
Dalam tutorial ini Anda akan mempelajari cara:
- Gunakan Python dan BeautifulSoup untuk mengekstrak data dari Trustpilot.
- Ekspor data penting ini ke file CSV.
- Gunakan ScraperAPI untuk mengatasi perlindungan anti-goresan Trustpilot.
TL;DR: Pengikis ulasan TrustPilot lengkap
Ini kode yang sudah selesai untuk mereka yang sedang terburu-buru:
from bs4 import BeautifulSoup
import requests
import csv
company = "nookmart.com"
base_url = f"https://www.trustpilot.com/review/{company}"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'accept-language': 'en-US,en;q=0.9'
}
payload = {
'api_key': "YOUR API KEY",
'url': base_url,
'render': 'true',
'keep_headers': 'true',
}
try:
response = requests.get('https://api.scraperapi.com', params=payload, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
pages_to_scrape = 10
with open('trustpilot_reviews.csv', 'w', newline='', encoding='utf-8') as csvfile:
csv_writer = csv.writer(csvfile)
csv_writer.writerow(('Reviewer', 'Rating', 'Review', 'Date'))
for page in range(1, pages_to_scrape):
payload('url') = f"{base_url}?page={page}"
page_response = requests.get('https://api.scraperapi.com', params=payload, headers=headers)
page_soup = BeautifulSoup(page_response.content, 'html.parser')
reviews = page_soup.find_all('div', {"class": "styles_reviewCardInner__EwDq2"})
for review in reviews:
reviewer = review.find("span", attrs={"class": "typography_heading-xxs__QKBS8"}).text
rating = review.find("div", attrs={"class": "styles_reviewHeader__iU9Px"})("data-service-review-rating")
content_element = review.find("p", attrs={"class": "typography_body-l__KUYFJ"})
content = content_element.text if content_element else 'None'
date = review.find("p", attrs={"class":"typography_body-m__xgxZ_ typography_appearance-default__AAY17"}).text
csv_writer.writerow((reviewer, rating, content, date))
print("Data Extraction Successful!")
except Exception as e:
print("An error occurred:", e)
Sebelum menjalankan kode, tambahkan kunci API Anda api_key Parameter dalam payload.
Catatan: Tidak punya kunci API? Buat akun ScraperAPI gratis untuk mendapatkan 5.000 kredit API dan coba semua alat kami selama 7 hari.
Ingin melihat bagaimana kami membangunnya? Baca terus dan bergabunglah dengan kami dalam perjalanan menggores yang mengasyikkan ini!
Persyaratan
Sebelum kita mulai mengambil ulasan Trustpilot, penting untuk menyiapkan lingkungan kita dengan semua alat dan perpustakaan penting. Berikut cara memulainya:
- Instalasi ular piton: Pastikan Anda telah menginstal Python, idealnya versi 3.10 atau lebih baru, yang dapat Anda unduh dari situs web resmi Python.
- Instalasi perpustakaan: Kami membutuhkan dua perpustakaan Python penting –
requestsDanBeautifulSoup(bs4). Buka terminal atau command prompt Anda dan instal menggunakan perintah berikut:
pip install requests beautifulsoup4
requests: Pustaka ini adalah alat tepercaya kami untuk mengirim permintaan HTTP ke ScraperAPI. Penting untuk mengambil konten HTML dari Trustpilot dan bertindak sebagai jembatan antara skrip kami dan situs web. Pada dasarnya, ini mengambil kode HTML yang kami perlukan dan memainkan peran penting dalam menghubungkan upaya ekstraksi data kami dengan ulasan online Trustpilot.- bs4 (
Beautiful Soup): BeautifulSoup adalah sumber utama kami untuk penguraian HTML. Ini menavigasi struktur kompleks halaman web Trustpilot dan memungkinkan kami mengekstrak data spesifik yang kami perlukan - ulasan, peringkat, dan komentar pengguna. Parser yang kuat ini mempermudah pencarian melalui struktur halaman yang kompleks dan memungkinkan kita mengekstrak data yang bermakna secara efisien.
