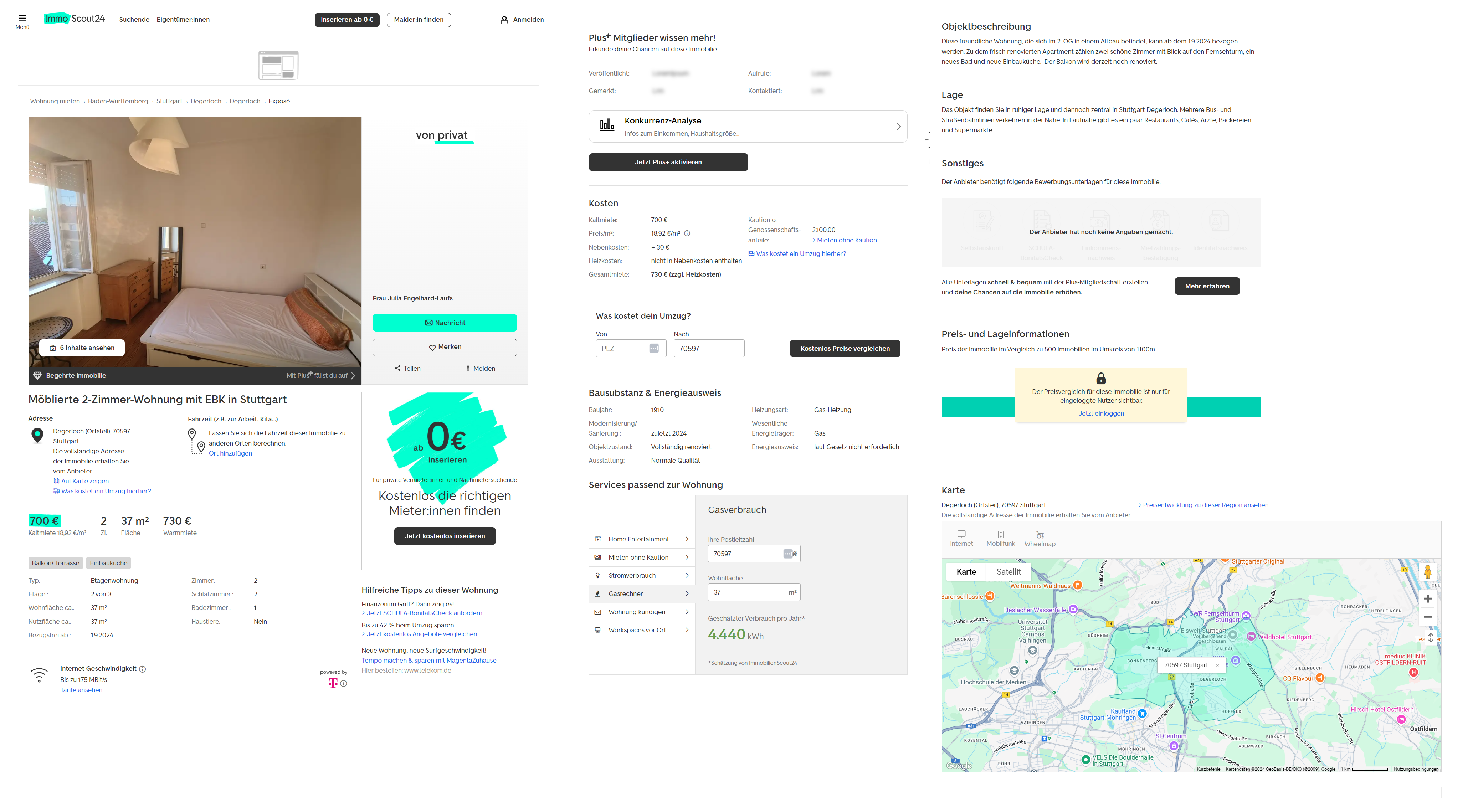
Seperti yang Anda lihat, ada lebih banyak informasi yang tersedia untuk Anda di halaman daftar. Bahkan tanpa data, yang hanya tersedia bagi pengguna terdaftar dengan akun “Plus”, tingkat detailnya masih jauh lebih tinggi.
Dalam contoh di masa depan, kita akan mempelajari pengikisan halaman hasil pencarian umum dan daftar real estat individual.
Memilih metode pengikisan web
Sebelum kita mendalami contoh spesifik pengikisan data, mari kita uraikan berbagai metode yang tersedia untuk mengekstrak informasi yang Anda perlukan. Pendekatan optimal bergantung pada keterampilan teknis Anda, tugas yang ada, dan waktu yang ingin Anda investasikan dalam pengumpulan data. Untuk menghapus ImmobilienScout24.de Anda dapat mempertimbangkan opsi berikut:
- Ekstraksi data secara manual. Meskipun ini adalah metode yang paling tidak efisien, namun tidak memerlukan pengetahuan teknis apa pun. Cocok untuk pengumpulan data skala kecil satu kali dari beberapa entri.
- Penggunaan API ImmoScout24. Platform ini menawarkan berbagai API yang memungkinkan interaksi dengan kontennya. Detail lebih lanjut dapat ditemukan di situs resmi pengembang. Namun, penggunaan API ini untuk pengumpulan data dapat menimbulkan tantangan tertentu:
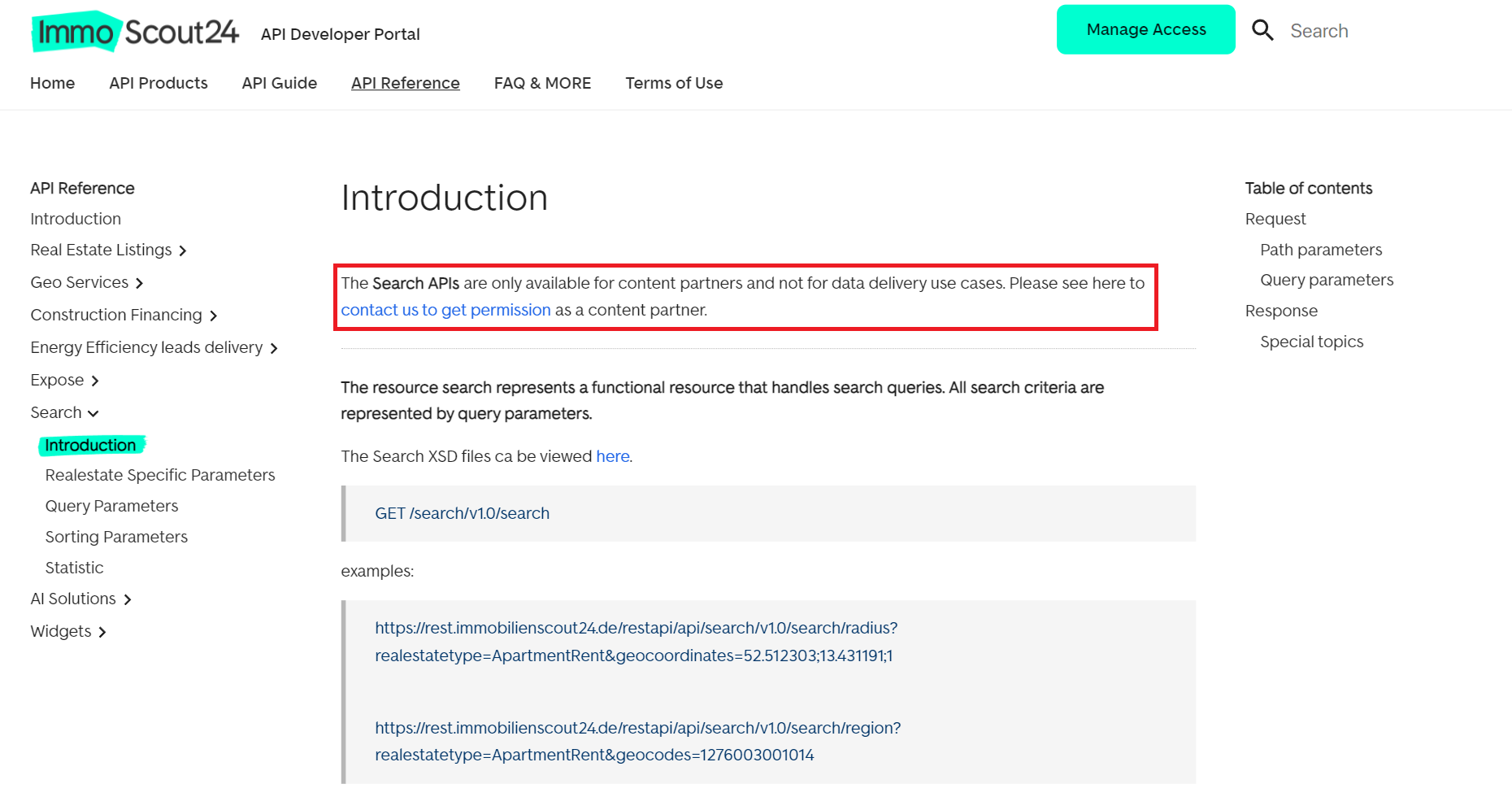
- Penggunaan API pihak ketiga. Pertimbangkan untuk menggunakan alat pihak ketiga yang dirancang untuk ekstraksi data real estat. Opsi ini seringkali lebih sederhana dan tidak terlalu membatasi. Selain itu, ini dapat membantu menghindari hambatan gesekan yang umum.
- Membuat scraper khusus. Ini melibatkan pengembangan scraper dari awal menggunakan bahasa pemrograman pilihan Anda. Bersiaplah untuk mengatasi tantangan seperti CAPTCHA, yang sering digunakan ImmoScout24 untuk mendeteksi aktivitas mencurigakan.
Pada artikel ini, kita akan mempelajari cara mengikis data real estate dari ImmoScout24 menggunakan API HasData dan membahas cara membuat scraper Python khusus menggunakan pustaka seperti Requests, BeautifulSoup4, dan Selenium.
Mengikis data dari daftar real estat
Mari kita mulai panduan kita dengan menjelajahi metode untuk mengambil data Immoscout24 dari daftar real estat. Untuk mengotomatiskan proses menghasilkan URL yang diperlukan, kami menggunakan skrip yang telah dibahas sebelumnya.
Setiap metode ekstraksi data memiliki kelebihan dan kekurangannya masing-masing. Penting untuk dicatat bahwa menggunakan perpustakaan seperti BeautifulSoup dan Requests secara langsung kemungkinan besar tidak akan memberikan hasil yang sukses karena Anda akan sering menemukan CAPTCHA. Oleh karena itu, fokus utama kami adalah API web scraping dan perpustakaan Selenium yang dapat mensimulasikan perilaku manusia.
Menggunakan Permintaan dan BeautifulSoup
Seperti disebutkan sebelumnya, karena berbagai tantangan teknis, kecil kemungkinannya bahwa ekstraksi data menggunakan Permintaan dan BeautifulSoup dari situs web khusus ini akan berhasil. Namun, untuk mengilustrasikannya, mari kita jelajahi bagaimana hal ini dapat dilakukan dengan memperluas skrip kita sebelumnya.
Impor perpustakaan terlebih dahulu:
import requests
from bs4 import BeautifulSoupSetelah Anda membuat tautan, atur agen pengguna di header permintaan dan aktifkan untuk melihat sumber halaman atau pesan kesalahan apa pun:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36",
}
response = requests.get(constructed_url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())
else:
print(f"Failed to retrieve the page. Status code: {response.status_code}")Daripada mengambil semua kode laman web, kami menggunakan pemilih CSS untuk mendeteksi dan mengekstrak hanya data persis yang kami perlukan:
soup = BeautifulSoup(response.text, 'html.parser')
properties = soup.select(".grid-item.result-list-entry__data-container")
for property in properties:
title = property.select_one(".result-list-entry__brand-title").text.strip()
price = property.select_one(".result-list-entry__primary-criterion dd").text.strip()
area = property.select("dl.result-list-entry__primary-criterion dd")(1).text.strip()
rooms = property.select("dl.result-list-entry__primary-criterion dd")(2).text.strip()
location = property.select_one(".result-list-entry__address").text.strip()
print(f"Title: {title}")
print(f"Price: {price}")
print(f"Area: {area}")
print(f"Rooms: {rooms}")
print(f"Location: {location}")
print("-" * 50)Sayangnya, mencoba menjalankan kode ini menghasilkan kesalahan 401. Saat memeriksa kode sumber halaman, Anda akan melihat permintaan untuk memecahkan CAPTCHA atau bahkan informasi tentang blok tersebut. Seperti yang telah kami peringatkan pada awalnya, pendekatan ini dipelajari semata-mata untuk tujuan teoretis dan karena rasa ingin tahu tentang potensi kelayakannya.
Menggunakan API Pengikisan Web
Metode kedua yang kami jelajahi melibatkan penggunaan Web Scraping API HasData, yang dapat melewati tindakan anti-bot seperti pemblokiran dan CAPTCHA. API ini sangat ramah pengguna dan oleh karena itu cocok untuk pemrogram dari semua tingkat keahlian.
Secara keseluruhan, ini sangat mirip dengan contoh sebelumnya, hanya saja permintaan ke situs web dilakukan melalui API. Selain itu, Google Colaboratory memungkinkan Anda melihat dan menjalankan skrip yang sudah dibuat sebelumnya.
