
TL;DR: Scraper Repo GitHub Lengkap
Ini adalah scraper repositori GitHub yang telah selesai bagi mereka yang sedang terburu-buru:
import requests
from bs4 import BeautifulSoup
import json
url = 'https://github.com/psf/requests'
payload = {
'api_key': 'YOUR_API_KEY',
'url': url,
'render': 'true',
}
page = requests.get('https://api.scraperapi.com', params=payload)
soup = BeautifulSoup(page.text, 'html.parser')
repo = {}
name_html_element = soup.find('strong', {"itemprop": "name"})
repo('name') = name_html_element.get_text().strip()
relative_time_html_element = soup.find('relative-time')
repo('latest_commit') = relative_time_html_element('datetime')
branch_element = soup.find('span', {"class": "Text-sc-17v1xeu-0 bOMzPg"})
repo('branch') = branch_element.get_text().strip()
commit_element = soup.find('span', {"class": "Text-sc-17v1xeu-0 gPDEWA fgColor-default"})
repo('commit') = commit_element.get_text().strip()
stars_element = soup.find('span', {"id": "repo-stars-counter-star"})
repo('stars') = stars_element.get_text().strip()
forks_element = soup.find('span', {"id": "repo-network-counter"})
repo('forks') = forks_element.get_text().strip()
description_html_element = soup.find('p', {"class":"f4 my-3"})
repo('description') = description_html_element.get_text().strip()
main_branch = repo('branch')
readme_url = f'https://raw.githubusercontent.com/psf/requests/{main_branch}/README.md'
readme_page = requests.get(readme_url)
if readme_page.status_code != 404:
repo('readme') = readme_page.text
print(repo)
with open('repo.json', 'w') as file:
json.dump(repo, file, indent=4)
print('Data saved to repo.json')
Sebelum menjalankan kode, tambahkan kunci API Anda ke
api_key Parameter dalam payload.
Catatan: Tidak punya kunci API? Buat akun ScraperAPI gratis untuk mendapatkan 5.000 kredit API dan coba semua alat kami selama tujuh hari.
Ingin melihat bagaimana kami membangunnya? Lanjut membaca!
Mengikis repo GitHub dengan Python
Langkah 1: Siapkan proyek Anda
Mulailah dengan menyiapkan lingkungan proyek Anda. Buat direktori baru untuk proyek Anda dan file baru untuk skrip Anda.
Jalankan perintah berikut di terminal Anda:
mkdir github-scraper
cd github-scraper
touch app.py
Langkah 2: Instal perpustakaan yang diperlukan
Untuk mengambil data dari GitHub, Anda memerlukan dua perpustakaan penting: permintaan dan BeautifulSoup. Perpustakaan ini menangani pengambilan halaman web dan penguraian kontennya.
requests memungkinkan Anda dengan mudah mengirim permintaan HTTP dengan Python dan
BeautifulSoup digunakan untuk mengurai dokumen HTML dan XML.
Instal kedua perpustakaan dengan pip:
pip install requests beautifulsoup4
Langkah 3: Unduh halaman arahan menggunakan ScraperAPI
Pilih repositori GitHub tempat Anda ingin mengambil data. Untuk contoh ini kita akan menggunakan repositori Permintaan.
Pertama kita mengimpor perpustakaan yang diperlukan: requests,
BeautifulSoupDan JSON; lalu kita setting URL repositori GitHub yang ingin kita scrap dengan mengetikkannya di
url Variabel.
import requests
from bs4 import BeautifulSoup
import json
url = 'https://github.com/psf/requests'
Selanjutnya, kami menyiapkan kamus payload yang berisi kunci API ScraperAPI Anda, URL, dan parameter render.
Parameter Render memastikan bahwa konten yang dirender oleh JavaScript disertakan dalam respons.
Catatan: Tidak punya kunci API? Buat akun ScraperAPI gratis untuk mendapatkan 5.000 kredit API dan coba semua alat kami selama 7 hari.
payload = {
'api_key': 'YOUR_API_KEY',
'url': url,
'render': 'true',
}
Kita gunakan requests.get() untuk mengirim permintaan GET ke ScraperAPI dan meneruskan payload sebagai parameter. ScraperAPI memproses permintaan, menangani rotasi IP untuk melewati tindakan anti-scraping, dan mengembalikan konten HTML.
page = requests.get('https://api.scraperapi.com', params=payload)
Penting
Kami mengirimkan permintaan kami melalui ScraperAPI untuk menghindari pemblokiran oleh sistem deteksi anti-bot GitHub.
