
Siap menjelajahi kekuatan otomatisasi browser dengan Pyppeteer? Kalau begitu mari kita mulai!
TL;DR: Ikhtisar Pyppeteer
Untuk semua orang yang sedikit terlibat Pengikisan web atau mengotomatiskan tugas dengan Python, Pyppeteer adalah alat hebat untuk mengelola browser web tanpa harus melihatnya (browser tanpa kepala).
Cara memulai Pyppeteer untuk web scraping:
- Instal Pyppeteer:
- Pertama, pastikan Python dan Pip sudah terinstal. Anda dapat memeriksanya dengan menjalankan:
python --versionDanpip --version- Gunakan pip untuk menginstal Pyppeteer:
pip install pyppeteer- Siapkan pengikis Anda:
- Impor
pyppeteerdan perpustakaan lain yang diperlukan sepertiBeautifulSoup- Tulis fungsi asinkron untuk membuka browser, mengunjungi situs web, dan mengambil konten situs web
- Mengikis situs web:
- Menggunakan Pyppeteer, buka browser dan buka situs web yang ingin Anda kikis.
- Akses HTML halaman dan gunakan BeautifulSoup untuk mengambil data yang Anda perlukan, seperti judul halaman
Berikut cuplikan kode sederhana yang menggunakan Pyppeteer dan BeautifulSoup untuk mengekstrak judul halaman:
import asyncio from pyppeteer import launch from bs4 import BeautifulSoup async def main(): browser = await launch() page = await browser.newPage() await page.goto('https://books.toscrape.com/') html = await page.content() await browser.close() soup = BeautifulSoup(html, 'html.parser') title = soup.find('h1').text print('Title:', title) title = asyncio.get_event_loop().run_until_complete(main())Kode ini memulai sesi browser tanpa kepala, menavigasi ke https://books.toscrape.com/mendapatkan konten halaman dan mengekstrak judul halaman web menggunakan BeautifulSoup.
Untuk menggunakan cuplikan ini dalam proyek scraping Anda, cukup perbarui URL dan elemen yang ingin Anda ekstrak sesuai dengan kebutuhan scraping Anda.
Ingin mempelajari lebih lanjut tentang scraping dengan Pyppeteer? Lanjut membaca!
Daftar Isi
Pyppeteer: Menggunakan Pyppeteer dengan Python
Bagaimana cara menginstal Pyppeteer
Menginstal Pyppeteer adalah proses mudah yang dapat Anda selesaikan hanya dalam beberapa langkah menggunakan manajer paket Python. pip.
Ikuti petunjuk berikut untuk menjalankan Pyppeteer di komputer Anda:
-
Pastikan Python dan Pip sudah terinstal: Pyppeteer membutuhkan Python. Anda dapat memeriksa apakah Python dan Pip diinstal dengan menjalankan perintah berikut di Terminal Anda (Linux atau macOS) atau Command Prompt (Windows):
Untuk Python:
Untuk Pip:
Jika perintah ini tidak mengembalikan nomor versi, Anda perlu menginstal Python, yang dapat Anda instal di sini. Memastikan
pipdiinstal bersama dengan Python. -
Instal Pyppeteer: Jalankan perintah berikut untuk menginstal Pyppeteer:
Perintah ini mengunduh dan menginstal Pyppeteer dan semua dependensinya.
Sekarang mari kita buat skrip yang menggabungkan Pyppeteer dengan BeautifulSoup untuk membuka halaman web, mengikis konten, dan menganalisisnya.
Langkah 1: Impor perpustakaan yang diperlukan
Setelah menginstal pyppeteer, kami mengimpor beberapa perpustakaan penting ke dalam skrip kami. Kami akan menyertakan yang berikut ini: asyncio untuk menangani tugas-tugas asinkron, pyppeteer untuk kontrol browser dan BeautifulSoup dari itu bs4 Paket untuk mengurai konten HTML.
