
Python adalah salah satu bahasa pemrograman terbaik untuk web scraping. Saat Anda mulai membuat dan membuat skrip, pilihan perpustakaan sering kali bergantung pada preferensi dan keterampilan pribadi Anda. Namun, penting untuk mempertimbangkan apakah perpustakaan yang Anda pilih cocok untuk tugas yang ada.
Artikel ini membahas area konten dinamis, membedakannya dari konten statis, dan menunjukkan mengapa tidak semua perpustakaan di gudang Anda cocok untuk menggores situs web dinamis. Selain itu, kami akan menjelajahi contoh kode yang dapat Anda gunakan untuk mengumpulkan data dari situs web mana pun, serta berbagai teknik dan konsep lanjutan untuk menyempurnakan scraper Anda.
Daftar Isi
Memahami konten dinamis
Sebelum kita mendalami contoh web scraping dinamis, mari kita jelaskan terlebih dahulu apa itu web scraping dinamis dan perbedaannya dengan konten statis. Dengan memahami perbedaan ini, kita dapat membuat keputusan yang lebih tepat ketika memilih alat pengikis yang tepat dan mengoptimalkan proses pengembangan.
Konten statis vs. dinamis
Situs web statis memiliki konten yang tetap sama untuk semua pengguna, terlepas dari tindakan atau waktu mereka. Mereka biasanya ditulis dalam HTML, CSS dan JavaScript dan disimpan sebagai file yang dibuat sebelumnya di server web. Hal ini membuatnya mudah untuk dibuat dan dikelola dan biasanya dimuat dengan cepat. Namun, situs web statis tidak dapat menampilkan konten yang dipersonalisasi atau informasi real-time.
Situs web dinamis, di sisi lain, menghasilkan konten secara spontan berdasarkan masukan pengguna atau faktor lainnya. Mereka biasanya ditulis dalam bahasa pemrograman sisi server seperti PHP, Python atau Node.js dan menggunakan database untuk menyimpan data. Hal ini membuat pengembangan dan pemeliharaannya menjadi lebih kompleks, namun menawarkan kemungkinan yang lebih luas, seperti konten yang dipersonalisasi, pembaruan waktu nyata, dan elemen interaktif.
Teknologi umum
Seperti disebutkan sebelumnya, konten statis pada suatu halaman adalah teks tetap, gambar, dan elemen lain yang telah ditentukan sebelumnya dan tidak berubah setelah halaman dimuat. Biasanya ditampilkan menggunakan HTML sederhana, CSS dan JavaScript.
Konten dinamis, di sisi lain, dibuat atau diubah berdasarkan berbagai faktor seperti tindakan pengguna, waktu, atau data eksternal. Mari kita lihat beberapa cara umum untuk menerapkan konten dinamis:
- PHP. Bahasa skrip sisi server yang menghasilkan kode HTML dengan cepat sebagai respons terhadap permintaan pengguna.
- AJAX. Sebuah teknik untuk memuat sebagian halaman tanpa memuat ulang seluruh halaman.
- JavaScript. Bahasa skrip sisi klien yang memungkinkan Anda mengubah konten halaman di browser pengguna.
Meskipun ada perbedaan dalam teknologi yang digunakan untuk konten dinamis, prinsip umum di balik pengambilan dan tampilannya tetap sama: mengubah dan memperbarui data secara real-time. Pada bagian berikut, kita akan mempelajari lebih dalam prinsip-prinsip ini dan metode penerapannya.
Alat dan pustaka untuk menggores halaman dinamis dengan Python
Biasanya, konten halaman web dinamis tidak dapat diakses sampai konten tersebut dimuat sepenuhnya. Oleh karena itu, metode pengambilannya terbatas pada metode yang memungkinkan halaman web dimuat sepenuhnya sebelum mengambil kontennya.
Mari kita pertimbangkan pustaka Python paling populer untuk menggores dan mengurai data dan memeriksa apakah mereka mengizinkan pengikisan situs web dinamis. Jika iya, kami berikan contoh penggunaannya.
Sup enak dan konten dinamis
Perpustakaan pertama yang terlintas dalam pikiran saat melakukan scraping adalah BeautifulSoup. Namun, seperti yang telah kami sebutkan di artikel lain, BS4 hanya memungkinkan Anda mengurai HTML suatu halaman dan tidak memungkinkan Anda mengambilnya sendiri.
