
Dalam tutorial ini, kami akan membuat web scraper Walmart dari awal dan menunjukkan cara mudah melewati deteksi anti-botnya tanpa merusak servernya.
TL;DR: Pengikis Walmart Node.js lengkap
Bagi yang terburu-buru, berikut kode lengkap di Node.js.
<pre class="wp-block-syntaxhighlighter-code">
const axios = require('axios');
const cheerio = require('cheerio');
const WALMART_PAGE_URL = 'https://walmart.com/search?q=computer+screen';
const API_URL = 'https://api.scraperapi.com';
const API_KEY = '<API_KEY>' // <--- Enter your API key here
const parseProductReview = (inputString) => {
const ratingRegex = /(\d+\.\d+)/;
const reviewCountRegex = /(\d+) reviews/;
const ratingMatch = inputString.match(ratingRegex);
const reviewCountMatch = inputString.match(reviewCountRegex);
const rating = ratingMatch?.length > 0 ? parseFloat(ratingMatch(0)) : null;
const reviewCount = reviewCountMatch?.length > 1 ? parseInt(reviewCountMatch(1)) : null;
return { rating, reviewCount };
};
const webScraper = async () => {
const queryParams = new URLSearchParams({
api_key: API_KEY,
url: WALMART_PAGE_URL,
render: true,
});
try {
const response = await axios.get(`${API_URL}?${queryParams.toString()}`);
const html = response.data;
const $ = cheerio.load(html);
const productList = ();
$("div(data-testid='list-view')").each((_, el) => {
co
nst link = $(el).prev('a').attr('href');
const price = $(el).find('.f2').text();
const priceCents = $(el).find('.f2 + span.f6').text();
const description = $(el).find("span(data-automation-id='product-title')").text();
const reviews = $(el).find('.w_iUH7').last().text();
const delivery = $(el).find("div(data-automation-id='fulfillment-badge')").find('span.b').last().text();
const { rating, reviewCount } = parseProductReview(reviews);
productList.push({
description,
price: `$${price}.${priceCents}`,
averageRating: rating,
totalReviews: reviewCount,
delivery,
link: `https://www.walmart.com${link}`
});
});
console.log(productList);
} catch (error) {
console.log(error.response.data)
}
};
void webScraper();
</pre>
