
Apa itu PerimeterX (sekarang Keamanan Manusia)?
PerimeterX adalah perusahaan keamanan siber yang menyediakan alat untuk melindungi aplikasi web dari serangan otomatis, aktivitas penipuan, dan Pengikisan web menyediakan. Menggunakan algoritma pembelajaran mesin canggih dan penilaian risiko, PerimeterX menganalisis sidik jari kueri dan sinyal perilaku untuk mendeteksi dan memblokir serangan bot secara real-time.
Salah satu pertahanan utamanya, HUMAN Bot Defender (sebelumnya PerimeterX Bot Defender), ditujukan langsung pada bot scraping. Itu terletak langsung di situs web dan memantau serta mengumpulkan informasi dari permintaan web yang masuk. Permintaan ini kemudian dianalisis berdasarkan aturan yang telah ditentukan dan kemudian, jika diklasifikasikan sebagai mencurigakan, tanggapan yang sesuai akan diberikan.
Meskipun PerimeterX mengizinkan masuknya beberapa bot yang sah, seperti Googlebot, PerimeterX tetap menjadi penghalang yang kuat terhadap web scraping yang tidak sah dan aktivitas otomatis lainnya.
Deteksi PerimeterX
Untuk mengidentifikasi keberadaan PerimeterX di situs web, carilah karakteristik berikut:
catatan:
Apakah Anda frustrasi karena web scraper Anda terus diblokir? ScraperAPI menanganinya untuk Anda proxy yang berputar dan browser tanpa kepala. Cobalah secara GRATIS!
Kesalahan PerimeterX yang populer
Jika PerimeterX menentukan bahwa pengunjung adalah scraper atau bot otomatis, PerimeterX akan memblokir akses dan mengeluarkan respons 403 Terlarang bersama dengan halaman pemblokiran bermerek. Respons ini berasal dari sensor PerimeterX, yang terintegrasi ke dalam infrastruktur situs.
Berikut adalah beberapa pesan kesalahan PerimeterX umum yang mungkin Anda temui:
| Pesan atau kode | Arti |
| 403 Dilarang | PerimeterX telah menandai permintaan Anda sebagai kemungkinan otomatis. |
| “Tolong buktikan bahwa kamu adalah manusia.” |
Pesan ini muncul ketika pengujian browser JavaScript gagal dan meminta pengguna untuk mengonfirmasi bahwa mereka adalah manusia. |
| “Aktifkan cookie” | Header cookie tidak beraturan atau hilang |
| “Coba lagi nanti” | Penghentian sementara karena pola aktivitas mencurigakan |
| Tantangan APTCHA |
Dipicu oleh kegagalan pemeriksaan sidik jari dan perilaku yang memerlukan verifikasi tambahan untuk melanjutkan. |
Ingatlah bahwa perilaku pemblokiran PerimeterX bersifat dinamis dan dapat berubah seiring waktu. Selalu bersiaplah untuk menyesuaikan teknik pengikisan saat Anda menghadapi hambatan atau tantangan jenis baru.
Bagaimana PerimeterX mendeteksi bot?
Anda dapat mengidentifikasi PerimeterX dengan pesan “Tahan” dan “Harap konfirmasi bahwa Anda adalah manusia” seperti gambar di bawah ini:
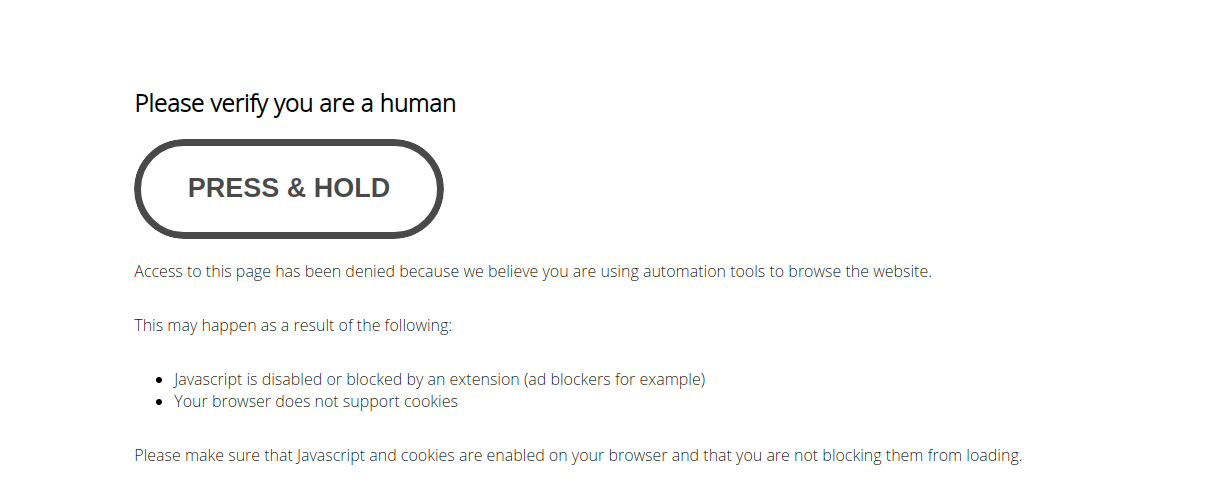
Untuk menghindari layanan anti-web scraping seperti PerimeterX, pertama-tama kita harus memahami cara kerjanya. Pada dasarnya ini terbagi menjadi tiga kategori deteksi:
- alamat IP
- Sidik jari Javascript
- Detail pertanyaan
Layanan seperti PerimeterX menggunakan alat ini untuk menghitung skor kepercayaan untuk setiap pengunjung. Nilai yang rendah berarti kemungkinan besar Anda adalah bot. Jadi, Anda harus menyelesaikan tugas CAPTCHA atau akses Anda akan ditolak sepenuhnya. Jadi bagaimana kita mencapai nilai tinggi?