Dalam hal ini, pustaka permintaan sederhana seperti request atau urllib biasanya digunakan untuk mengambil HTML awal dari halaman web. Sayangnya, pendekatan tradisional ini gagal dalam hal konten dinamis yang terus dimuat dan diperbarui melalui permintaan JavaScript atau AJAX.
Untuk menyalin situs web dinamis di mana interaksi dan pembaruan terjadi setelah pemuatan halaman awal, alat seperti Selenium, Pyppeteer, atau Playwright sangat penting. Pustaka ini memungkinkan penjelajahan dan interaksi otomatis dengan halaman web dan memungkinkan pengambilan konten yang hanya ditampilkan setelah tindakan pengguna atau pembaruan waktu nyata.
Meskipun BeautifulSoup tetap sangat berharga untuk analisis HTML statis, menghapus aplikasi web modern yang sangat bergantung pada konten dinamis memerlukan penggunaan Selenium atau alat serupa.
Selenium, Pyppeteer atau Penulis Drama
Seperti disebutkan sebelumnya, solusi untuk masalah ini terletak pada penggunaan pustaka browser tanpa kepala seperti Selenium, Puppeteer (pembungkus untuk Puppeteer), atau Playwright. Kami telah membandingkan pustaka Python untuk browser tanpa kepala dan mendiskusikan cara menginstalnya, jadi kami tidak akan membahasnya secara detail di sini.
Proses umum untuk menyalin konten dinamis menggunakan browser tanpa kepala adalah sebagai berikut:
- Konfigurasikan browser tanpa kepala. Siapkan parameter browser tanpa kepala, seperti ukuran jendela dan agen pengguna.
- Arahkan ke halaman arahan. Muat situs web yang ingin Anda kikis.
- Tunggu hingga halaman dimuat. Tunggu hingga seluruh halaman web dimuat sepenuhnya, termasuk konten dinamis apa pun yang dihasilkan oleh JavaScript.
- Kikis datanya. Ekstrak data yang diinginkan dari halaman web yang dirender.
- Tutup peramban. Tutup contoh browser tanpa kepala.
Setelah halaman web dimuat sepenuhnya, semua data yang diperlukan dimuat dan dibuat, sehingga mudah untuk diambil. Selain itu, perpustakaan ini memungkinkan Anda untuk sepenuhnya meniru tindakan pengguna sebenarnya di halaman tersebut. Ini memberi Anda kesempatan untuk mengatur parameter yang diperlukan dan mendapatkan data yang Anda butuhkan.
Sekarang mari kita lihat contoh dan terapkan algoritma yang telah dibahas sebelumnya untuk tiga perpustakaan paling populer yang mendukung browser tanpa kepala. Mari kita mulai dengan Selenium dan membuat skrip baru untuk ini, mengimpor semua modul yang diperlukan dan menyiapkan browser tanpa kepala:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
url = "https://example.com"
chrome_options = Options()
driver = webdriver.Chrome(options=chrome_options)Navigasikan ke halaman web yang diinginkan menggunakan metode driver.get():
driver.get(url)Saat menyalin halaman web dinamis, penting untuk menunggu elemen target dimuat sebelum mencoba berinteraksi dengannya atau mengekstrak data darinya. Selenium menawarkan beberapa metode untuk menerapkan waktu tunggu, masing-masing dengan kelebihannya. Cara termudah untuk menambahkan waktu tunggu adalah dengan menyetel time.sleep():
time.sleep(5)Atau Anda dapat menggunakan Selenium untuk mencapai hal yang sama:
wait = WebDriverWait(driver, 10)Opsi terakhir adalah menunggu elemen tertentu dimuat. Metode ini sangat berguna ketika Anda mengetahui elemen mana yang dihasilkan secara dinamis. Anda cukup menunggu hingga muncul lalu melanjutkan pengikisan data. Berikut ini contoh cara kerjanya dengan Selenium:
paragraphs = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, 'p')))Selanjutnya, kita perlu mengekstrak data yang kita perlukan dari halaman dan memprosesnya, menyimpannya, atau menampilkannya di layar:
paragraph = driver.find_elements(By.CSS_SELECTOR, 'p').text
print(paragraph)Dan terakhir, pastikan untuk menutup browser web:
driver.quit()Ini memungkinkan Anda untuk mendapatkan data apa pun dari halaman menggunakan algoritme ini, meskipun konten ini dibuat secara dinamis.