Sebelum menjalankan kode ini, instal dependensi dan atur kunci API Anda, yang dapat Anda temukan di dasbor ScraperAPI - ini penting karena ScraperAPI memungkinkan kami melewati mekanisme anti-bot Walmart dan menyajikan konten dinamisnya.
Catatan: Uji coba gratis mencakup 5.000 kredit API dan akses ke semua alat ScraperAPI.
Apakah Anda ingin mengetahui detailnya? Mari kita mulai tutorialnya!
Mengikis data produk Walmart di Node.js
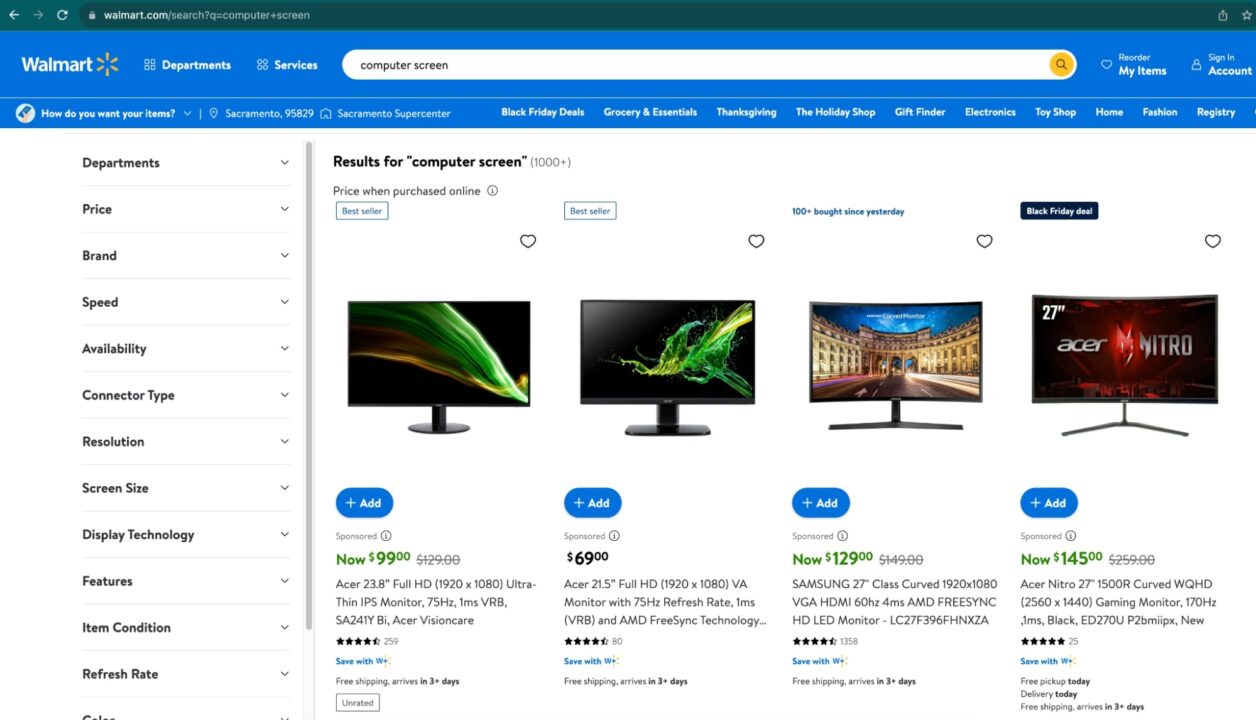
Untuk mendemonstrasikan cara menelusuri Walmart, mari tulis skrip yang menemukan layar komputer di Walmart.
Untuk setiap layar komputer kami mengekstrak yang berikut ini:
- Keterangan
- Harga
- Penilaian rata-rata
- Peringkat Keseluruhan
- Estimasi pengiriman
- Tautan produk
Script mengekspor data yang diekstraksi dalam format JSON agar lebih mudah digunakan untuk tujuan lain.
persyaratan
Untuk mengikuti tutorial ini, Anda harus menginstal alat-alat ini di komputer Anda.
Langkah 1: Siapkan proyek
Mari buat folder dengan kode sumber scraper Walmart.
Masuk ke folder dan inisialisasi proyek Node.js baru
cd walmart-scraper
npm init -y
Perintah kedua di atas membuatnya paket.json File dalam folder.
Selanjutnya, buat file indeks.js dan tambahkan pernyataan JavaScript sederhana di dalamnya.
touch index.js
echo "console.log('Hello world!');" > index.js
Jalankan filenya indeks.js dengan lingkungan runtime Node.js.
Dalam eksekusi ini a dicetak Hello world! Pesan ke terminal.
Langkah 2: Instal dependensi
Untuk membuat scraper ini kita memerlukan dua paket Node.js berikut:
- Axios – untuk membuat permintaan HTTP (header, isi, parameter string kueri, dll.), kirimkan ke API standar ScraperAPI, dan unduh konten HTML
- Cheerio – untuk mengekstrak informasi dari HTML yang diunduh dari permintaan Axios
Jalankan perintah berikut untuk menginstal paket-paket ini:
npm install axios cheerio
Langkah 3: Identifikasi pemilih DOM yang ingin Anda targetkan
Navigasi ke https://www.walmart.com; Jenis "Layar komputer" di bilah pencarian dan tekan Enter.
Saat hasil pencarian muncul, periksa halaman untuk melihat struktur HTML dan identifikasi pemilih DOM yang terkait dengan tag HTML yang membungkus informasi yang ingin kita ekstrak.