Alamat IP/proxy
PerimeterX menganalisis alamat IP untuk mengidentifikasi aktivitas mencurigakan. Idealnya kami ingin mendistribusikan beban kami ke seluruh proxy. Proxy ini dapat berupa proxy pusat data, perumahan, atau seluler.
Untuk mempertahankan skor kepercayaan yang tinggi, scraper Anda harus melalui kumpulan proxy perumahan atau seluler. Untuk informasi lebih lanjut, lihat postingan blog kami tentang apa itu proxy perumahan dan mengapa proxy tersebut harus digunakan untuk scraping.
Sidik jari Javascript
Topik ini cukup luas, terutama untuk pengembang junior, namun berikut ringkasan singkatnya.
Situs web dapat menggunakan Javascript untuk sidik jari klien koneksi (scraper) karena Javascript mengungkapkan data tentang klien, termasuk sistem operasi, font yang didukung, kemampuan rendering visual, dll.
Misalnya, jika PerimeterX mendeteksi sejumlah besar klien Linux yang terhubung melalui jendela resolusi 1280x720, PerimeterX dapat dengan mudah menyimpulkan bahwa jenis pengaturan ini kemungkinan adalah bot dan mengumumkan kepada semua pengguna Detail sidik jari ini memiliki tingkat kepercayaan yang rendah.
Jika Anda menggunakan Selenium untuk melewati PerimeterX, Anda perlu menambal banyak kebocoran ini untuk keluar dari Low Trust Zone. Anda dapat melakukan ini dengan memodifikasi browser untuk memasukkan detail sidik jari yang salah atau dengan menggunakan versi browser tanpa kepala yang ditambal seperti “Kawat selenium.”
Untuk informasi lebih lanjut, lihat blog kami: 10 Tips Mengikis Web Tanpa Diblokir.
Detail pertanyaan
Untuk pola koneksi yang tidak biasa, PerimeterX masih dapat memberi kami skor kepercayaan yang rendah meskipun kami memiliki kumpulan alamat IP yang besar dan telah menambal browser tanpa kepala kami untuk mencegah bocornya detail sidik jari yang penting.
Ia mengamati berbagai peristiwa tetap, yang menunjukkan bahwa ia menggunakan analisis perilaku. Oleh karena itu, penting untuk berhati-hati saat menggores situs web ini. Untuk menghindari hal ini,
Pengikis Anda harus mengikis dengan pola yang tidak terlihat jelas. Itu juga harus sesekali terhubung ke halaman non-landing seperti beranda situs web agar terlihat lebih manusiawi.
Sekarang setelah kami mengetahui cara scraper kami terdeteksi, kami dapat mencari cara untuk mengabaikan tindakan ini. Selenium, Penulis Drama, dan Dalang memiliki komunitas yang besar, dan kata kunci yang dicari di sini adalah “Diam-diam.”
Sayangnya, hal ini tidak mudah dilakukan, karena PerimeterX hanya dapat mengumpulkan patch yang diketahui publik dan menyesuaikan layanannya. Anda mungkin pernah mengalami hal ini beberapa kali jika Anda mencoba metode ini secara manual, yang berarti Anda harus memikirkan banyak hal sendiri.
Alternatif yang lebih baik adalah dengan menggunakannya API pengikisan web untuk dengan mudah mengikis situs web yang dilindungi.