ScraperAPI menggunakan pembelajaran mesin dan analisis statistik selama bertahun-tahun untuk memilih kombinasi IP dan header yang tepat dan secara cerdas mengganti keduanya bila diperlukan untuk memastikan permintaan berhasil.
Langkah 4: Parsing dokumen HTML
Setelah mendownload halaman target, langkah selanjutnya adalah mengurai dokumen HTML untuk mengekstrak data yang Anda butuhkan.
Kami meneruskan konten HTML ke BeautifulSoup untuk membuat pohon parse. Ini memungkinkan Anda menavigasi dan mencari struktur HTML dengan mudah:
soup = BeautifulSoup(page.text, 'html.parser')
Langkah 5: Pahami tata letak halaman repositori Github
Sebelum kita mengekstrak data, kita perlu mengidentifikasi elemen HTML pada halaman web yang berisi data yang kita butuhkan.
Untuk melakukannya, buka halaman repositori di browser Anda dan periksa struktur HTML menggunakan DevTools. Hal ini memungkinkan kami untuk lebih memahami cara memilih elemen dan mengekstrak data secara efektif. Dengan memeriksa tata letak halaman dan mengidentifikasi tag dan atribut, kita lebih siap untuk mengambil data yang kita perlukan.
Elemen pertama yang akan kita temukan adalah nama repositori. Jika Anda memeriksa halaman tersebut, Anda akan melihat bahwa nama repositori ada di a
Tandai dengan atribut
itemprop="name".
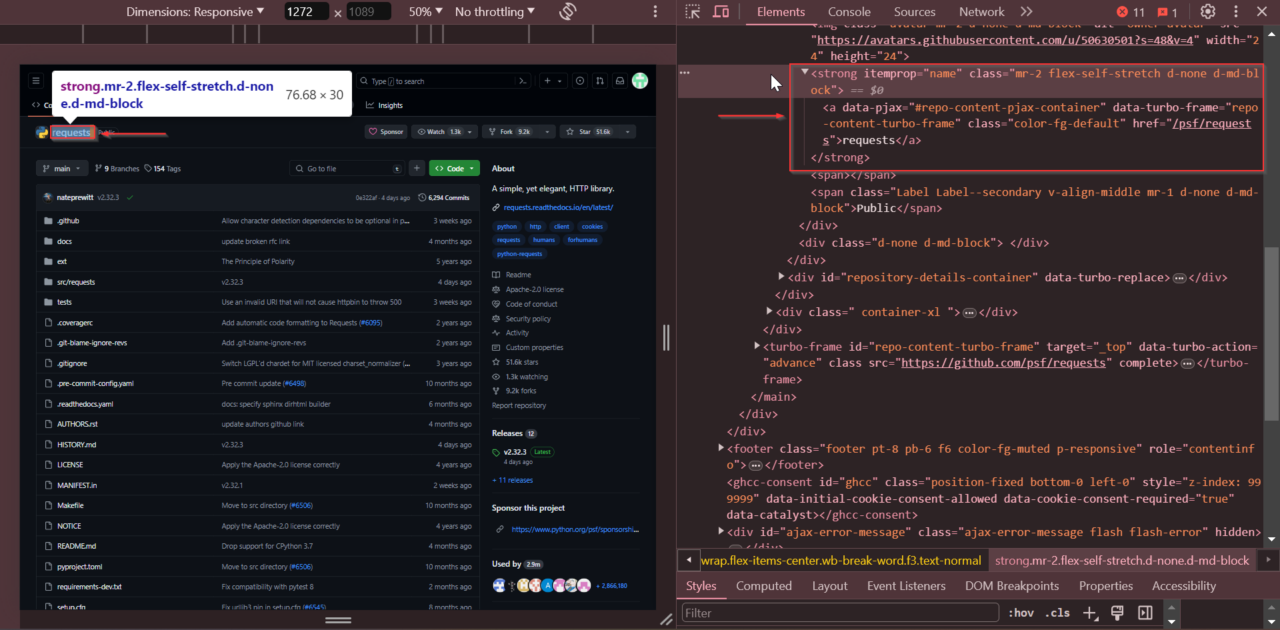
Selanjutnya, kita mencari waktu komit terakhir dari repositori. Gulir ke bagian “Riwayat Komit”, klik kanan tanggal komit terakhir, dan pilih “Periksa.”