Mari ulangi proses yang sama untuk dua perpustakaan lainnya. Sekarang kami akan menunjukkan cara menggunakan Pyppeteer untuk mengumpulkan konten dinamis dari halaman web. Pyppeteer adalah perpustakaan asynchronous, jadi kita memerlukan perpustakaan Asyncio untuk memfasilitasi pengoperasian. Kami merangkum seluruh proses pengumpulan data dalam fungsi asinkron:
import asyncio
from pyppeteer import launch
url = "https://example.com"
async def main():
# Here will be code
asyncio.get_event_loop().run_until_complete(main())Mari sempurnakan fungsi main() dan atur driver web:
async def main():
browser = await launch()
page = await browser.newPage()Selanjutnya, buka halaman tersebut dan tunggu hingga dimuat sepenuhnya:
await page.goto(url)
await page.waitForSelector('p')Mengambil dan memproses data:
paragraphs = await page.querySelectorAll('p')
paragraph_texts = ()
for paragraph in paragraphs:
text = await page.evaluate('(element) => element.textContent', paragraph)
paragraph_texts.append(text.strip())Terakhir, tutup driver web:
await browser.close()Perpustakaan terakhir adalah Penulis Drama. Ini tidak sepopuler Selenium atau Puppeteer, yang bersaing satu sama lain karena pendekatan yang berbeda, tetapi juga digunakan secara luas.
Dari segi cara kerjanya sangat mirip dengan Selenium, meskipun fungsionalitasnya lebih sedikit. Untuk memulai, kami mengimpor modul yang diperlukan dan mengatur tautan:
from playwright.sync_api import sync_playwright
url = "https://example.com"Impor perpustakaan yang diperlukan dan buat instance driver web. Kemudian gunakan metode goto() driver web untuk mengakses halaman web yang ditentukan:
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto(url)Menggunakan wait_for_selector_all() Tunggu hingga elemen yang diinginkan terlihat di halaman. Hal ini memastikan bahwa elemen terisi penuh dan siap untuk berinteraksi:
paragraphs = page.wait_for_selector_all('p')Proses data yang diekstraksi:
paragraph_texts = (paragraph.text_content() for paragraph in paragraphs)
print(paragraph_texts)Setelah semua tugas ekstraksi data selesai, panggil metode quit() driver web untuk menutup jendela browser dengan benar dan melepaskan sumber dayanya:
browser.close()Meskipun Playwright memiliki fitur yang lebih sedikit dibandingkan Selenium, ia juga memiliki pengikut dan cukup berhasil mengumpulkan data dari situs web dinamis. Oleh karena itu, pilihan perpustakaan tidak terlalu bergantung pada mana yang lebih baik, tetapi mana yang lebih nyaman bagi Anda.
bantalan pelana
Scrapy, tidak seperti opsi yang dibahas sebelumnya, bukan hanya perpustakaan, tetapi kerangka kerja lengkap untuk web scraping. Kami sudah menjelaskan cara menggunakan Scrapy dengan Python, tapi sekarang mari selami lebih dalam aplikasi scraping situs web dinamis.
Pertama, penting untuk dicatat bahwa Scrapy tidak menyertakan browser tanpa kepala, artinya ia tidak dapat memuat halaman web sebelum memprosesnya. Namun, lihat dokumentasi resmi Scrapy menunjukkan bagian khusus untuk menggores halaman web dinamis.
Ini mungkin tampak aneh sampai kita memeriksa metode yang disarankan dalam dokumentasi. Pada kenyataannya, seperti yang sudah Anda duga, Scrapy tidak mendukung pengikisan halaman web dinamis karena ia melakukan permintaan sederhana dan tidak meniru perilaku browser.
Oleh karena itu, situs web resmi Scrapy merekomendasikan penggunaan perpustakaan tambahan yang menyediakan fungsi ini. Dalam contoh khusus ini, perpustakaan Penulis Drama yang telah dibahas sebelumnya direkomendasikan sebagai alternatif.