Melewati PerimeterX dengan ScraperAPI
ScraperAPI membantu Anda menghindari pemblokiran alamat IP dengan merotasi alamat IP, memproses CAPTCHA, dan mengelola batas permintaan. Ini menyederhanakan seluruh proses pengikisan dengan menyediakan akses yang andal ke halaman web dan memastikan bahwa Anda dapat fokus pada penggalian dan analisis data alih-alih mengambil tindakan anti-pengikisan.
Menggunakan Python dan ScraperAPI mempermudah pengambilan data dalam jumlah besar dari situs web yang dilindungi PerimeterX.
Dalam panduan ini, kami akan menunjukkan cara mendapatkan informasi produk dari Neiman Marcus, department store terkenal dengan situs web e-commerce yang dilindungi PerimeterX.
persyaratan
Untuk mengikuti panduan ini, pastikan Anda telah memenuhi persyaratan berikut:
Langkah 1: Siapkan lingkungan Anda
Pertama, mari siapkan lingkungan virtual untuk menghindari konflik dengan modul atau pustaka Python yang ada.
Untuk pengguna macOS:
pip install virtualenv
python3 -m virtualenv venv
source venv/bin/activate
Untuk pengguna Windows:
pip install virtualenv
virtualenv venv
srouce venv\Scripts\activate
Setelah lingkungan virtual Anda diaktifkan, instal perpustakaan yang diperlukan:
pip install requests beautifulsoup4 lxml
Langkah 2: Analisis situs web target
Website target kami adalah Neiman Marcus, department store ternama yang memiliki website e-commerce dimana kami akan mencoba mengikis harga produk.
Dengan menggunakan alat seperti Wappalyzer, kami dapat memastikan bahwa PerimeterX melindungi Neiman Marcus. Namun, untuk melewati perlindungan tersebut kita perlu menggunakan ScraperAPI.
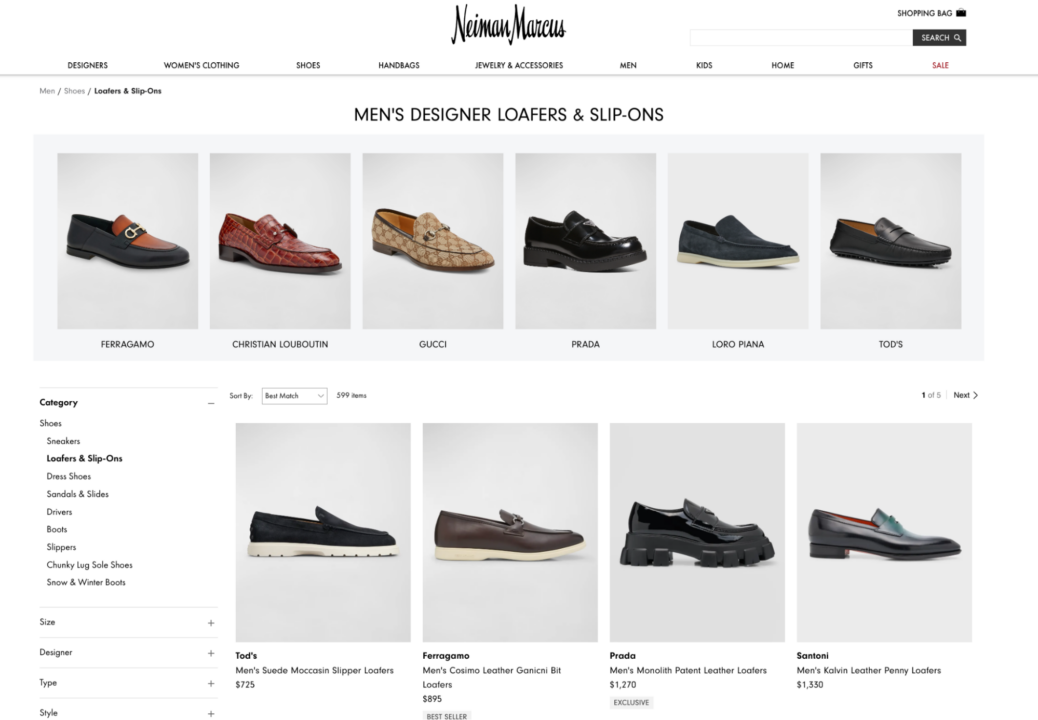
Kami fokus mengumpulkan informasi produk dari halaman kategori sepatu pria.
Langkah 3: Siapkan ScraperAPI
Pertama, buat akun ScraperAPI gratis dan salin kunci API Anda dari dasbor Anda.