Pertama, mari impor perpustakaan yang diperlukan:
import request
import json
from bs4 import BeautifulSoupSelanjutnya, kami menetapkan kunci HasData API dan URL halaman daftar properti kami. Anda dapat menggunakan kode dari contoh sebelumnya untuk menghasilkan URL ini, namun kami akan mengaturnya secara manual di sini untuk menghindari pengulangan:
api_key = "YOUR-API-KEY"
scout_url = "https://www.immobilienscout24.de/Suche/de/baden-wuerttemberg/stuttgart/degerloch/degerloch/wohnung-mit-balkon-mieten?pricetype=rentpermonth&enteredFrom=result_list"Anda bisa mendapatkan kunci API HasData dari akun Anda setelah masuk ke situs web kami.
Tetapkan header dan titik akhir untuk Web Scraping API:
api_url = "https://api.hasdata.com/scrape/web"
headers = {
'Content-Type': 'application/json',
'x-api-key': api_key
}Kemudian kami mengatur parameter untuk permintaan itu sendiri. Secara khusus, kami menggunakan proxy perumahan Jerman untuk mengurangi risiko pemblokiran dan mengaktifkan eksekusi JavaScript di situs:
payload = json.dumps({
"url": scout_url,
"proxyType": "residential",
"proxyCountry": "DE",
"blockResources": False,
"blockAds": False,
"blockUrls": (),
"jsScenario": (),
"screenshot": False,
"jsRendering": True,
"excludeHtml": False,
"extractEmails": False,
"wait": 10
})Sekarang yang tersisa hanyalah menjalankan permintaan dan mengurai HTML halaman dengan BeautifulSoup:
response = requests.post(api_url, headers=headers, data=payload)
if response.status_code == 200:
response_data = response.json()
html_content = response_data.get("content")
if html_content:
soup = BeautifulSoup(html_content, 'html.parser')
properties = soup.select(".grid-item.result-list-entry__data-container")
data = ()
for property in properties:
title = property.select_one(".result-list-entry__brand-title").get_text(strip=True)
price = property.select_one("dl.result-list-entry__primary-criterion dd").get_text(strip=True)
area = property.select("dl.result-list-entry__primary-criterion dd")(1).get_text(strip=True)
rooms = property.select("dl.result-list-entry__primary-criterion dd")(2).get_text(strip=True)
location = property.select_one(".result-list-entry__address").get_text(strip=True)
data.append((title, price, area, rooms, location))
print(f"Title: {title}")
print(f"Price: {price}")
print(f"Area: {area}")
print(f"Rooms: {rooms}")
print(f"Location: {location}")
print("-" * 50)
else:
print("Failed to retrieve HTML content.")
else:
print(f"API request failed: {response.status_code}, error message: {response.text}")Hasilnya, setelah menjalankan skrip, kami mendapatkan data berikut:
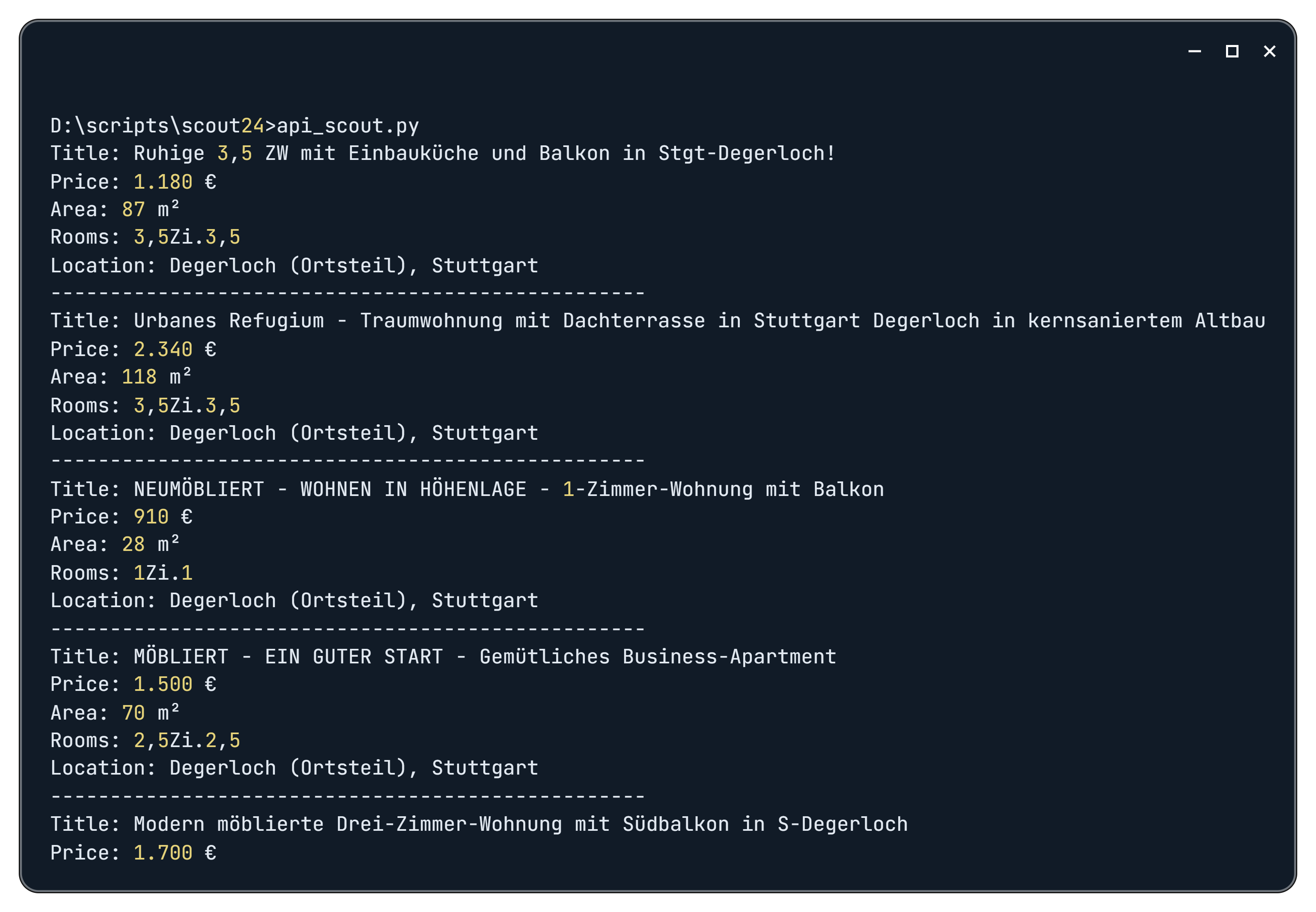
Untuk meningkatkan analisis Anda terhadap tren pasar, pertimbangkan untuk mengintegrasikan web scraping ke dalam skrip. Teknik ini dapat digunakan untuk mengambil data tambahan, misalnya. B. Informasi dari agen real estate atau rincian relevan lainnya. Untuk menerapkannya, cukup tentukan variabel baru dengan pemilih CSS yang sesuai untuk elemen yang diinginkan.
Menggunakan Selenium untuk konten dinamis
Metode terakhir yang akan kita jelajahi melibatkan penggunaan versi perpustakaan Selenium yang dimodifikasi dan browser tanpa kepala untuk pengumpulan data. Sebelum kita mempelajari skrip itu sendiri, mari kita periksa apa yang terjadi ketika kita menavigasi ke situs pencarian real estate menggunakan Selenium.
Untuk melakukan ini, kami mengimpor perpustakaan yang diperlukan, menavigasi ke situs web dan melakukan penundaan singkat:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
chrome_options = Options()
driver = webdriver.Chrome(options=chrome_options)
url = "https://www.immobilienscout24.de/Suche/de/baden-wuerttemberg/stuttgart/degerloch/degerloch/wohnung-mit-balkon-mieten?pricetype=rentpermonth&enteredFrom=result_list"
driver.get(url)
time.sleep(10)
driver.quit()Selama eksekusi skrip, kami menemukan kesalahan 401 di Scout24 serta peringatan bahwa aktivitas kami tampak mencurigakan dan seperti robot. Jika terjadi kesalahan, mereka memberikan kode permintaan dan meminta kami menghubungi dukungan.
Sayangnya, seperti yang Anda lihat, driver web Selenium dengan jelas diidentifikasi sebagai bot dan bahkan CAPTCHA pun tidak ditawarkan. Namun, ada solusi untuk hal ini. SeleniumBase, versi Selenium yang dimodifikasi, dapat membantu kita mengatasi masalah tersebut.
SeleniumBase terutama digunakan oleh penguji dan bagus untuk menjalankan pengujian. Namun demikian, ia menawarkan fungsi yang memungkinkan kita melewati mekanisme pemblokiran Scout24. Mode UC (Mode Chromedriver Tidak Terdeteksi) SeleniumBase memungkinkan bot meniru perilaku manusia, memungkinkan mereka melewati sistem anti-bot yang mencoba memblokirnya atau memicu CAPTCHA. Namun, ini mungkin tidak cukup karena situs web sering kali memerlukan penyelesaian CAPTCHA.
Kami memiliki beberapa opsi:
- Gunakan proxy perumahan Jerman.
- Gunakan layanan penyelesaian CAPTCHA.
- Selesaikan CAPTCHA secara manual dan simpan cookie, data sesi, dan penyimpanan lokal untuk dipulihkan nanti.
Kami memilih pendekatan yang terakhir. Pertama kita perlu mengunjungi situsnya, menyelesaikan CAPTCHA dan menyimpan datanya. Kami menggunakan skrip terpisah untuk ini:
from seleniumbase import SB
import pickle
import time
with SB(uc=True) as sb:
sb.open("https://www.immobilienscout24.de/Suche/de/baden-wuerttemberg/stuttgart/degerloch/degerloch/wohnung-mit-balkon-mieten?pricetype=rentpermonth&enteredFrom=result_list")
time.sleep(20)
cookies = sb.get_cookies()
with open('cookies.pkl', 'wb') as file:
pickle.dump(cookies, file)
local_storage = sb.execute_script("return JSON.stringify(window.localStorage);")
with open('local_storage.json', 'w', encoding='utf-8') as file:
file.write(local_storage)
session_storage = sb.execute_script("return JSON.stringify(window.sessionStorage);")
with open('session_storage.json', 'w', encoding='utf-8') as file:
file.write(session_storage)Kami telah memperkenalkan penundaan 20 detik untuk memberi Anda cukup waktu untuk menyelesaikan CAPTCHA. Meskipun Anda bukan orang Jerman, Anda dapat dengan mudah menyelesaikannya dengan memilih gambar yang paling banyak muncul.
Selanjutnya, kita membuat skrip baru di mana kita mengimpor data yang disimpan sebelumnya dan kemudian mengurai halaman yang diperlukan seperti pada contoh sebelumnya:
from selenium.webdriver.common.by import By
from seleniumbase import SB
import pickle
import csv
import json
with SB(uc=True) as sb:
sb.open("https://www.immobilienscout24.de")
with open('cookies.pkl', 'rb') as file:
cookies = pickle.load(file)
for cookie in cookies:
sb.add_cookie(cookie)
with open('local_storage.json', 'r', encoding='utf-8') as file:
local_storage = file.read()
sb.execute_script(f"var items = JSON.parse(arguments(0)); for (var key in items) {{ window.localStorage.setItem(key, items(key)); }}", local_storage)
with open('session_storage.json', 'r', encoding='utf-8') as file:
session_storage = file.read()
sb.execute_script(f"var items = JSON.parse(arguments(0)); for (var key in items) {{ window.sessionStorage.setItem(key, items(key)); }}", session_storage)
sb.open("https://www.immobilienscout24.de/Suche/de/baden-wuerttemberg/stuttgart/degerloch/degerloch/wohnung-mit-balkon-mieten?pricetype=rentpermonth&enteredFrom=result_list")
properties = sb.find_elements(By.CSS_SELECTOR, ".grid-item.result-list-entry__data-container")
for property in properties:
title = property.find_element(By.CSS_SELECTOR, ".result-list-entry__brand-title").text.strip()
price = property.find_element(By.CSS_SELECTOR, "dl.result-list-entry__primary-criterion dd").text.strip()
area = property.find_elements(By.CSS_SELECTOR, "dl.result-list-entry__primary-criterion dd")(1).text.strip()
rooms = property.find_elements(By.CSS_SELECTOR, "dl.result-list-entry__primary-criterion dd")(2).text.strip()
location = property.find_element(By.CSS_SELECTOR, ".result-list-entry__address").text.strip()
print(f"Title: {title}")
print(f"Price: {price}")
print(f"Area: {area}")
print(f"Rooms: {rooms}")
print(f"Location: {location}")
print("-" * 50)Karena data yang diperoleh sangat cocok dengan hasil HasData API sebelumnya, kami menahan diri dari analisis skrip secara mendetail. Hebatnya, pendekatan ini secara efektif mengatasi sebagian besar tantangan saat menghapus ImmobillenScout24.de.
Untuk keandalan maksimum, disarankan untuk melengkapi skrip dengan proxy Jerman dan layanan penyelesaian CAPTCHA. Meskipun efektif, metode ini tidak menjamin perlindungan penuh terhadap penyumbatan.
Pengikisan data real estat
Pengikisan data real estat memiliki banyak kesamaan dengan pengumpulan data dari listingan real estat. Perbedaan utamanya terletak pada elemen dan tautan spesifik yang perlu dibidik.
Karena kita telah membahas tantangan pengikisan real estat yang umum, mari selami contoh praktis menggunakan HasData dan SeleniumBase API. Hal ini memungkinkan kita untuk mengabaikan pendekatan yang lebih mendasar dengan Requests dan BeautifulSoup.
Menggunakan API Pengikisan Web
Mari kita mulai dengan metode yang lebih sederhana menggunakan Web Scraping API HasData. Seperti sebelumnya, Anda memerlukan kunci API pribadi, yang akan Anda terima dari akun Anda setelah mendaftar di situs web kami.
Anda juga dapat menemukan, menjalankan, dan bereksperimen dengan skrip bawaan di Colab Research.
Sebagian besar skrip yang berinteraksi dengan API HasData tetap tidak berubah, kecuali tautan halaman:
from bs4 import BeautifulSoup
import requests
import json
import csv
api_key = "YOUR-API-KEY"
scout_url = "https://www.immobilienscout24.de/expose/153073358?referrer=RESULT_LIST_LISTING&searchId=cb9e25ee-fcc3-3365-be73-71e453b7abf5&searchUrl=%2Fde%2Fbaden-wuerttemberg%2Fstuttgart%2Fdegerloch%2Fdegerloch%2Fwohnung-mit-balkon-mieten%3Fpricetype%3Drentpermonth&searchType=district&fairPrice=FAIR_OFFER#/"
api_url = "https://api.hasdata.com/scrape/web"
headers = {
'Content-Type': 'application/json',
'x-api-key': api_key
}
payload = json.dumps({
"url": scout_url,
"proxyType": "residential",
"proxyCountry": "DE",
"blockResources": False,
"blockAds": False,
"blockUrls": (),
"jsScenario": (),
"screenshot": False,
"jsRendering": True,
"excludeHtml": False,
"extractEmails": False,
"wait": 10
})
response = requests.post(api_url, headers=headers, data=payload)
if response.status_code == 200:
response_data = response.json()
html_content = response_data.get("content")
if html_content:
soup = BeautifulSoup(html_content, 'html.parser')
# Here will be another code
else:
print("Failed to retrieve HTML content.")
else:
print(f"API request failed: {response.status_code}, error message: {response.text}")Namun, pemilih untuk data yang ingin kita ekstrak perlu diubah:
data = {}
title = soup.find('h1', id='expose-title')
data('title') = title.get_text(strip=True) if title else None
address = soup.find('span', class_='zip-region-and-country')
data('address') = address.get_text(strip=True) if address else None
cold_rent = soup.find('div', class_='is24qa-kaltmiete-main is24-value font-semibold')
data('cold_rent') = cold_rent.get_text(strip=True) if cold_rent else None
warm_rent = soup.find('div', class_='is24qa-warmmiete-main is24-value font-semibold')
data('warm_rent') = warm_rent.get_text(strip=True) if warm_rent else None
area = soup.find('div', class_='is24qa-flaeche-main is24-value font-semibold')
data('area') = area.get_text(strip=True) if area else None
rooms = soup.find('div', class_='is24qa-zi-main is24-value font-semibold')
data('rooms') = rooms.get_text(strip=True) if rooms else None
floor = soup.find('dd', class_='is24qa-etage')
data('floor') = floor.get_text(strip=True) if floor else None
availability = soup.find('dd', class_='is24qa-bezugsfrei-ab')
data('availability') = availability.get_text(strip=True) if availability else None
for key, value in data.items():
print(f"{key}: {value}")Hasilnya kami mendapatkan data berikut:

Karena halaman berisi banyak data, Anda dapat menambahkan semua variabel dan penyeleksi yang Anda perlukan ke skrip untuk mengekstrak semua informasi yang diperlukan tentang properti tertentu.
Menggunakan Selenium untuk konten dinamis
Jika kita menggunakan Selenium, atau lebih spesifiknya SeleniumBase, sebagian besar prosesnya tetap sama. Yang perlu kita lakukan hanyalah mengganti URL pencarian dan memperbarui pemilihnya. Sebagian besar skrip tetap tidak berubah:
from selenium.webdriver.common.by import By
from seleniumbase import SB
import pickle
import csv
with SB(uc=True) as sb:
sb.open("https://www.immobilienscout24.de")
with open('cookies.pkl', 'rb') as file:
cookies = pickle.load(file)
for cookie in cookies:
sb.add_cookie(cookie)
with open('local_storage.json', 'r', encoding='utf-8') as file:
local_storage = file.read()
sb.execute_script(f"var items = JSON.parse(arguments(0)); for (var key in items) {{ window.localStorage.setItem(key, items(key)); }}", local_storage)
with open('session_storage.json', 'r', encoding='utf-8') as file:
session_storage = file.read()
sb.execute_script(f"var items = JSON.parse(arguments(0)); for (var key in items) {{ window.sessionStorage.setItem(key, items(key)); }}", session_storage)
sb.open("https://www.immobilienscout24.de/expose/153073358?referrer=RESULT_LIST_LISTING&searchId=cb9e25ee-fcc3-3365-be73-71e453b7abf5&searchUrl=%2Fde%2Fbaden-wuerttemberg%2Fstuttgart%2Fdegerloch%2Fdegerloch%2Fwohnung-mit-balkon-mieten%3Fpricetype%3Drentpermonth&searchType=district&fairPrice=FAIR_OFFER#/") Kami hanya mengubah bagian tempat kami mengekstrak data yang diperlukan:
data = {}
title = sb.get_text("h1#expose-title")
data('title') = title.strip() if title else None
address = sb.get_text("span.zip-region-and-country")
data('address') = address.strip() if address else None
cold_rent = sb.get_text("div.is24qa-kaltmiete-main.is24-value.font-semibold")
data('cold_rent') = cold_rent.strip() if cold_rent else None
warm_rent = sb.get_text("div.is24qa-warmmiete-main.is24-value.font-semibold")
data('warm_rent') = warm_rent.strip() if warm_rent else None
area = sb.get_text("div.is24qa-flaeche-main.is24-value.font-semibold")
data('area') = area.strip() if area else None
rooms = sb.get_text("div.is24qa-zi-main.is24-value.font-semibold")
data('rooms') = rooms.strip() if rooms else None
floor = sb.get_text("dd.is24qa-etage")
data('floor') = floor.strip() if floor else None
availability = sb.get_text("dd.is24qa-bezugsfrei-ab")
data('availability') = availability.strip() if availability else None
for key, value in data.items():
print(f"{key}: {value}")Namun sebelum menjalankan skrip ini, pastikan untuk menjalankan skrip yang Anda buat sebelumnya yang menyimpan cookie, data sesi, dan penyimpanan lokal. Selain itu, kami menyarankan untuk membuat variabel atau file untuk menyimpan semua URL yang diperlukan untuk pengikisan. Ini memungkinkan Anda mengulangi URL ini dalam satu skrip.
Menyimpan data yang tergores
Pada contoh sebelumnya, kami menggunakan instruksi pencetakan sederhana untuk menampilkan data di layar. Meskipun nyaman untuk peninjauan cepat, namun tidak praktis untuk penyimpanan atau pembagian jangka panjang. Mari kita lihat bagaimana kita menyimpan data kita dalam file.
Dua format file umum untuk menyimpan data terstruktur adalah JSON dan CSV. Untuk bekerja dengan format ini kita perlu mengimpor pustaka Python yang sesuai: json dan csv.
import csv
import jsonFile nilai yang dipisahkan koma (CSV) adalah file teks biasa yang menyimpan data tabular dalam format yang dapat dibaca manusia. Setiap baris dalam file CSV mewakili sebuah baris, dan setiap nilai dalam sebuah baris dipisahkan dengan koma:
with open('property_details.csv', mode="w", newline="", encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(data.keys())
writer.writerow(data.values())Pernyataan with memastikan bahwa file ditutup dengan benar meskipun terjadi pengecualian. Objek csv.writer menyediakan metode untuk menulis baris ke file CSV.
JSON (JavaScript Object Notation) adalah format pertukaran data sederhana yang mudah dibaca dan ditulis oleh manusia dan mudah diurai dan dihasilkan oleh mesin:
with open('property_details.json', mode="w", encoding='utf-8') as file:
json.dump(data, file, ensure_ascii=False, indent=4)Itu json.dump() Fungsi mengubah objek Python (dalam hal ini data) menjadi string JSON dan menulisnya ke file yang ditentukan. Itu ensure_ascii=False Argumen ini memungkinkan pengkodean karakter non-ASCII yang benar dan indent=4 menambahkan lekukan agar mudah dibaca.
Kesimpulan dan temuan
Artikel ini membahas tantangan dan solusi yang terkait dengan web scraping dari ImmobilienScout24.de. Kami telah menjelajahi sejumlah teknik dan alat untuk mengekstrak data secara efektif dari platform ini dan memberikan contoh praktis serta cuplikan kode.
Hasil kami menunjukkan bahwa API web scraping khusus memberikan pendekatan yang paling kuat dan nyaman. Dengan memanfaatkan API ini, pengembang dapat menyederhanakan proses ekstraksi data dan tidak lagi harus berurusan dengan pemblokiran situs web, CAPTCHA, dan hambatan umum lainnya.
Bagi mereka yang menginginkan kontrol yang lebih terperinci atas proses pengikisan, kami juga memeriksa Selenium Base. Namun, penting untuk dicatat bahwa penggunaan Selenium Base sering kali memerlukan tindakan tambahan seperti server proxy dan layanan penyelesaian CAPTCHA untuk memastikan stabilitas dan keandalan skrip.