Waktu komit terakhir berada dalam waktu komit pertama
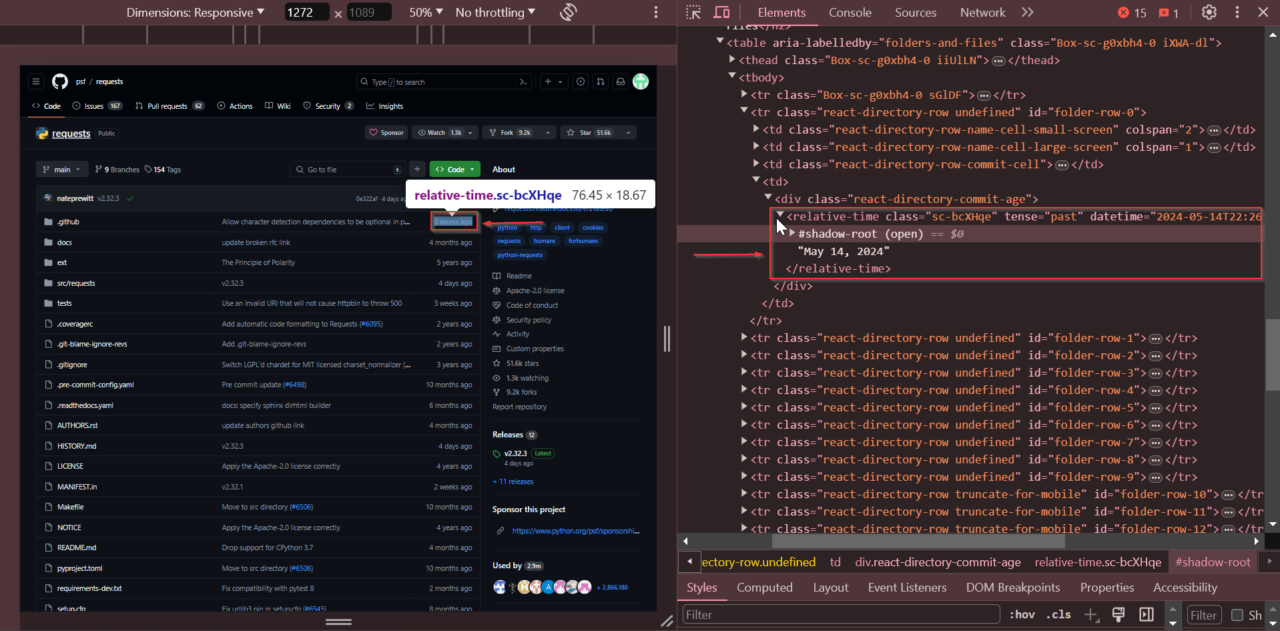
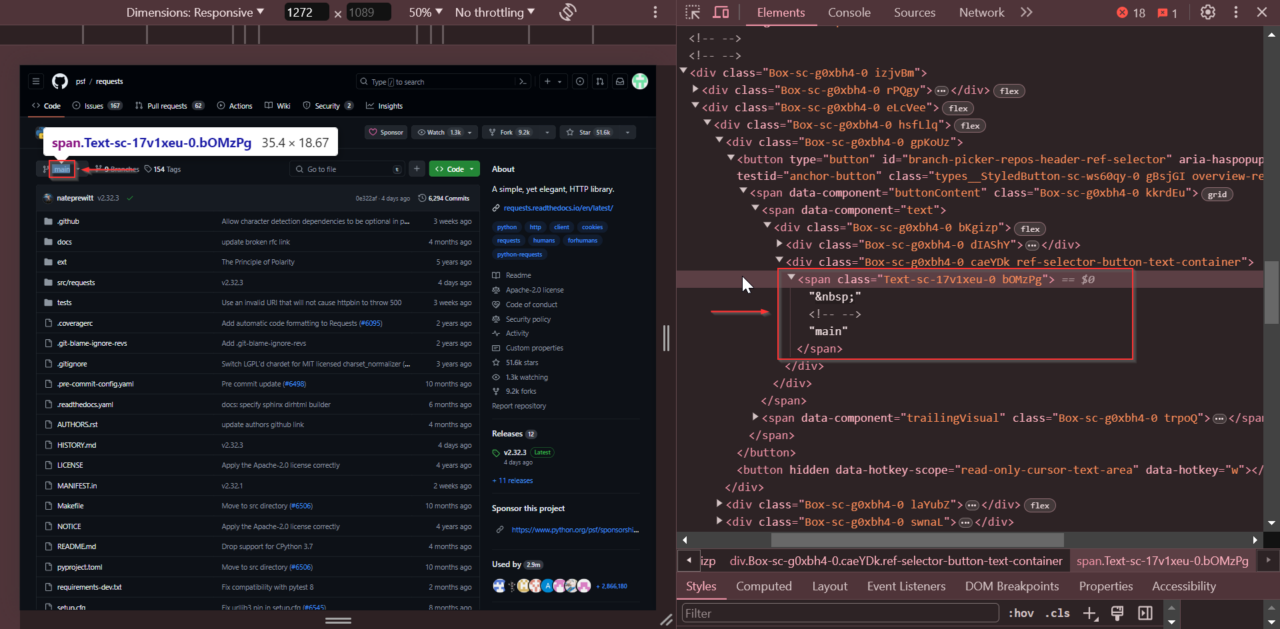
Kemudian kita mencari nama cabang saat ini. Lihat menu tarik-turun pemilihan cabang, klik kanan nama cabang, dan pilih “Periksa.”