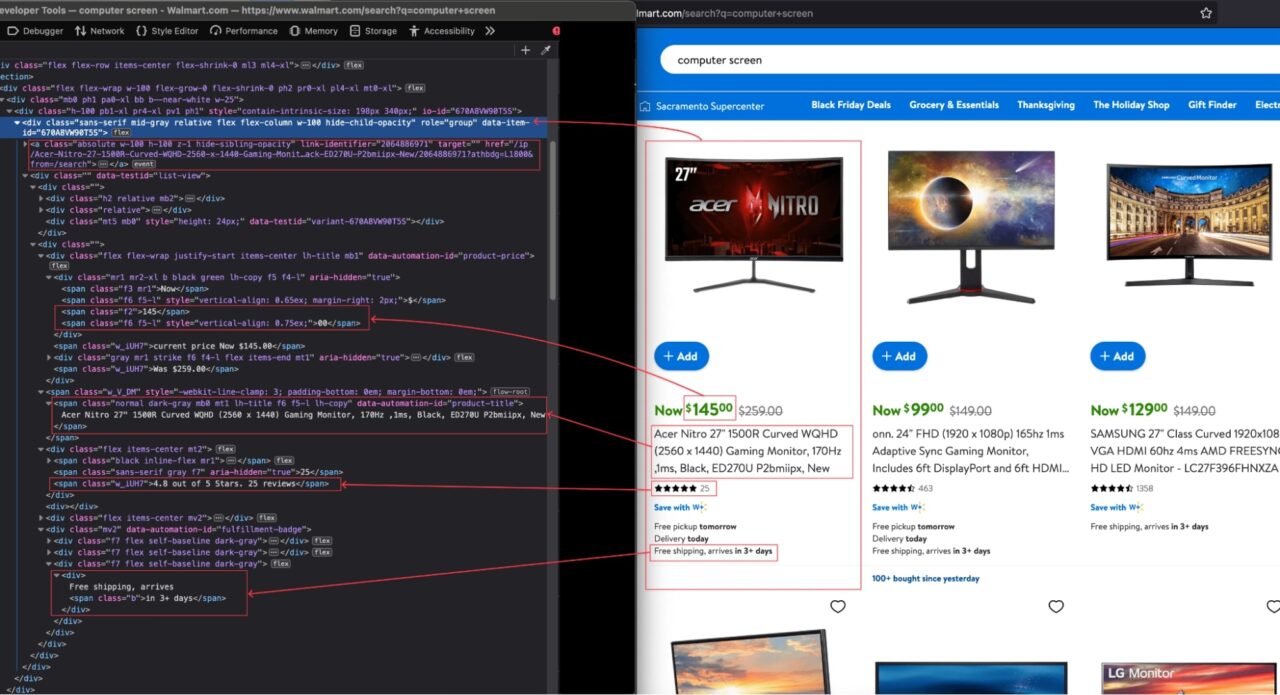
Pada gambar di atas, berikut adalah semua pemilih DOM yang akan ditargetkan oleh web scraper untuk mengekstrak informasi.
| informasi | pemilih DOM |
| Deskripsi Produk | span(data-automation-id='judul-produk') |
| Harga | div(data-testid='tampilan-daftar') .f2 |
| Harga sen | div(data-testid='tampilan-daftar') .f2 + span.f6 |
| Penilaian rata-rata | div(data-testid='tampilan-daftar') span.w_V_DM + div.flex span.w_iUH7 |
| Peringkat Keseluruhan | div(data-testid='tampilan-daftar') span.w_V_DM + div.flex span.f7 |
| Estimasi pengiriman | div(data-testid='tampilan-daftar') div(data-automation-id='lencana-pemenuhan') div.f7:anak-terakhir span.b:anak-terakhir |
| Tautan Walmart | div + a |
Berhati-hatilah saat menulis pemilih karena kesalahan ejaan akan mencegah skrip mengambil nilai yang benar.
catatan: Cara yang baik untuk menghindari kesalahan saat membuat penyeleksi adalah dengan mencobanya terlebih dahulu dengan jQuery. Di konsol browser, masukkan pemilih Anda $(“span(data-automation-id=’product-title’)”) Jika elemen DOM yang benar dikembalikan, Anda siap melakukannya.
Langkah 4: Kirim permintaan pertama ke Walmart
Seperti disebutkan sebelumnya, kami menggunakan API standar ScraperAPI untuk melewati deteksi anti-bot Walmart.
Untuk membuat permintaan, kami menggunakan Axios dan meneruskan parameter berikut ke API:
- URL yang akan dikikis: Ini adalah URL halaman pencarian produk Walmart. Anda dapat menyalinnya ke bilah alamat browser Anda (dalam kasus kami
https://walmart.com/search?q=computer+screen). - Kunci API: untuk mengautentikasi ke API standar dan melakukan pengikisan. Anda dapat menemukannya di dasbor ScraperAPI Anda.