import asyncio
from pyppeteer import launch
from bs4 import BeautifulSoup
Langkah 2: Tentukan fungsi pengikisan web asinkron
Selanjutnya kita mendefinisikan fungsi asinkron yang disebut main() ini akan melakukan pengikisan kita:
async def main():
# Start the browser and open a new page
browser = await launch()
page = await browser.newPage()
await page.goto('https://books.toscrape.com/') # Enter the URL of the website you want to scrape
# Retrieve HTML and close the browser
html = await page.content()
await browser.close()
# Use BeautifulSoup to parse HTML
soup = BeautifulSoup(html, "html.parser")
title = soup.find('h1').text # Extract the text of the first
Mari kita uraikan cara kerjanya:
Langkah 3: Jalankan fungsinya dan cetak hasilnya
Untuk melihat hasil usaha scraping yang kita lakukan, kita jalankan fungsi utama dengan asyncio's Perulangan peristiwa yang menangani eksekusi fungsi asinkron:
title = asyncio.get_event_loop().run_until_complete(main())
print('Title:', title)
catatan: Jika ini pertama kalinya Anda menggunakan Pyppeteer, Anda mungkin perlu mengunduh Chromium (kira-kira 150 MB) jika belum terinstal di sistem Anda. Penyiapan awal ini dapat sedikit menunda skrip Anda.
Untuk melakukan pra-unduh Chromium secara manual dan menghindari menunggu saat pertama kali dijalankan, jalankan instruksi ini di Command Prompt atau Terminal Anda:
Perintah ini memastikan bahwa Chromium sudah siap di komputer Anda dan memudahkan menjalankan skrip Anda saat Anda ingin menjalankannya.
Anda dapat menginstalnya secara manual dari sini jika Anda menemukan kesalahan apa pun dalam unduhan Chromium Anda, langsung dengan pyppeteer.
Setelah instalasi, tambahkan path ke file Anda Chromium.exe saat Anda memulai browser sebagai berikut:
browser = await launch(executablePath='/path/to/your/chromium')
Lembar contekan Pyppeteer
Di bagian ini, kami mengeksplorasi berbagai tindakan yang dapat Anda lakukan dengan Pyppeteer, lengkap dengan cuplikan kode siap pakai untuk membantu Anda mengintegrasikan fitur-fitur ini ke dalam proyek Anda dengan lancar.
Cara menunggu halaman dimuat menggunakan Pyppeteer
Pengikisan web atau otomatisasi browser yang efektif dengan Pyppeteer mungkin memerlukan memastikan bahwa semua konten halaman telah dimuat sebelum melanjutkan. Berikut adalah beberapa metode praktis untuk mencapai hal ini:
1. Tunggu waktu tertentu
Untuk menjeda skrip Anda pada waktu tertentu, gunakan page.waitFor() Fungsi. Misalnya saja menambahkan page.waitFor(5000) membuat skrip menunggu 5 detik sebelum melanjutkan.
Bagaimana cara menggunakannya:
await page.goto('https://books.toscrape.com/')
await page.waitFor(5000) # Wait for 5000 milliseconds (5 seconds)
2. Tunggu pemilih tertentu
Metode lainnya adalah menunggu hingga elemen halaman tertentu terlihat sebelum melanjutkan.
Anda dapat melakukan ini dengan waitForSelector() Fungsi. Dalam contoh ini kita memberitahu browser untuk menunggu sampai sebuah elemen dengan .thumbnail Kelas muncul sebelum hal lain dilakukan.
Inilah cara Anda dapat menggunakannya:
await page.goto('https://books.toscrape.com/')
await page.waitForSelector('.thumbnail')
Cara mengambil tangkapan layar dengan Pyppeteer
Mengambil tangkapan layar adalah fitur canggih di Pyppeteer yang dapat digunakan untuk melakukan debug, mengarsipkan cuplikan halaman web, atau memeriksa elemen UI.
Untuk menangkap seluruh panjang sisi seperti yang ditampilkan di area pandang, gunakan screenshot() Metode.
- Pertama, navigasikan ke situs web target Anda menggunakan
goto()metode - Setelah Anda mencapai halaman tersebut, ambil tangkapan layar dengan
screenshot()Fungsi dan tentukan nama file:
await page.goto('https://books.toscrape.com/')
await page.screenshot({'path': 'example.png'})
Tangkapan layar akan disimpan ke folder proyek Anda. Ini menangkap area halaman yang terlihat sesuai dengan pengaturan default area pandang.