Pahami tata letak situs web Trustpilot
Sekarang setelah kita menyiapkan lingkungan scraping, mari kita lihat lebih dekat pengaturan situs web Trustpilot untuk melihat bagaimana informasi yang kita perlukan disimpan di situs web.
Penting bagi kami untuk memahami tata letak situs web dan mengidentifikasi elemen HTML utama yang berisi data ulasan. Kami perlu mengidentifikasi dan mengekstrak detail penting dari setiap ulasan, seperti peringkat, komentar pelanggan, dan nama pengulas.
Menggunakan struktur situs web Trustpilot menyederhanakan proses pengikisan kami dan memastikan kami secara akurat menangkap wawasan berharga yang diberikan oleh ulasan ini.
Pada artikel ini, kita melihat halaman ulasan Trustpilot dari perusahaan “Nookmart”, sebuah platform online tempat pemain game “Animal Crossing: New Horizons” dapat membeli berbagai item dalam game.
Berikut tampilan situs di Trustpilot:
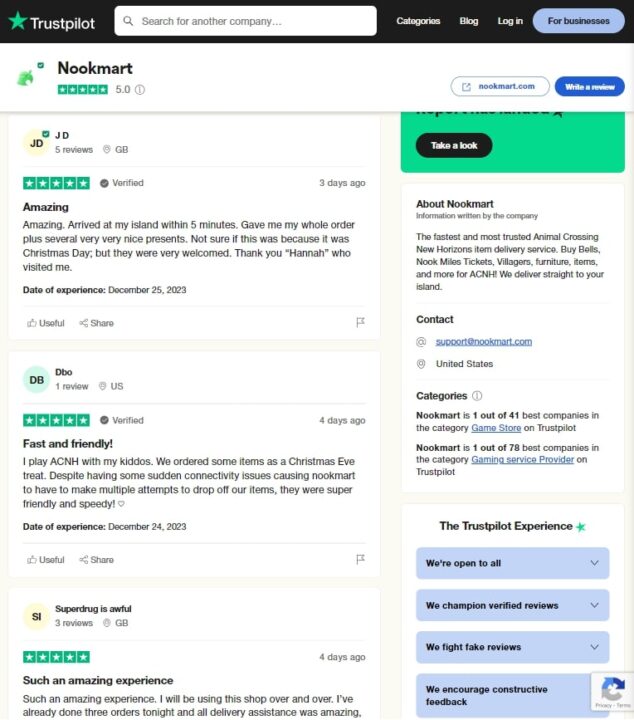
Kami akan menelusuri setiap ulasan individual, jadi kami perlu menemukan elemen HTML yang berisi data yang kami perlukan. Untuk melakukan ini, kita akan menggunakan alat pengembang (klik kanan pada halaman web dan pilih "Periksa") untuk memeriksa struktur HTML.
Itu div Tag berisi informasi tentang setiap ulasan individu: styles_reviewCardInner__EwDq2.
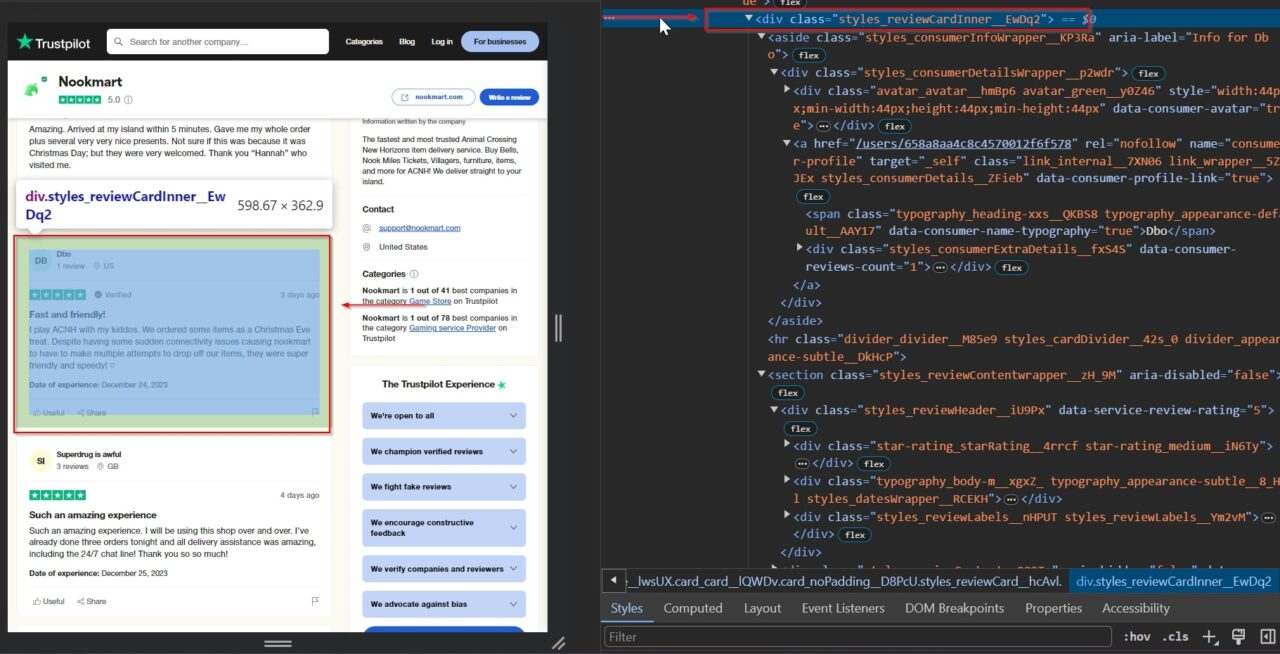
Mengekstrak nama pengulas dari Trustpilot membantu mengautentikasi ulasan, memungkinkan analisis tren dari umpan balik berulang, dan memfasilitasi keterlibatan pelanggan yang dipersonalisasi.
Selain itu, ini juga dapat memberikan wawasan demografis dan membantu membuat profil untuk peninjau yang sering melakukan peninjauan.
Itu span Tag berisi nama pengulas:
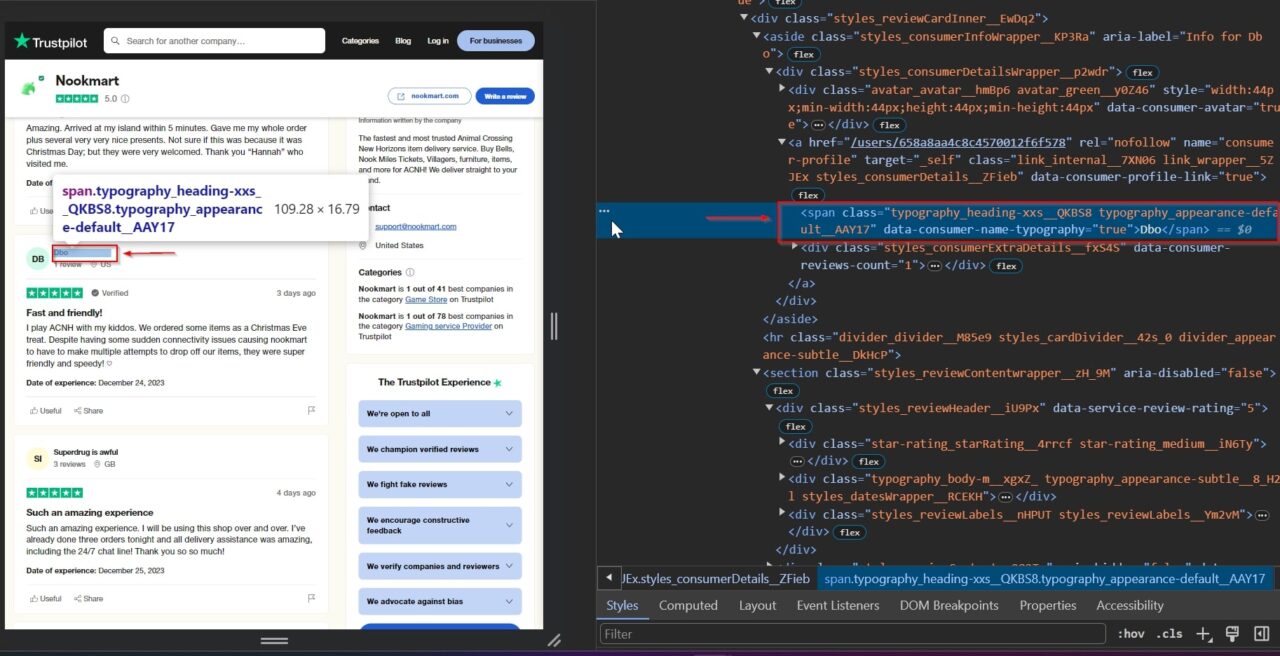
Kami juga akan menghapus peringkat pengulas. Ulasan memberikan ukuran langsung terhadap kepuasan pelanggan, yang sangat penting untuk menilai kualitas produk atau layanan. Mereka memungkinkan Anda menilai sentimen pelanggan secara keseluruhan, melacak tren kinerja, dan melakukan analisis komparatif dengan pesaing.
Menganalisis ulasan ini dapat mengungkapkan area utama yang perlu ditingkatkan dan membantu meningkatkan penawaran bisnis.
Tag div ini berisi peringkat: styles_reviewHeader__iU9Px. Itu disimpan dalam atribut yang disebut data-service-review-rating.
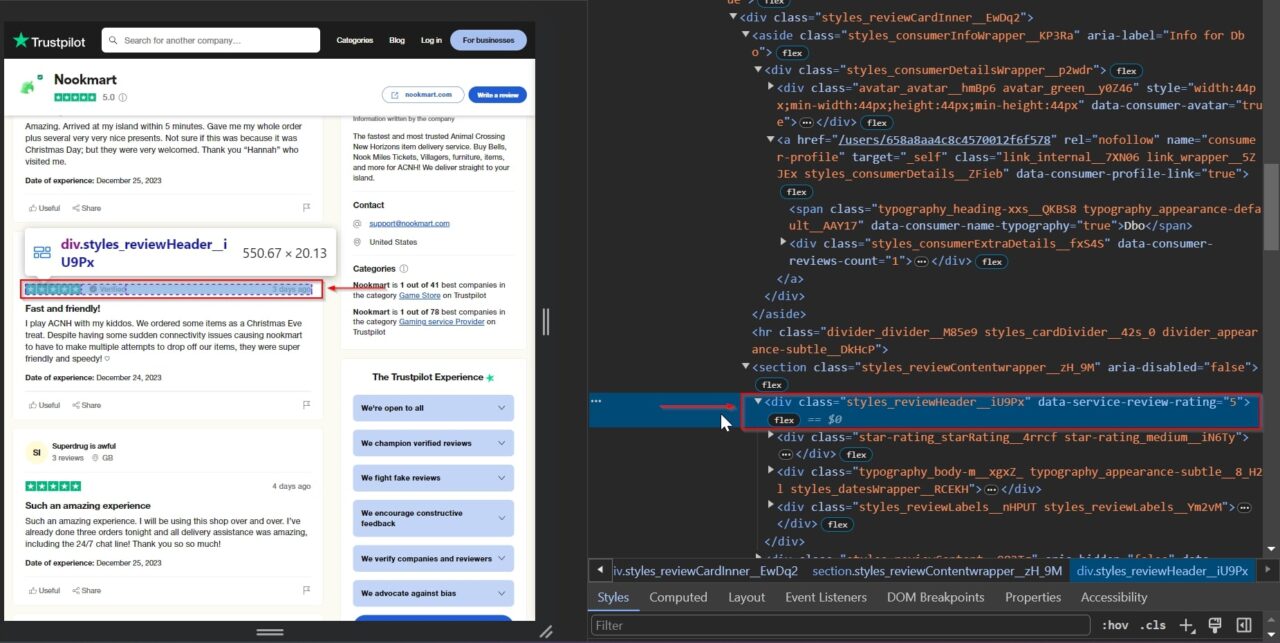
Kami juga akan mengekstrak konten ulasan sebenarnya, yang merupakan kunci untuk membuka wawasan pelanggan yang lebih mendalam. Konten ini sangat berharga untuk mendapatkan wawasan lebih dalam tentang kepuasan pelanggan karena memberikan umpan balik terperinci yang lebih dari sekadar ulasan.
Memahami nuansa ini akan membantu melakukan perbaikan yang ditargetkan, membina hubungan pelanggan yang lebih baik, dan pada akhirnya meningkatkan kualitas penawaran Anda secara keseluruhan.
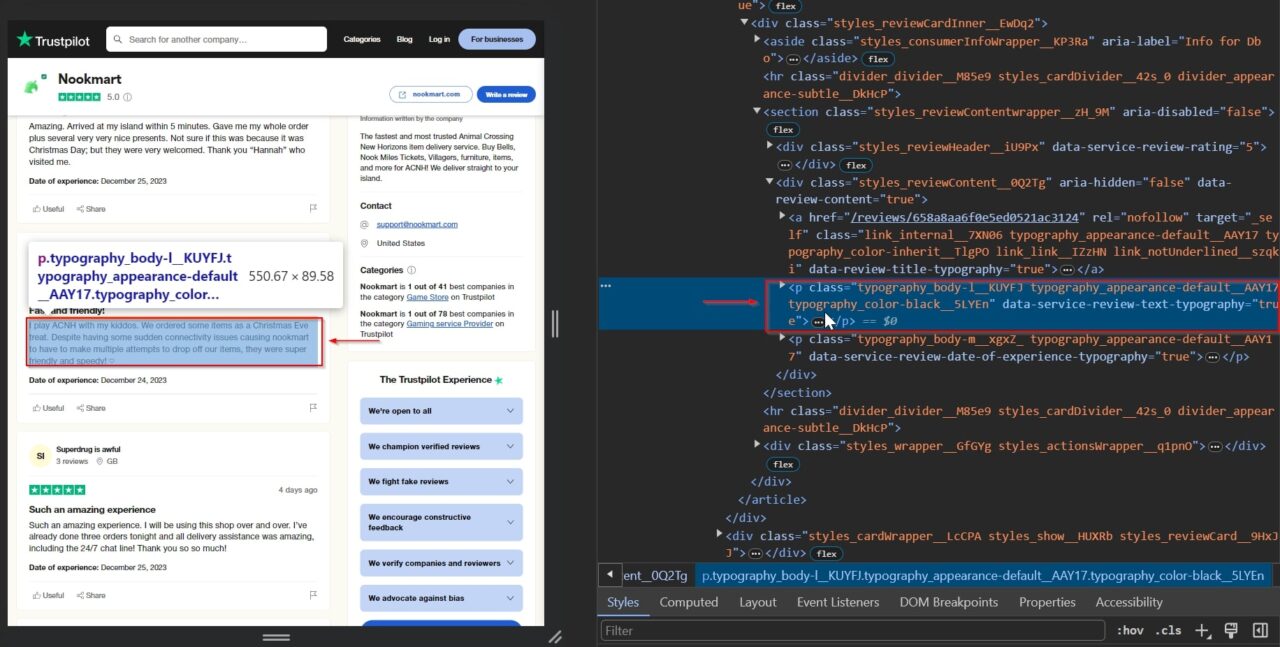
Itu p Tag berisi konten ulasan sebenarnya: typography_body-l__KUYFJ
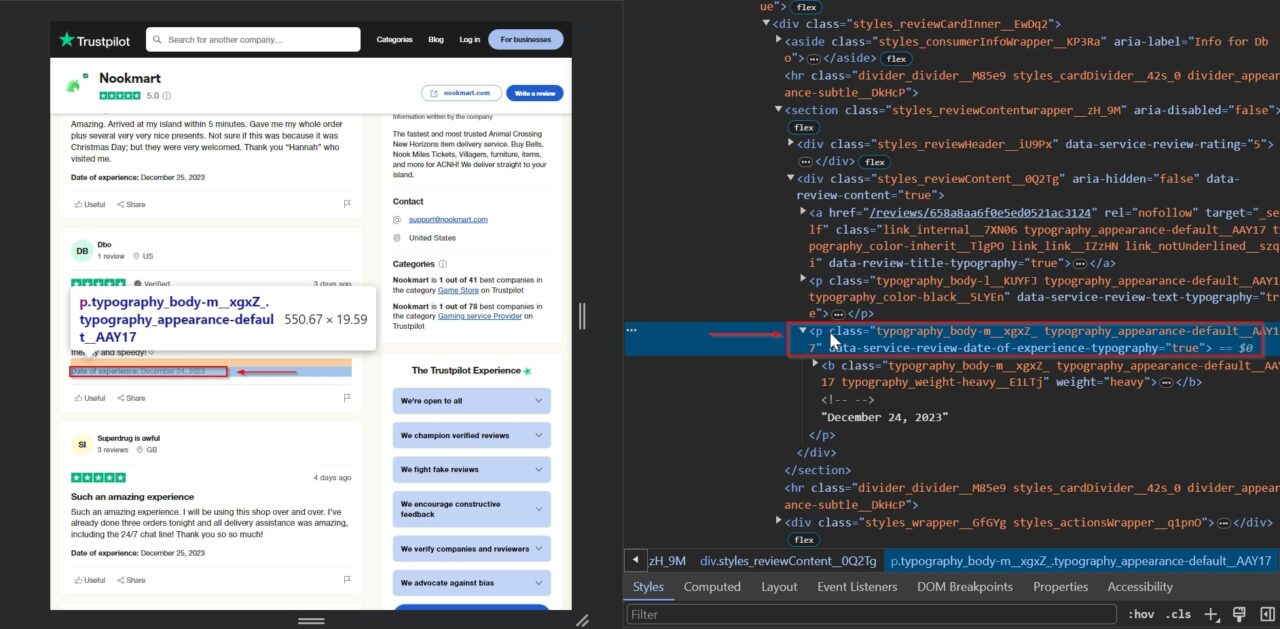
Terakhir, kami menghapus tanggal pelanggan mengalami apa yang mereka jelaskan dalam ulasan. Hal ini membantu memberikan konteks pada ulasan dan membantu kami memahami kapan pengalaman yang dijelaskan terjadi.
Itu p Hari berisi tanggal pengalaman: typography_body-m__xgxZ_ typography_appearance-default__AAY17.
Sekarang kita bisa mulai mengikis!
Kikis Trustpilot dengan Python
Untuk memindai ulasan Trustpilot, skrip kami secara sistematis menelusuri halaman ulasan dan mengumpulkan detail penting seperti nama pengulas, peringkat, konten ulasan, dan tanggal setiap pengalaman.
Pendekatan ini memastikan proses yang efisien dan otomatis yang memungkinkan kami mengumpulkan kumpulan data umpan balik pelanggan yang komprehensif untuk analisis mendalam.
Langkah 1: Impor perpustakaan dan tentukan URL target
Kami mulai dengan mengimpor perpustakaan Python yang diperlukan – BeautifulSoup untuk penguraian HTML, requests untuk membuat permintaan HTTP dan csv untuk operasi file.
Kami menentukan URL target dan mengarahkan ke halaman ulasan Trustpilot “nookmart.com”.
Itu company Variabelnya dapat diubah ke perusahaan mana pun yang ingin Anda cari.
from bs4 import BeautifulSoup
import requests
import csv
company = "nookmart.com"
base_url = f"https://www.trustpilot.com/review/{company}"
Langkah 2: Konfigurasikan parameter permintaan dan kirimkan permintaan
Selanjutnya, kita akan menyiapkan skrip kita untuk berinteraksi dengan web seperti browser. Kami menggunakan header HTTP dan "agen pengguna", sebuah string yang memberi tahu server Trustpilot jenis browser apa yang kami gunakan.
Payloadnya, termasuk kunci ScraperAPI dan URL Trustpilot kami, mengarahkan ScraperAPI ke halaman yang benar. Kami juga mengaktifkan rendering halaman penuh, memastikan konten dinamis dimuat.
headers = {
'User-Agent': 'Mozilla/5.0 ...',
'accept-language': 'en-US,en;q=0.9'
}
payload = {
'api_key': "YOUR_API_KEY",
'url': base_url,
'render': 'true',
'keep_headers': 'true',
}
Selanjutnya kami mengirimkan permintaan kami ke ScraperAPI; ScraperAPI kemudian mengakses halaman Trustpilot atas nama kami, mengambil tindakan anti-bot, dan mengambil konten HTML situs web, yang kemudian dapat diproses oleh skrip kami. Penyiapan ini adalah kunci keberhasilan pengikisan data dari situs web menggunakan teknologi anti-pengikisan.
response = requests.get('https://api.scraperapi.com', params=payload, headers=headers)
Langkah 3: Analisis Trustpilot dengan BeautifulSoup
Kami menggunakan BeautifulSoup untuk menganalisis konten HTML yang diterima dari Trustpilot. Ini membantu kami memecah struktur situs web untuk memudahkan ekstraksi data - yang sangat penting karena memungkinkan kami mengeluarkan ulasan dan menganalisisnya.
soup = BeautifulSoup(response.content, 'html.parser')
Langkah 4: Simpan ulasan Trustpilot ke file CSV
Setelah parsing, kita buka file CSV dengan nama 'trustpilot_reviews.csv' untuk menulis. Kami kemudian menyiapkan judul kolom yang menyimpan nama pengulas, peringkat, konten ulasan – termasuk ulasan negatif – dan tanggal ulasan.
with open('trustpilot_reviews.csv', 'w', newline='', encoding='utf-8') as csvfile:
csv_writer = csv.writer(csvfile)
csv_writer.writerow(('Reviewer', 'Rating', 'Review', 'Date'))
Langkah 5: Buka pagination Trustpilot dan ekstrak ulasan
Sekarang kita sampai pada inti proses pengikisan kita. Kami membaca 10 halaman ulasan Trustpilot untuk “Nookmart”.
Di setiap halaman, kami mengirimkan permintaan dan kemudian mengekstrak informasi penting dari setiap ulasan yang ada menggunakan elemen HTML yang telah diidentifikasi sebelumnya.
Untuk setiap ulasan yang ditemukan, kami menuliskan detail ini ke dalam ulasan kami trustpilot_reviews.csv file untuk memastikan data tertata rapi dan siap untuk analisis di masa mendatang.
Dengan memproses beberapa halaman, kami membuat kumpulan data kaya yang mewakili berbagai pengalaman dan opini pelanggan, memberikan pemahaman komprehensif tentang layanan perusahaan dari sudut pandang pelanggannya.
for page in range(1, pages_to_scrape):
payload('url') = f"{base_url}?page={page}"
page_response = requests.get('https://api.scraperapi.com', params=payload, headers=headers)
page_soup = BeautifulSoup(page_response.content, 'html.parser')
reviews = page_soup.find_all('div', {"class": "styles_reviewCardInner__EwDq2"})
for review in reviews:
reviewer = review.find("span", attrs={"class": "typography_heading-xxs__QKBS8"}).text
rating = review.find("div", attrs={"class": "styles_reviewHeader__iU9Px"})("data-service-review-rating")
content_element = review.find("p", attrs={"class": "typography_body-l__KUYFJ"})
content = content_element.text if content_element else 'None'
date = review.find("p", attrs={"class":"typography_body-m__xgxZ_ typography_appearance-default__AAY17"}).text
csv_writer.writerow((reviewer, rating, content, date))
Dengan cara ini, kami memastikan bahwa kami tidak terbatas pada ulasan di halaman pertama, namun memperkaya analisis kami dengan berbagai wawasan dari kumpulan ulasan pelanggan yang lebih besar.