- Aktifkan JavaScript: Situs web Walmart dibangun pada kerangka front-end modern yang menambahkan JavaScript untuk interaktivitas yang lebih baik. Untuk mengaktifkan JavaScript saat melakukan scraping, kami menggunakan properti bernama
`render`dengan nilai yang ditetapkan ke`true`.
catatan: Dengan mengaktifkan rendering JS, kami dapat mengekstrak konten dinamis Walmart. Tanpa mereka kita akan mendapatkan halaman kosong.
Sunting itu indeks.js untuk menambahkan kode berikut yang membuat permintaan HTTP, mengirimkannya, menerima respons dan mencetaknya di terminal.
<pre class="wp-block-syntaxhighlighter-code">
const axios = require('axios');
const WALMART_PAGE_URL = 'https://walmart.com/search?q=computer+screen';
const API_URL = 'https://api.scraperapi.com';
const API_KEY = '<API_KEY>' // <--- Enter your API key here
const webScraper = async () => {
const queryParams = new URLSearchParams({
api_key: API_KEY,
url: WALMART_PAGE_URL,
render: true,
});
try {
const response = await axios.get(`${API_URL}?${queryParams.toString()}`);
const html = response.data;
console.log("HTML content", html);
} catch (error) {
console.log(error.response.data)
}
};
void webScraper();
</pre>
Langkah 5: Ekstrak informasi dari HTML
Sekarang kita memiliki konten HTML halaman tersebut, kita perlu menguraikannya menggunakan Cheerio agar dapat menavigasi dan mengekstrak semua informasi yang kita inginkan.
Cheerio menyediakan fungsionalitas untuk memuat teks HTML dan kemudian menavigasi struktur untuk mengekstrak informasi menggunakan pemilih DOM.
Kode berikut menelusuri setiap elemen, mengekstrak informasi, dan mengembalikan array yang berisi semua layar komputer.
const cheerio = require('cheerio');
const $ = cheerio.load(html);
const productList = ();
const parseProductReview = (inputString) => {
const ratingRegex = /(\d+\.\d+)/;
const reviewCountRegex = /(\d+) reviews/;
const ratingMatch = inputString.match(ratingRegex);
const reviewCountMatch = inputString.match(reviewCountRegex);
const rating = ratingMatch?.length > 0 ? parseFloat(ratingMatch(0)) : null;
const reviewCount = reviewCountMatch?.length > 1 ? parseInt(reviewCountMatch(1)) : null;
return { rating, reviewCount };
};
$("div(data-testid='list-view')").each((_, el) => {
const link = $(el).prev('a').attr('href');
const price = $(el).find('.f2').text();
const priceCents = $(el).find('.f2 + span.f6').text();
const description = $(el).find("span(data-automation-id='product-title')").text();
const reviews = $(el).find('.w_iUH7').last().text();
const delivery = $(el).find("div(data-automation-id='fulfillment-badge')").find('span.b').last().text();
const { rating, reviewCount } = parseProductReview(reviews);
productList.push({
description,
price: `$${price}.${priceCents}`,
averageRating: rating,
totalReviews: reviewCount,
delivery,
link: `https://www.walmart.com${link}`
});
});
console.log(productList);
Fungsinya parseProductionReview() mengekstrak peringkat rata-rata dan peringkat keseluruhan pelanggan untuk produk tersebut.