Langkah 4: Tulis skrip pengikisan
Sekarang mari kita buat skrip Python yang menggunakan ScraperAPI untuk melewati PerimeterX dan mengambil informasi produk:
import requests
from bs4 import BeautifulSoup
import json
API_KEY = "YOUR_API_KEY"
url = "https://www.neimanmarcus.com/en-ng/c/shoes-shoes-loafers-slip-ons-cat10580739?navpath=cat000000_cat000470_cat000550_cat10580739"
payload = {"api_key": API_KEY, "url": url, "render": "true"}
def scrape_product_info():
response = requests.get("http://api.scraperapi.com", params=payload)
if response.status_code != 200:
print(f"Failed to retrieve the page. Status code: {response.status_code}")
return ()
soup = BeautifulSoup(response.text, 'lxml')
products = soup.find_all('div', class_='product-thumbnail__details')
product_info = ()
for product in products:
designer = product.find('span', class_='designer')
name = product.find('span', class_='name')
price = product.find('span', class_='price-no-promo')
badge = product.find('div', class_='gift-badge')
info = {
'designer': designer.text.strip() if designer else 'N/A',
'name': name.text.strip() if name else 'N/A',
'price': price.text.strip() if price else 'N/A',
'batch_details': badge.text.strip() if badge else 'N/A'
}
product_info.append(info)
return product_info
def save_to_json(product_info, filename='neiman_marcus_loafers.json'):
with open(filename, 'w', encoding='utf-8') as jsonfile:
json.dump(product_info, jsonfile, ensure_ascii=False, indent=4)
if __name__ == "__main__":
print("Scraping product information...")
product_info = scrape_product_info()
if product_info:
print(f"Found {len(product_info)} products.")
save_to_json(product_info)
print("Product information saved to neiman_marcus_loafers.json")
else:
print("No products found or there was an error scraping the website.")
catatan: Untuk menjalankan contoh ini, ganti
YOUR_API_KEY dengan kunci API Anda saat ini dari dasbor Anda.
Di sini kami membuat permintaan ke ScraperAPI dan meneruskan kunci API dan URL tujuan kami. ScraperAPI menangani kerumitan perputaran alamat IP, menyelesaikan CAPTCHA, dan mengelola tindakan anti-scraping PerimeterX lainnya. Itu
render=true Parameter dalam payload menginstruksikan ScraperAPI untuk sepenuhnya merender halaman web target di browser tanpa kepala, memastikan bahwa semua konten dinamis yang dilindungi oleh PerimeterX dimuat sepenuhnya dan tersedia untuk scraping.
Setelah ScraperAPI mengembalikan konten HTML yang dirender, kami menggunakan
BeautifulSoup untuk menganalisisnya. Kami menargetkan elemen HTML tertentu berdasarkan nama kelasnya (product-thumbnail__details,
designer, name, price-no-promo,
gift-badge) untuk mengekstrak informasi produk yang diinginkan.
Langkah 5: Jalankan skrip
Simpan skrip sebagai neiman_marcus_scraper.py dan jalankan:
python neiman_marcus_scraper.py
Skrip ini kemudian mengambil informasi produk dari halaman Loafers Pria Neiman Marcus, melewati perlindungan PerimeterX menggunakan ScraperAPI. Data yang diambil disimpan dalam file JSON bernama.
neiman_marcus_loafers.json.
(
{
"designer": "Tod's",
"name": "Men's Suede Moccasin Slipper Loafers",
"price": "$725",
"batch_details": "N/A"
},
{
"designer": "Ferragamo",
"name": "Men's Cosimo Leather Ganicni Bit Loafers",
"price": "$895",
"batch_details": "Best Seller"
},
{
"designer": "Prada",
"name": "Men's Monolith Patent Leather Loafers",
"price": "$1,270",
"batch_details": "Exclusive"
},
{
"designer": "Santoni",
"name": "Men's Kalvin Leather Penny Loafers",
"price": "$1,330",
"batch_details": "N/A"
},
Truncated data,
}
Selamat, jika Anda sudah membuat kode sejauh ini, Anda telah berhasil melewati situs web yang dilindungi Keamanan Manusia! Pendekatan ini juga dapat diadaptasi untuk menjelajahi situs web lain yang dilindungi PerimeterX.
Pikiran terakhir
Tidak dapat disangkal bahwa PerimeterX (sekarang HUMAN Security) adalah sistem anti-bot canggih yang menggunakan serangkaian teknik untuk melindungi situs web dari pengikisan yang tidak diinginkan. Dari memantau alamat IP dan menganalisis header permintaan hingga menggunakan berbagai metode sidik jari, PerimeterX menghadirkan tantangan berat bagi web scraper.
Tim ScraperAPI terus memperbarui metode bypass API agar scraper Anda tetap berjalan. Ini menjadikan ini cara terbaik untuk mengikis data dari situs yang dilindungi PerimeterX tanpa diblokir.
Jika Anda ingin mempelajari cara mengikis situs web populer lainnya, lihat panduan pengikisan kami yang lain:
