
Apakah Anda lelah diblokir atau masuk daftar hitam dari proyek web scraping Anda? Ada beberapa praktik terbaik yang dapat Anda ikuti untuk menghindari proses ekstraksi data web yang gagal.
Dalam panduan dasar-dasar pengikisan web ini, kami akan menunjukkan kepada Anda 10 tip cerdas dan alat yang direkomendasikan untuk memastikan proyek pengikisan web Anda berjalan lancar dan Anda dapat melewati tindakan anti-bot scraping yang paling sulit sekalipun.
Daftar Isi
Rintangan umum dalam pengikisan situs web
Sebelum kita langsung membahas tips pengikisan web, pertama-tama Anda perlu memahami tindakan anti-bot umum apa yang mungkin Anda hadapi saat menggores data web.
Umumnya, situs web melindungi datanya dari ekstraksi menggunakan berbagai metode, antara lain:
- Deteksi alamat IP
- Verifikasi tajuk permintaan HTTP
- CAPTCHA
- Pemeriksaan JavaScript
Sekarang, kapan Membangun web scraper yang besarAnda harus memberikan perhatian khusus untuk melewati sistem anti-bot ini. Mengikuti 10 tips web scraping berikut akan membantu Anda mencapai web scraping yang sukses. Namun, ada cara yang lebih mudah untuk menjamin tingkat keberhasilan ekstraksi data 99,9 % dengan menggunakan alat pengikis web seperti ScraperAPI.
ScraperAPI memungkinkan Anda mengumpulkan data dari situs web publik mana pun. Ini menangani proxy, browser, dan manajemen CAPTCHA untuk Anda. Anda bahkan dapat mengatur proyek web scraping agar berjalan sesuai jadwal DataPipeline dari ScraperAPI Solusi atau dapatkan data dalam format JSON langsung menggunakan khusus ScraperAPI API untuk Google, Amazon, dan Walmart. Jika Anda tertarik untuk mencobanya, Daftar untuk uji coba gratis 7 hari di sini (5.000 kredit API).
10 Praktik Terbaik untuk Proyek Pengikisan Web yang Sukses
Berikut beberapa tip pengikisan web yang berguna untuk membantu Anda mengekstrak data web tanpa diblokir atau masuk daftar hitam.
1. Rotasi IP
Cara terbaik bagi situs web untuk mendeteksi web scraper adalah dengan memeriksa alamat IP dan melacak perilakunya.
Jika server mendeteksi pola, perilaku aneh, atau frekuensi permintaan yang tidak mungkin (untuk beberapa nama) untuk pengguna sebenarnya, server dapat memblokir alamat IP agar tidak dapat mengakses situs web lagi.
Untuk menghindari pengiriman semua permintaan Anda melalui alamat IP yang sama, Anda dapat menggunakan layanan rotasi IP seperti ScraperAPI atau layanan proxy lainnya untuk merutekan permintaan Anda melalui kumpulan proxy, sehingga menggunakan alamat IP Anda yang sebenarnya saat menyalin situs web Hide. Ini memungkinkan Anda menjelajahi sebagian besar situs web dengan mudah.
Namun, tidak semua proxy diciptakan sama. Untuk situs web yang menggunakan mekanisme anti-scraping proxy tingkat lanjut, Anda mungkin perlu mencoba menggunakan proxy pribadi.
Jika Anda tidak tahu apa artinya, Anda dapat membaca artikel kami tentang berbagai jenis proxy untuk mempelajari perbedaannya.
Pada akhirnya, scraper Anda dapat menggunakan rotasi IP untuk membuat permintaan tampak berasal dari pengguna yang berbeda dan meniru perilaku normal lalu lintas online.
Saat Anda menggunakan ScraperAPI, sistem rotasi IP cerdas kami memanfaatkan analisis statistik dan pembelajaran mesin selama bertahun-tahun untuk merotasi proxy Anda sesuai kebutuhan dari kumpulan pusat data, proxy perumahan, dan seluler untuk memastikan tingkat keberhasilan 99,99 %.
Coba gratis selama 7 hari dengan 5.000 kredit API.
2. Tetapkan agen pengguna sebenarnya
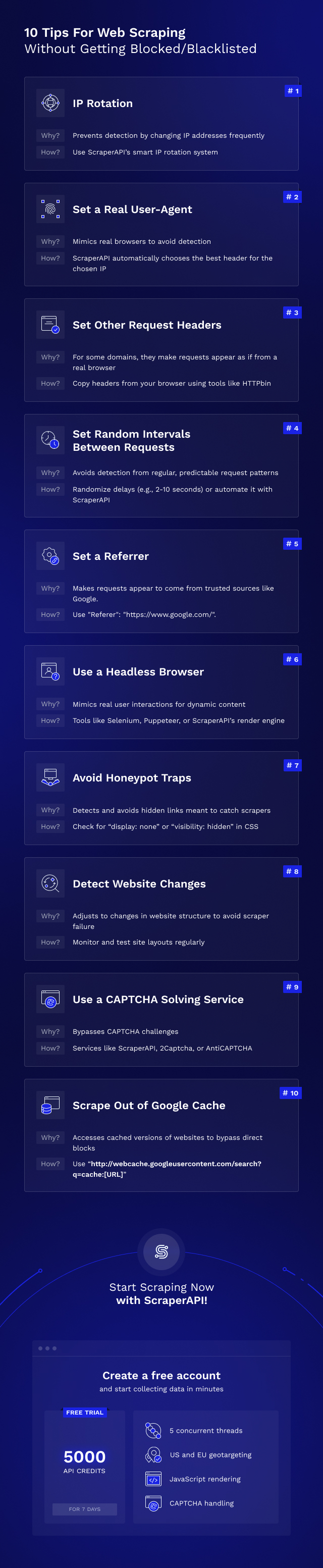
Agen pengguna adalah jenis header HTTP khusus yang memberi tahu situs web yang Anda kunjungi dengan tepat browser mana yang Anda gunakan.
Beberapa situs web memeriksa agen pengguna dan memblokir permintaan dari agen pengguna yang bukan milik browser utama. Karena sebagian besar web scraper tidak perlu mengatur agen pengguna, mereka mudah dikenali.
Jangan menjadi salah satu dari pengembang itu!
Ingatlah untuk menetapkan agen pengguna populer untuk perayap web Anda (berikut adalah daftar agen pengguna populer yang dapat Anda gunakan).
Untuk pengguna tingkat lanjut, Anda juga dapat menyetel agen pengguna Anda ke agen pengguna Googlebot karena sebagian besar situs web ingin dicantumkan di Google dan oleh karena itu ingin memberikan Googlebot akses ke konten mereka.
Catatan: Ya, Google digunakan Pengikisan web.
Penting untuk diingat untuk selalu memperbarui agen pengguna yang Anda gunakan. Setiap pembaruan baru Google Chrome, Safari, Firefox, dll. memiliki agen pengguna yang sangat berbeda. Jadi, jika Anda tidak mengubah agen pengguna perayap selama bertahun-tahun, perayap tersebut akan semakin mencurigakan.
Mungkin juga masuk akal untuk beralih di antara beberapa agen pengguna yang berbeda sehingga tidak terjadi lonjakan permintaan secara tiba-tiba dari agen pengguna tertentu ke suatu situs (ini juga akan cukup mudah dideteksi).
Kabar baiknya adalah Anda tidak perlu khawatir tentang hal ini saat menggunakan ScraperAPI.
3. Tetapkan header permintaan lainnya
Peramban web sebenarnya memiliki berbagai macam tajuk yang dapat diperiksa oleh situs web yang rajin untuk memblokir pengikis web Anda.
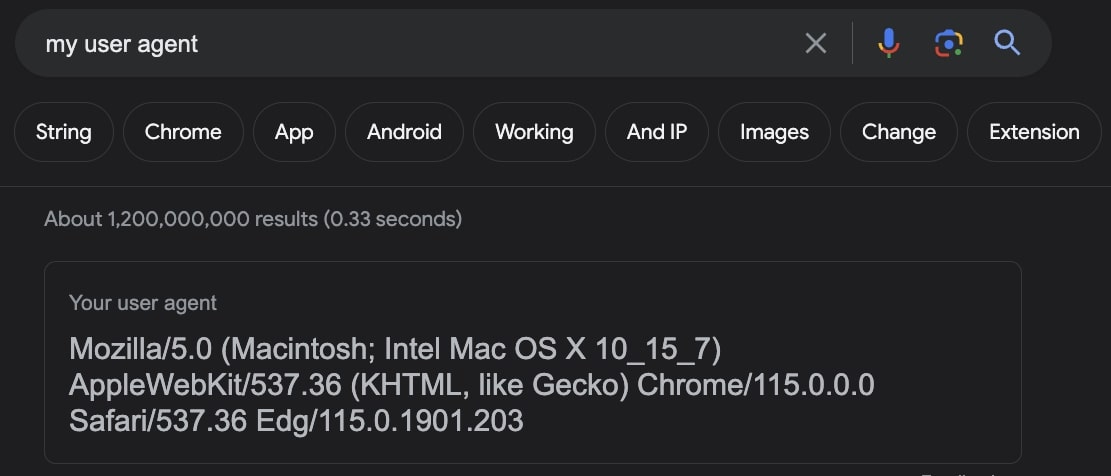
Untuk membuat scraper Anda terlihat seperti browser asli, Anda dapat menavigasi ke https://httpbin.org/anything dan cukup salin header yang Anda lihat di sana (ini adalah header yang digunakan browser web Anda saat ini).
Dengan menetapkan hal-hal seperti Accept, Accept-Encoding, Accept-Language, dan Upgrade-Insecure-Requests, permintaan Anda akan terlihat seperti berasal dari browser sebenarnya, sehingga web scraping tidak akan diblokir.
Dengan menelusuri berbagai alamat IP dan mengatur header permintaan HTTP yang benar (khususnya agen pengguna), Anda seharusnya dapat menghindari deteksi oleh 99 % situs web.
Berikut adalah panduan lengkap untuk mendapatkan header dan cookie terbaik untuk web scraping.
4. Tetapkan interval acak antara permintaan scraping situs web Anda
Sangat mudah untuk menemukan web scraper yang mengirimkan tepat satu permintaan setiap detik, 24 jam sehari! Tidak ada orang sungguhan yang akan menggunakan situs web seperti ini - ditambah lagi, pola yang jelas seperti ini mudah dikenali.
Gunakan penundaan acak (misalnya antara 2 dan 10 detik) untuk membuat web scraper yang dapat menghindari pemblokiran.
Ingatlah juga untuk bersikap sopan. Mengirim permintaan terlalu cepat dapat membuat situs mogok bagi semua orang. Jika Anda menyadari bahwa permintaan Anda semakin lambat, Anda mungkin ingin mengirim permintaan lebih lambat sehingga Anda tidak membebani server web (Anda harus melakukan ini untuk melindungi kerangka kerja seperti Scrapy agar tidak diblokir).
Pastikan Anda mengikuti praktik terbaik web scraping untuk menghindari masalah seperti itu.
Untuk perayap yang sangat sopan, Anda dapat menelusuri file robots.txt situs web (terletak di http://example.com/robots.txt atau http://www.example.com/robots.txt) untuk baris mana pun yang bertuliskan “Perayapan Delay” dan menunjukkan berapa detik Anda harus menunggu di antara permintaan.
 Ingat, Internet adalah untuk semua orang!
Ingat, Internet adalah untuk semua orang!
5. Tetapkan referensi
Header Referer adalah header permintaan HTTP yang memberi tahu situs dari mana Anda berasal.
Secara umum, sebaiknya atur ini agar terlihat seperti Anda berasal dari Google.
Anda dapat melakukan ini dengan tajuk:
“Referer”: “https://www.google.com/”
Anda juga dapat mengubahnya untuk situs web di negara lain. MisalnyaJika Anda mencoba menelusuri situs web di Inggris Raya, Anda harus menggunakan “https://www.google.co.uk/” dan bukan “https://www.google.com/”.
Anda juga dapat mencari referensi paling umum ke suatu situs web menggunakan alat seperti https://www.similarweb.com. Seringkali ini adalah situs media sosial seperti YouTube.
Dengan menyetel tajuk ini, Anda dapat memberikan permintaan Anda tampilan yang lebih autentik, karena tampaknya permintaan tersebut merupakan lalu lintas dari situs web yang diharapkan oleh webmaster untuk menerima banyak lalu lintas selama penggunaan normal.
Lima strategi berikutnya sedikit lebih rumit untuk diterapkan, namun jika Anda masih tidak dapat mengakses datanya, patut dicoba.
6. Gunakan browser tanpa kepala
Situs web yang paling sulit untuk dipindai dapat mendeteksi informasi halus seperti font web, ekstensi, cookie browser, dan eksekusi Javascript untuk menentukan apakah permintaan tersebut berasal dari pengguna sebenarnya atau tidak.
Untuk merayapi situs-situs ini, Anda mungkin perlu menggunakan browser tanpa kepala Anda sendiri (atau biarkan ScraperAPI melakukannya untuk Anda!).
Alat seperti Selenium dan Puppeteer memungkinkan Anda menulis program untuk mengontrol browser web sebenarnya, identik dengan apa yang akan digunakan pengguna sebenarnya, untuk sepenuhnya menghindari deteksi.
Sumber gambar: Toptal
Meskipun memerlukan sedikit usaha untuk membuat Selenium atau Puppeteer tidak terdeteksi, ini adalah metode paling efektif untuk menghapus situs web yang sebelumnya tidak mungkin dilakukan.
Namun, ini harus menjadi sumber terakhir karena ada banyak cara untuk menyiasati konten dinamis sekalipun.
Misalnya, jika situs web memerlukan JavaScript untuk dieksekusi sebelum konten dimasukkan, Anda dapat menggunakan ScraperAPI untuk merender halaman sebelum mengembalikan HTML yang dihasilkan.
Solusi lain yang mungkin adalah menemukan API tersembunyi yang menjadi sumber data situs web. Kami menggunakan pendekatan ini untuk mengumpulkan data pekerjaan dari LinkedIn.
Skenario yang mungkin untuk menggunakan browser tanpa kepala adalah bahwa interaksi dengan situs web memerlukan 100 % (misalnya mengklik tombol) dan Anda tidak dapat menemukan file tempat aplikasi mengumpulkan data.
7. Hindari perangkap honeypot
Banyak situs web mencoba mendeteksi perayap web dengan menyisipkan tautan tak kasat mata yang hanya bisa diikuti oleh robot.
Untuk menghindarinya, Anda perlu menentukan apakah suatu tautan memiliki properti CSS "display: none" atau "visibilitas: tersembunyi". Jika ini masalahnya, hindari mengikuti tautan ini. Jika tidak, server dapat mendeteksi scraper Anda, mengambil sidik jari karakteristik permintaan Anda, dan memblokir Anda dengan mudah.
Honeypots adalah salah satu cara termudah bagi webmaster cerdas untuk mendeteksi crawler. Jadi pastikan Anda melakukan pemeriksaan ini pada setiap halaman yang Anda jelajahi.
Webmaster tingkat lanjut juga dapat dengan mudah mengatur warnanya menjadi putih (atau warna apa pun yang menjadi warna latar belakang laman). Jadi, Anda harus memeriksa apakah tautan tersebut berisi sesuatu seperti “Warna: #fff;”. atau “color: #ffffff” karena ini pada dasarnya akan membuat tautan tidak terlihat.
8. Mendeteksi perubahan situs web
Banyak situs web mengubah tata letak karena berbagai alasan, yang sering kali menyebabkan kerusakan pada scraper.
Selain itu, beberapa situs web memiliki tata letak yang berbeda di tempat yang tidak terduga (halaman 1 hasil penelusuran mungkin memiliki tata letak yang berbeda dengan halaman 4). Hal ini berlaku bahkan untuk perusahaan-perusahaan besar yang kurang paham teknologi, misalnya. B. toko retail besar yang saat ini sedang melakukan transisi ke bisnis online.
Anda perlu mendeteksi perubahan ini dengan benar saat membuat scraper dan membuat pemantauan berkelanjutan sehingga Anda tahu bahwa crawler Anda masih berfungsi (biasanya cukup menghitung jumlah permintaan yang berhasil per crawl).
Cara mudah lainnya untuk mengatur pemantauan adalah dengan melakukan hal berikut: Tulis pengujian unit untuk URL tertentu di situs web atau URL jenis apa pun.
Misalnya, di situs ulasan Anda mungkin menulis:
- Tes unit untuk halaman hasil pencarian
- Tes unit untuk halaman ulasan
- Tes unit untuk halaman produk utama
Dan sebagainya.
Hal ini memungkinkan Anda memeriksa perubahan situs web yang penting hanya dengan beberapa permintaan setiap 24 jam atau lebih, tanpa harus melakukan perayapan penuh untuk menemukan kesalahan.
9. Gunakan layanan pemecah CAPTCHA
Salah satu cara paling umum bagi situs web untuk memerangi crawler adalah dengan menampilkan CAPTCHA.
Untungnya, ada layanan yang dirancang khusus untuk mengatasi keterbatasan ini dengan cara yang ekonomis, baik itu solusi terintegrasi penuh seperti ScraperAPI atau pemecah CAPTCHA sempit yang dapat Anda integrasikan hanya untuk fungsionalitas pemecah CAPTCHA, seperti 2Captcha atau AntiCAPTCHA.
Seperti yang dapat Anda bayangkan, tidak ada cara untuk menyelesaikan masalah ini dengan skrip pengumpulan data sederhana. Oleh karena itu, mereka sangat efektif dalam memblokir sebagian besar pencakar.
Beberapa layanan penyelesaian CAPTCHA ini cukup lambat dan mahal, jadi Anda mungkin perlu mempertimbangkan apakah masih ekonomis untuk menjelajahi situs web yang memerlukan penyelesaian CAPTCHA terus-menerus dari waktu ke waktu.
Catatan: ScraperAPI memproses CAPTCHAS secara otomatis dan tanpa biaya tambahan untuk Anda.
10. Mengikis dari cache Google
Sebagai upaya terakhir, terutama untuk data yang tidak terlalu sering berubah, Anda mungkin dapat mengekstrak data dari salinan situs yang disimpan dalam cache Google, bukan dari situs itu sendiri.
Letakkan saja di depan “http://webcache.googleusercontent.com/search?q=cache:” ke awal URL.
Misalnya, untuk mencari dokumentasi ScraperAPI, Anda dapat mengirimkan permintaan Anda ke:
“http://webcache.googleusercontent.com/search?q=cache:https://www.scraperapi.com/documentation/”.
Ini adalah solusi yang baik untuk informasi yang tidak sensitif terhadap waktu yang terletak di situs web yang sangat sulit dipindai.
Meskipun mengikis dari cache Google mungkin sedikit lebih dapat diandalkan daripada mengikis situs web yang secara aktif mencoba memblokir pengikis Anda, perlu diingat bahwa ini bukanlah solusi yang sangat mudah.
Beberapa situs seperti LinkedIn secara aktif memberi tahu Google untuk tidak menyimpan data mereka dalam cache, dan data untuk situs yang tidak populer mungkin sudah ketinggalan zaman karena Google menentukan seberapa sering situs akan dirayapi berdasarkan popularitas situs dan jumlah halaman di situs tersebut.
Lewati blok pengikisan web dengan mudah menggunakan ScraperAPI
Semoga Anda telah mempelajari beberapa tips berguna untuk melakukan web scraping pada situs web populer tanpa diblokir, masuk daftar hitam, atau dilarang IP.
Jika Anda tidak ingin menerapkan semua teknik ini dari awal atau sedang mengerjakan proyek yang sensitif terhadap waktu, buat akun ScraperAPI gratis dan mulailah mengumpulkan data dalam hitungan menit.
Sampai jumpa lagi, selamat melakukan web scraping!