Sayangnya, hal ini membawa kita pada kesimpulan bahwa kerangka Scrapy tidak memfasilitasi pengikisan halaman dinamis, tidak seperti perpustakaan BeautifulSoup.
API Pengikisan Web HasData
Metode terakhir dan termudah adalah dengan menggunakan web scraping API, yang mengumpulkan konten dinamis untuk Anda dan menyediakan kumpulan data yang sudah dibuat sebelumnya atau HTML dari halaman web yang dimuat sepenuhnya. Sebagai contoh, kita akan menggunakan Web Scraping API HasData.
Untuk menggunakannya, daftar di situs web kami dan masuk ke akun Anda. Di tab Dasbor Anda akan menemukan kunci API pribadi Anda, yang nantinya Anda perlukan.
Kita dapat mengambil data menggunakan Web Scraping API melalui API Playground atau membuat skrip Python kita sendiri menggunakan dokumentasi. Mari kita mulai dengan opsi yang lebih sederhana dan pergi ke API Playground:
Anda kemudian dapat memilih API untuk situs web tertentu atau API web scraping umum yang memungkinkan Anda mengumpulkan data dari sumber daya apa pun. Sebagai contoh, pertimbangkan opsi yang paling serbaguna.
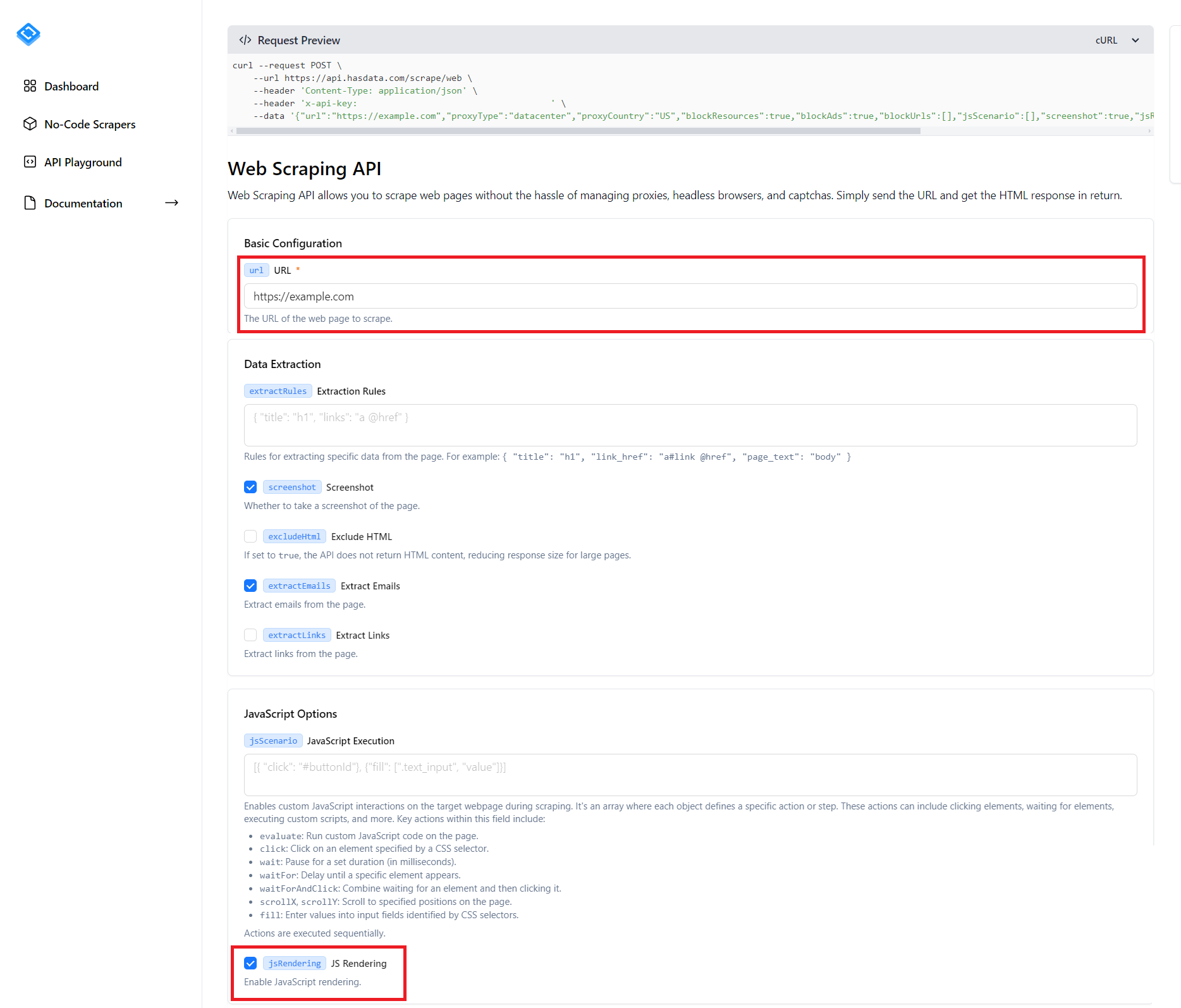
Seperti yang Anda lihat, ada banyak parameter berbeda di halaman yang dapat Anda konfigurasikan dan akan memakan waktu lama untuk mempelajari masing-masing parameter tersebut. Selain itu, tangkapan layar tidak menunjukkan semua parameter yang mungkin, tetapi hanya setengahnya. Namun, hal terpenting yang Anda perlukan untuk mengikis situs web dinamis adalah menentukan URL situs web tempat Anda ingin mengumpulkan data dan mencentang kotak di sebelah item “JS Rendering”.
Anda dapat mengatur parameter untuk opsi lainnya, mis. Seperti lokasi, proxy, aturan ekstraksi, ekstraksi email dan masih banyak lagi, atau Anda bisa membiarkannya apa adanya. Anda kemudian dapat menjalankan skrip dengan mengklik tombol Jalankan Permintaan, menyalin kode dalam salah satu bahasa pemrograman, atau menjalankan permintaan cURL di bagian atas layar.
Kami akan menulis skrip yang mengumpulkan data dari situs web dinamis menggunakan Python. Pertama, buat file *.py baru dan impor pustaka persyaratan ke proyek Anda:
import requestsSelanjutnya, berikan URL titik akhir API web scraping:
url = "https://api.hasdata.com/scrape/web"Tentukan parameter yang ingin Anda teruskan ke API. Misalnya, tentukan URL situs web, aktifkan rendering JS, ambil tangkapan layar, dan sertakan potongan email dari halaman:
payload = json.dumps({
"url": "https://example.com",
"proxyType": "datacenter",
"proxyCountry": "US",
"blockAds": True,
"screenshot": True,
"jsRendering": True,
"extractEmails": True
})Kemudian atur header permintaan dan tempelkan kunci API pribadi yang Anda peroleh sebelumnya:
headers = {
'Content-Type': 'application/json',
'x-api-key': 'YOUR-API-KEY'
}Sekarang buat permintaan API untuk mendapatkan parameter yang diinginkan:
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)Anda dapat memproses hasilnya sesuka Anda. Namun, ingatlah bahwa API mengembalikan data dalam format JSON, dengan salah satu atribut berisi seluruh kode sumber halaman.
Teknik tingkat lanjut
Karena Selenium tetap menjadi perpustakaan paling populer untuk menggores situs web dinamis, kami akan menggunakannya untuk semua contoh di bagian ini. Namun, dua perpustakaan lainnya mendukung fungsi serupa, sehingga Anda dapat mengadaptasi contoh yang dibahas ke proyek Anda jika perlu.
Kami membangun dan memodifikasi skrip yang ditulis sebelumnya:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
url = "https://example.com"
chrome_options = Options()
driver = webdriver.Chrome(options=chrome_options)
driver.get(url)
paragraph = driver.find_elements(By.CSS_SELECTOR, 'p').text
print(paragraph)
driver.quit()Kami membahas berbagai fitur dan teknik tambahan yang dapat berguna saat mengumpulkan konten dinamis dari halaman.
Menggunakan Mode Tanpa Kepala di Selenium
Untuk meningkatkan kinerja skrip pengikisan web Anda, pertimbangkan untuk menggunakan mode tanpa kepala, yang menjalankan browser web Anda di latar belakang tanpa merender antarmuka pengguna grafis. Selain itu, nonaktifkan penggunaan GPU untuk lebih mengoptimalkan kinerja dalam mode headless.