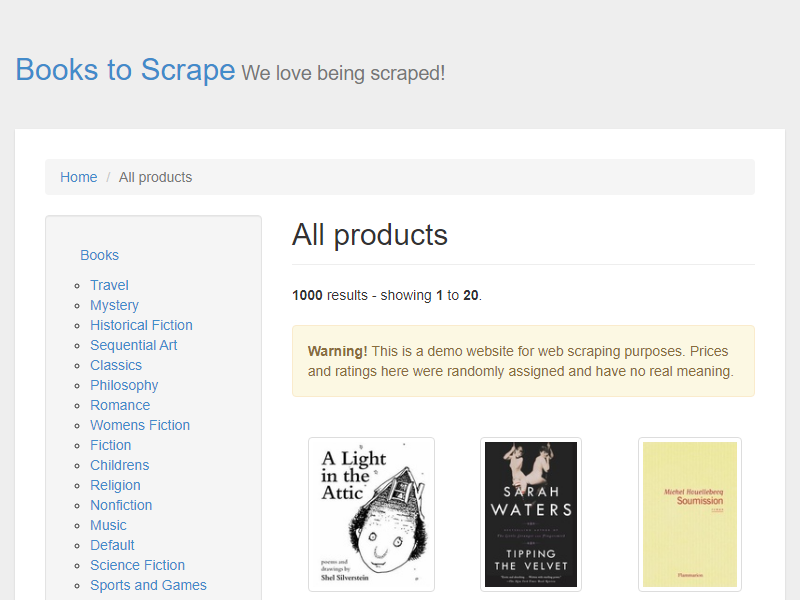
Untuk mengambil tangkapan layar dengan dimensi tertentu, Anda dapat mengatur area tampilan sebelum menavigasi ke halaman dengan menggunakan setViewport() Metode:
await page.setViewport({"width": 1400, "height": 1200})
await page.goto('https://books.toscrape.com/')
await page.screenshot({'path': 'example.png'})
Tangkapan layar akan dibuat dengan dimensi yang Anda tentukan.
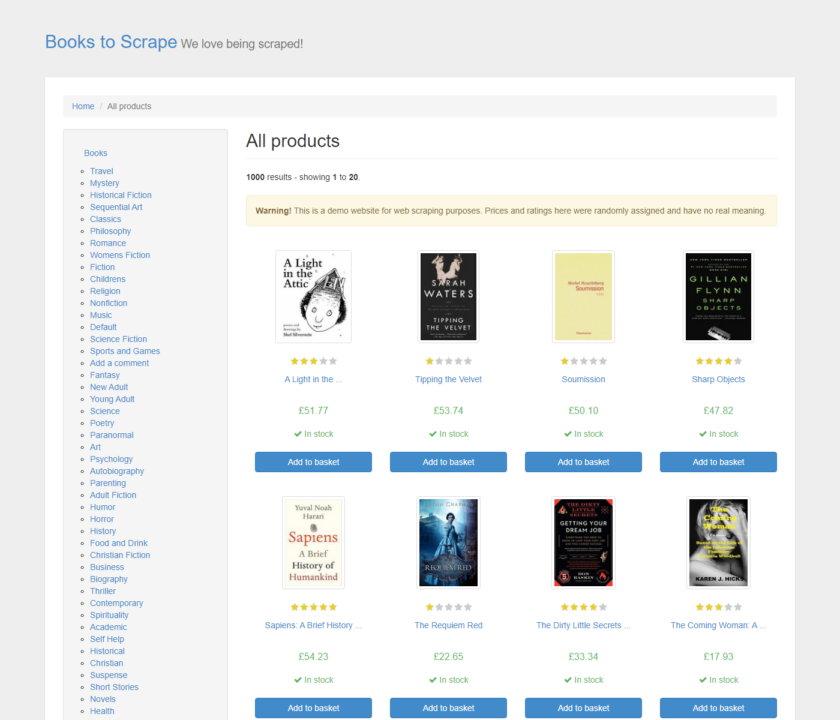
Untuk tangkapan layar seluruh halaman, menangkap dari atas ke bawah halaman terlepas dari area pandang saat ini, atur fullPage menjadi true setelah Anda memasukkan jalur gambar masuk screenshot() Metode:
await page.goto('https://books.toscrape.com/')
await page.screenshot({'path': 'example.png', 'fullPage':True})
Cara mengklik tombol dengan Pyppeteer
Pyppeteer membuat mengklik tombol atau elemen interaktif lainnya di halaman web menjadi mudah.
Pertama, Anda perlu mengidentifikasi elemen berdasarkan pemilihnya dan kemudian meminta Pyppeteer untuk mengkliknya. Dalam contoh kita, kita ingin mengklik link ke buku “A Light in the Attic” di situs Books to Scrape.
Kami dapat menemukan item yang tepat dan href Atribut yang perlu kita identifikasi menggunakan alat pengembang.
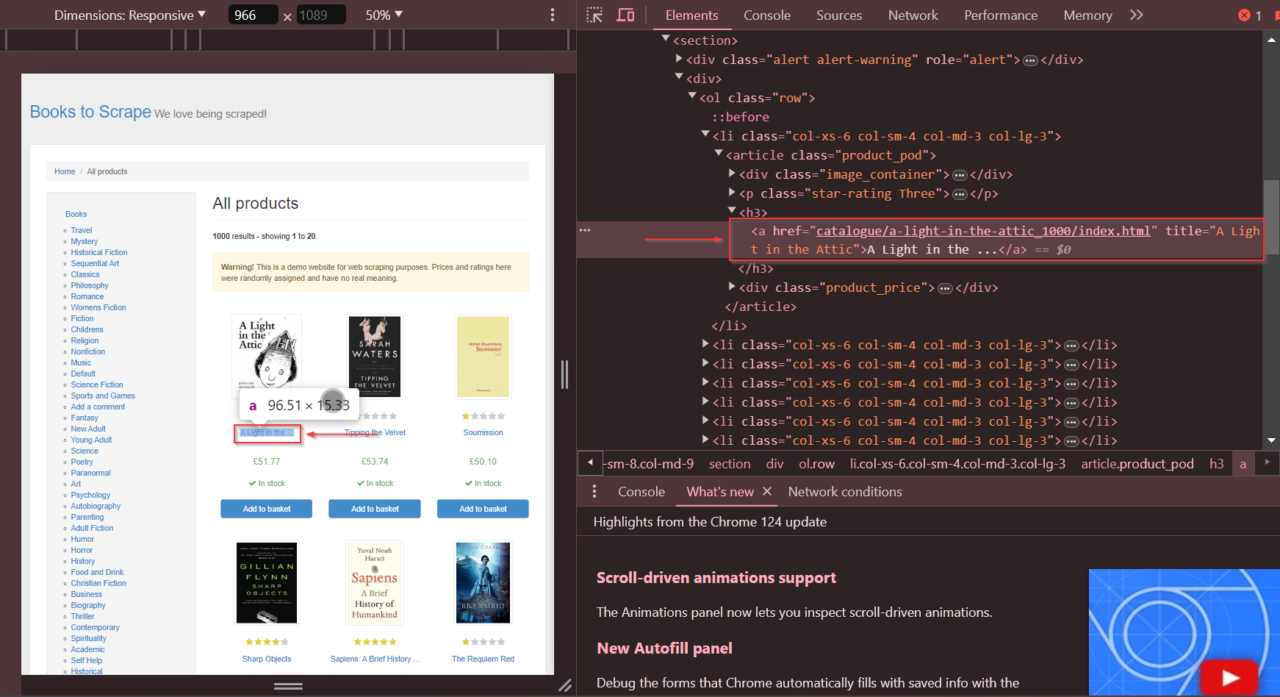
Sekarang kita sudah memiliki elemennya, mari kita gunakan click() berfungsi untuk mengkliknya dan menggunakan waitForSelector() Berfungsi untuk memberitahu browser agar menunggu elemen sebelum kita mengkliknya.
import asyncio
from pyppeteer import launch
async def click_link():
browser = await launch(headless=False) # Launches a visible browser for demonstration
page = await browser.newPage()
# Navigate to the webpage
await page.goto('https://books.toscrape.com/')
# Wait for the link to be clickable and click it
await page.waitForSelector('a(href="catalogue/a-light-in-the-attic_1000/index.html")')
await page.click('a(href="catalogue/a-light-in-the-attic_1000/index.html")')
Setelah Anda mengklik link tersebut, skrip akan menavigasi ke halaman detail buku.
Untuk mengonfirmasi bahwa navigasi berhasil dan klik mengarah ke halaman yang benar, kami mengambil tangkapan layar halaman tersebut.
# Wait for the page to load fully
await page.waitFor(10000) # Wait for 10 seconds to ensure the page has fully loaded
await page.setViewport({"width": 1400, "height": 1200}) # Set the dimensions for the screenshot
await page.screenshot({'path': 'example.png'}) # Save the screenshot
await browser.close() # Close the browser after the screenshot
asyncio.get_event_loop().run_until_complete(click_link())
Dan itu berhasil!
Di sini tangkapan layar disimpan sebagai contoh.png. Ini menunjukkan halaman detail A Light in the Attic dan mengonfirmasi bahwa skrip kami berjalan dengan sukses.