Berikut ini kode lengkapnya indeks.js Mengajukan:
<pre class="wp-block-syntaxhighlighter-code">
const axios = require('axios');
const cheerio = require('cheerio');
const WALMART_PAGE_URL = 'https://walmart.com/search?q=computer+screen';
const API_URL = 'https://api.scraperapi.com';
const API_KEY = '<API_KEY>' // <--- Enter your API key here
const parseProductReview = (inputString) => {
const ratingRegex = /(\d+\.\d+)/;
const reviewCountRegex = /(\d+) reviews/;
const ratingMatch = inputString.match(ratingRegex);
const reviewCountMatch = inputString.match(reviewCountRegex);
const rating = ratingMatch?.length > 0 ? parseFloat(ratingMatch(0)) : null;
const reviewCount = reviewCountMatch?.length > 1 ? parseInt(reviewCountMatch(1)) : null;
return { rating, reviewCount };
};
const webScraper = async () => {
const queryParams = new URLSearchParams({
api_key: API_KEY,
url: WALMART_PAGE_URL,
render: true,
});
try {
const response = await axios.get(`${API_URL}?${queryParams.toString()}`);
const html = response.data;
const $ = cheerio.load(html);
const productList = ();
$("div(data-testid='list-view')").each((_, el) => {
co
nst link = $(el).prev('a').attr('href');
const price = $(el).find('.f2').text();
const priceCents = $(el).find('.f2 + span.f6').text();
const description = $(el).find("span(data-automation-id='product-title')").text();
const reviews = $(el).find('.w_iUH7').last().text();
const delivery = $(el).find("div(data-automation-id='fulfillment-badge')").find('span.b').last().text();
const { rating, reviewCount } = parseProductReview(reviews);
productList.push({
description,
price: `$${price}.${priceCents}`,
averageRating: rating,
totalReviews: reviewCount,
delivery,
link: `https://www.walmart.com${link}`
});
});
console.log(productList);
} catch (error) {
console.log(error.response.data)
}
};
void webScraper();
</pre>
Jalankan kode menggunakan perintah node index.jsdan nikmati hasilnya:
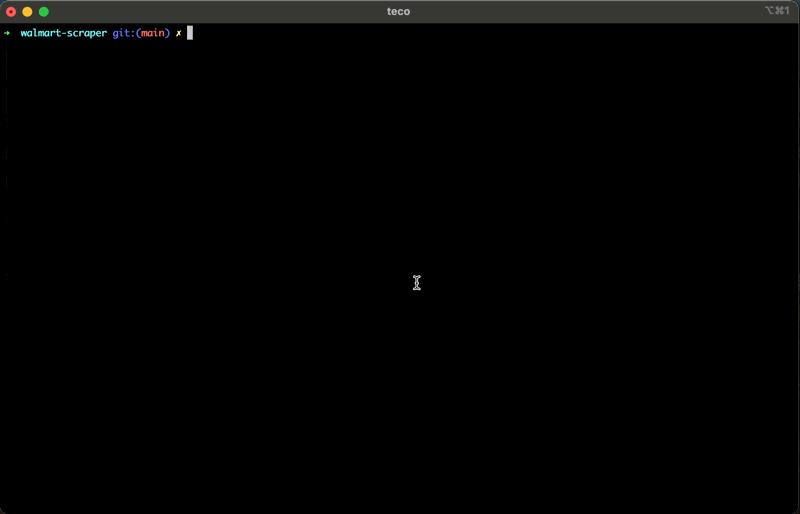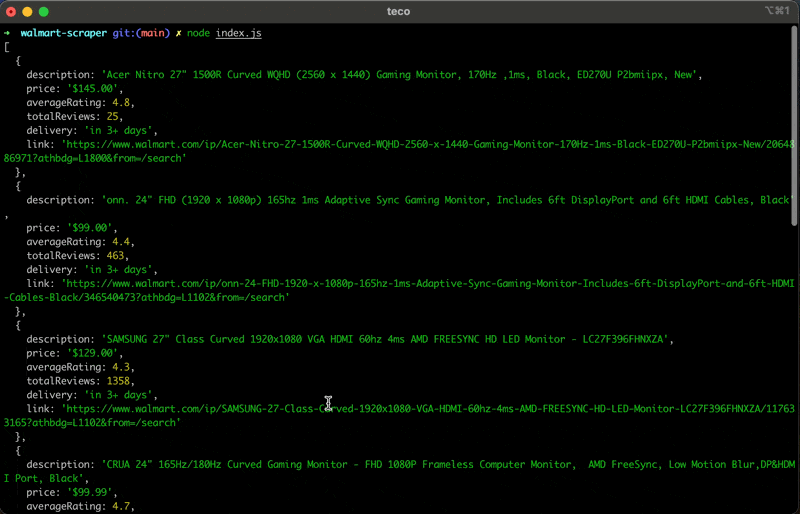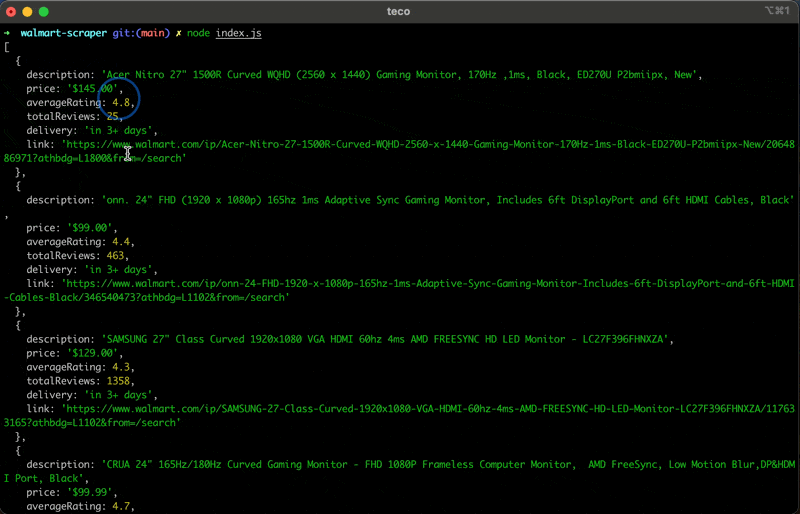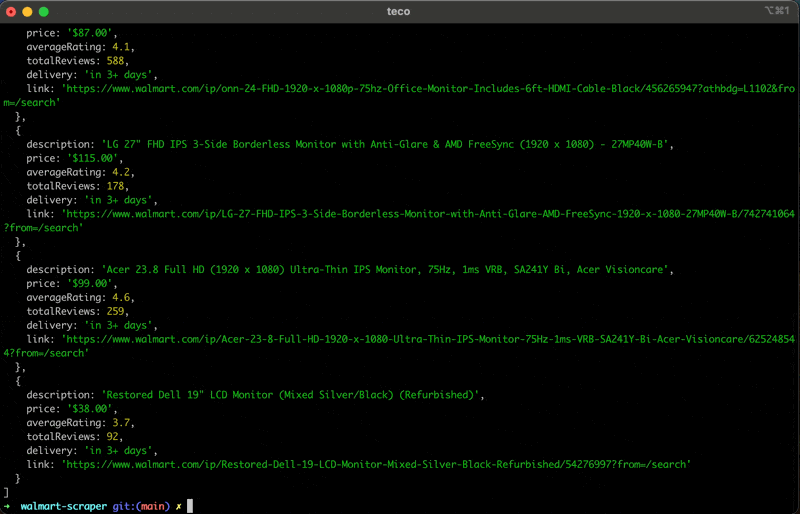
Ringkasan
Membuat web scraper untuk Walmart dapat dilakukan dengan langkah-langkah berikut:
- Gunakan Axios untuk mengirim permintaan ke ScraperAPI dengan halaman Walmart untuk mengikis dan mengunduh konten HTML yang dirender
- Parsing HTML menggunakan Cheerio untuk mengekstrak data berdasarkan pemilih DOM
- Format dan ubah data yang diambil sesuai dengan kebutuhan Anda.
Hasilnya adalah daftar informasi relevan tentang produk yang ditampilkan di situs Walmart.
Berikut adalah beberapa ide untuk membantu Anda menggunakan web scraper Walmart ini:
- Ambil data tentang suatu produk, mis. B. karakteristik teknis, ulasan, dll.
- Jadikan web scraper dinamis dengan mengizinkan masuknya istilah pencarian secara langsung
- Simpan data dalam database (RDBMS, file JSON, file CSV, dll.) untuk membuat data historis dan membuat keputusan bisnis
- Gunakan layanan Async Scraper untuk mengikis jutaan URL secara asinkron
Untuk informasi selengkapnya, lihat dokumentasi ScraperAPI untuk Node.js. Untuk akses mudah, Anda dapat menemukan repositori GitHub proyek ini di sini.