Untuk mencapai hal ini, cukup tentukan opsi tambahan saat mengkonfigurasi driver web:
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
driver = webdriver.Chrome(options=chrome_options)Selain penyesuaian ini, skrip tetap tidak berubah, namun perubahan ini secara signifikan meningkatkan kecepatan dan efisiensi scraper situs web dinamis Anda.
Menangani pengguliran tanpa batas
Pengguliran tanpa batas adalah teknik populer yang memuat konten secara bertahap saat pengguna menggulir halaman ke bawah. Ini menghilangkan kebutuhan akan penomoran halaman. Pendekatan ini meningkatkan pengalaman pengguna dengan memungkinkan interaksi yang lancar dan dinamis.
Hal ini sangat berguna untuk menampilkan data dalam jumlah besar, seperti feed media sosial atau hasil pencarian, dan untuk menampilkan data dalam jumlah besar tanpa memerlukan penomoran halaman atau memuat ulang halaman. Ini meningkatkan pengalaman pengguna dengan memberikan pengalaman penelusuran yang mulus dan lancar.
Untuk menerapkan pengguliran tak terbatas kita perlu mengikuti langkah-langkah berikut:
- Identifikasi bagian bawah halaman. Saat halaman dimuat, tentukan posisi bagian bawah halaman.
- Gulir ke bagian bawah halaman. Pindahkan kanvas ke akhir konten halaman.
- Periksa apakah posisi saat ini ada di bagian bawah halaman. Tentukan apakah posisi viewport saat ini sudah mencapai akhir halaman. Jika tidak, identifikasikan akhir halaman yang baru.
- Ulangi langkah 2-3. Gulir terus ke bagian bawah halaman dan periksa posisi saat ini hingga area pandang mencapai akhir halaman sebenarnya.
Mari kita perluas skrip asli kita dengan menambahkan kode Python berikut untuk melakukan pengguliran setelah halaman dimuat tetapi sebelum mengumpulkan data dari halaman:
driver.get(url)
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
paragraph = driver.find_elements(By.CSS_SELECTOR, 'p').textSkrip tingkat lanjut ini secara efektif mengimplementasikan algoritme pengguliran tak terbatas dan oleh karena itu dapat diterapkan ke berbagai situs web dengan persyaratan serupa.
Evaluasi JavaScript
Dalam skenario web scraping, sering kali kode JavaScript perlu dieksekusi langsung di halaman web sebelum mengekstraksi data. Hal ini sangat berguna untuk menangani pemuatan halaman web secara dinamis, mengaktifkan elemen UI, atau melakukan tugas prapemrosesan data. Selain itu, JavaScript dapat digunakan untuk mengotomatiskan tugas-tugas kompleks seperti menyelesaikan captcha atau berinteraksi dengan elemen halaman yang memerlukan tindakan tertentu.
Selenium menyediakan metode eksekusi_script() untuk mengeksekusi kode JavaScript dengan lancar dalam halaman web. Cukup berikan kode JavaScript ke metode ini sebagai string dan Selenium akan mengeksekusinya pada halaman yang sedang dimuat:
paragraph_text_js = driver.execute_script("return document.querySelector('p').textContent;")Penggunaan JavaScript di Selenium memperluas kemungkinan pengumpulan data, terutama ketika metode standar Selenium tidak memadai atau terbukti tidak efisien. Pendekatan ini meningkatkan fleksibilitas scraping, memungkinkan ekstraksi data dari berbagai sumber, dan melewati batasan situs web dinamis.
Diploma
Singkatnya, menggores halaman web dinamis adalah topik penting yang mendapat banyak perhatian. Tujuan artikel ini adalah untuk menjelaskan perbedaan antara halaman web statis dan konten dinamis, penerapan konten dinamis, dan metode pengumpulan data dari halaman web dinamis.
Kami telah melihat alat dan perpustakaan paling populer untuk menyalin situs web dinamis dengan Python, termasuk BeautifulSoup, Selenium, Pyppeteer, Playwright, dan Scrapy. Selain itu, kami mengeksplorasi prinsip penggunaan API web scraping untuk mengumpulkan konten dinamis.
Berdasarkan analisis, BeautifulSoup dan Scrapy tidak cocok untuk menggores situs web dinamis karena keterbatasan fungsinya. Sebaliknya, Selenium, Pyppeteer, atau web scraping API adalah opsi yang lebih cocok.