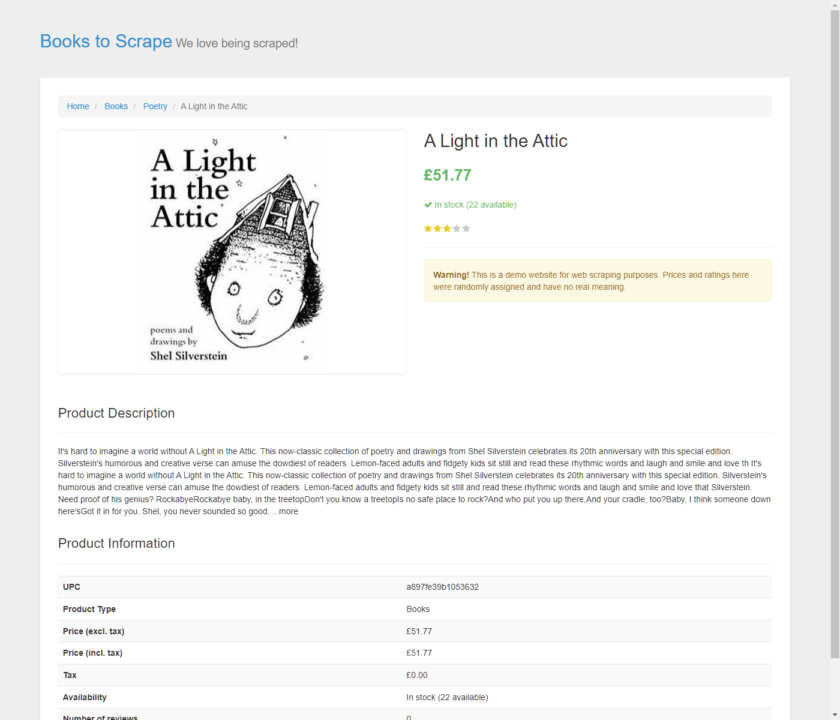
Cara menggulir halaman web menggunakan Pyppeteer
Menggulir halaman secara otomatis sangat penting saat bekerja dengan situs web yang kontennya dimuat secara dinamis saat Anda menggulir ke bawah. Pyppeteer mempermudah ini dengan menggunakannya evaluate() Berfungsi untuk mengeksekusi kode Python secara langsung dalam konteks browser. Berikut ini contoh sederhananya:
import asyncio
from pyppeteer import launch
async def simple_scroll():
browser = await launch(headless=False) # Launches a browser with a visible UI
page = await browser.newPage()
await page.setViewport({'width': 1280, 'height': 720}) # Sets the size of the viewport
await page.goto('https://books.toscrape.com') # Navigate to the website
# Scroll to the bottom of the page
await page.evaluate('window.scrollBy(0, document.body.scrollHeight);')
# Wait for additional content to load
await page.waitFor(5000)
await browser.close()
asyncio.get_event_loop().run_until_complete(simple_scroll())
Skrip Pyppeteer ini menavigasi ke halaman web dan menggulir ke bawah window.scrollBy()tunggu beberapa detik untuk memastikan semua konten dinamis telah dimuat lalu tutup browser.
Cara menggunakan proxy dengan Pyppeteer
Saat menyalin situs web, penggunaan proxy sangat penting untuk menghindari pemblokiran oleh halaman target. Jika Anda secara rutin mengirimkan permintaan dalam jumlah besar dari alamat IP yang sama, hal ini dapat mengakibatkan IP Anda diblokir.
Proksi adalah perantara antara scraper Anda dan situs web. Mereka memberikan alamat IP berbeda untuk permintaan Anda. Ini akan menutupi aktivitas pengikisan Anda sehingga tampak seolah-olah berasal dari banyak pengguna, bukan dari satu sumber.
sumber: Jika Anda ingin mempelajari lebih lanjut tentang proxy dan cara kerjanya, lihat artikel tentang penggunaan dan rotasi proxy dengan Python.
Untuk menggunakan proxy dengan Pyppeteer, Anda dapat menentukannya saat memulai browser.
Inilah cara Anda melakukannya dan melakukan autentikasi jika proxy Anda memerlukannya:
import asyncio
from pyppeteer import launch
async def use_proxy():
browser = await launch({
'args': ('--proxy-server=your_proxy_address:port')
})
page = await browser.newPage()
await page.authenticate({'username': 'your_username', 'password': 'your_password'})
await page.goto('https://books.toscrape.com')
await browser.close()
asyncio.get_event_loop().run_until_complete(use_proxy())
Jika proxy Anda dilindungi, gunakan itu authenticate() Metode untuk memberikan kredensial yang diperlukan.
Bagaimana mengintegrasikan ScraperAPI dengan Pyppeteer
Meskipun Pyppeteer mampu menangani otomatisasi browser dengan baik, Pyppeteer tidak mengelola proxy secara langsung. ScraperAPI mengisi kesenjangan ini dengan menyediakan manajemen proxy yang kuat, penting untuk melewati pemblokiran berbasis IP dan batas kecepatan oleh situs web target.
Selain itu, ScraperAPI dapat merender halaman dengan overhead JavaScript yang besar, mengurangi kompleksitas skrip Anda dan meningkatkan tingkat keberhasilan pengikisan konten dinamis.
Dengan menyerahkan manajemen proksi dan penyelesaian CAPTCHA ke ScraperAPI, skrip pengikisan Anda menjadi lebih sederhana dan lebih fokus pada logika ekstraksi data daripada melakukan tindakan anti-pengikisan.
Inilah cara Anda mengintegrasikan ScraperAPI ke dalam skrip Pyppeteer Anda:
Langkah 1: Menyiapkan browser Anda dengan ScraperAPI
Pertama kita perlu mengkonfigurasi Pyppeteer untuk menggunakan ScraperAPI sebagai proxy. Hal ini tidak hanya mengelola koneksi kami di berbagai IP yang berbeda, namun juga mengatasi potensi tindakan keamanan web yang dapat memblokir atau memperlambat proses scraping kami:
browser = await launch({
'ignoreHTTPSErrors': True,
'args': ('--proxy-server=proxy-server.scraperapi.com:8001'),
})
Penyiapan proxy ini merutekan semua lalu lintas browser melalui ScraperAPI dan memanfaatkan kemampuannya untuk melewati batasan situs dan batas kecepatan. Kami juga menginstruksikan browser untuk mengabaikan kesalahan HTTPS apa pun untuk menghindari gangguan karena masalah SSL/TLS.
Catatan: Untuk informasi lebih detail, lihat dokumentasi ScraperAPI.
Langkah 2: Otentikasi dengan ScraperAPI
Selanjutnya, autentikasi dengan ScraperAPI untuk memastikan permintaan Anda dikenali dan dikelola dengan benar:
await page.authenticate({
'username': 'scraperapi',
'password': 'YOUR_SCRAPERAPI_KEY' # Use your actual ScraperAPI key here
})
catatan: Apakah Anda memerlukan kunci API pengikis? Buat akun ScraperAPI gratis untuk menerima kunci API dan 5.000 kredit API.
Langkah 3: Navigasikan ke situs web target Anda
Sekarang mari arahkan browser kita ke situs web tempat kita ingin mengekstrak data:
await page.goto(target_url)
content = await page.content()
print(content)
Berikut kode lengkapnya:
import asyncio
from pyppeteer import launch
async def scrape_with_scraperapi():
target_url = 'https://example.com'
browser = await launch({
'ignoreHTTPSErrors': True,
'args': (
'--proxy-server=proxy-server.scraperapi.com:8001',
)
})
page = await browser.newPage()
await page.authenticate({
'username': 'scraperapi',
'password': 'YOUR_SCRAPERAPI_KEY'
})
await page.goto(target_url)
content = await page.content()
print(content)
await browser.close()
asyncio.get_event_loop().run_until_complete(scrape_with_scraperapi())
Dengan mengintegrasikan ScraperAPI ke dalam proyek pengikisan Pyppeteer, Anda dapat dengan mudah menangani tugas pengikisan yang lebih kompleks. Ini memperluas kemampuan skrip Anda dengan mengelola proksi dan menyelesaikan CAPTCHA secara otomatis, memungkinkan Anda menskalakan proyek atau menangani tugas yang lebih banyak menggunakan data.
Terus belajar
Selamat, Anda baru saja membuat scraper Pyppeteer pertama Anda!
Dengan menggunakan apa yang telah Anda pelajari hari ini dan mode proksi ScraperAPI, Anda dapat mengikis situs web dinamis dalam skala besar dan dengan tingkat keberhasilan tinggi, sehingga menciptakan aliran data yang konsisten.
Tentu saja, Anda juga dapat menggunakan fitur rendering JS ScraperAPI untuk mengurangi kompleksitas kode Anda. Ini memungkinkan Anda mengunduh halaman HTML pasca-render dan mengakses konten dinamis dengan lebih mudah.
Ingin mempelajari lebih lanjut tentang web scraping? Kunjungi blog pembelajaran berbasis proyek kami atau lihat beberapa proyek favorit kami di sini:
Sampai jumpa lagi, selamat menggores!