Nama cabang disimpan di hari bersama kelas Text-sc-17v1xeu-0 bOMzPg.
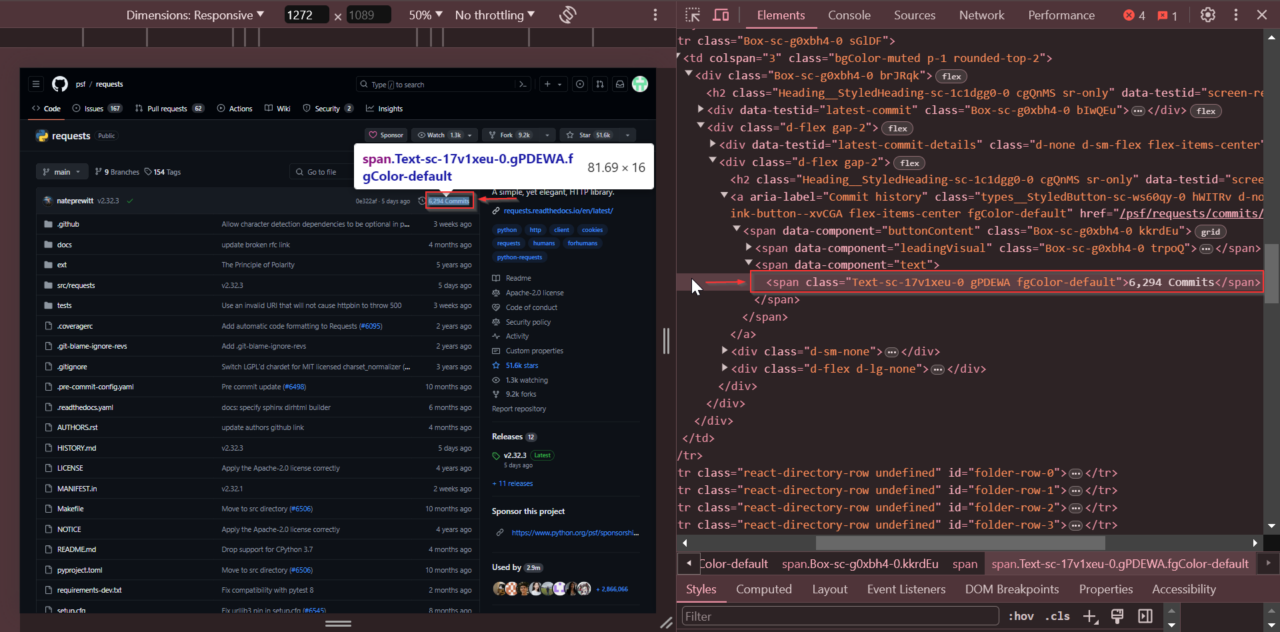
Selanjutnya, kami menentukan jumlah total komitmen. Temukan bagian yang menunjukkan jumlah total komitmen. Klik kanan jumlah komit dan pilih Periksa.
Jumlah komitmen ada dalam satu hari bersama kelas Text-sc-17v1xeu-0 gPDEWA fgColor-default.
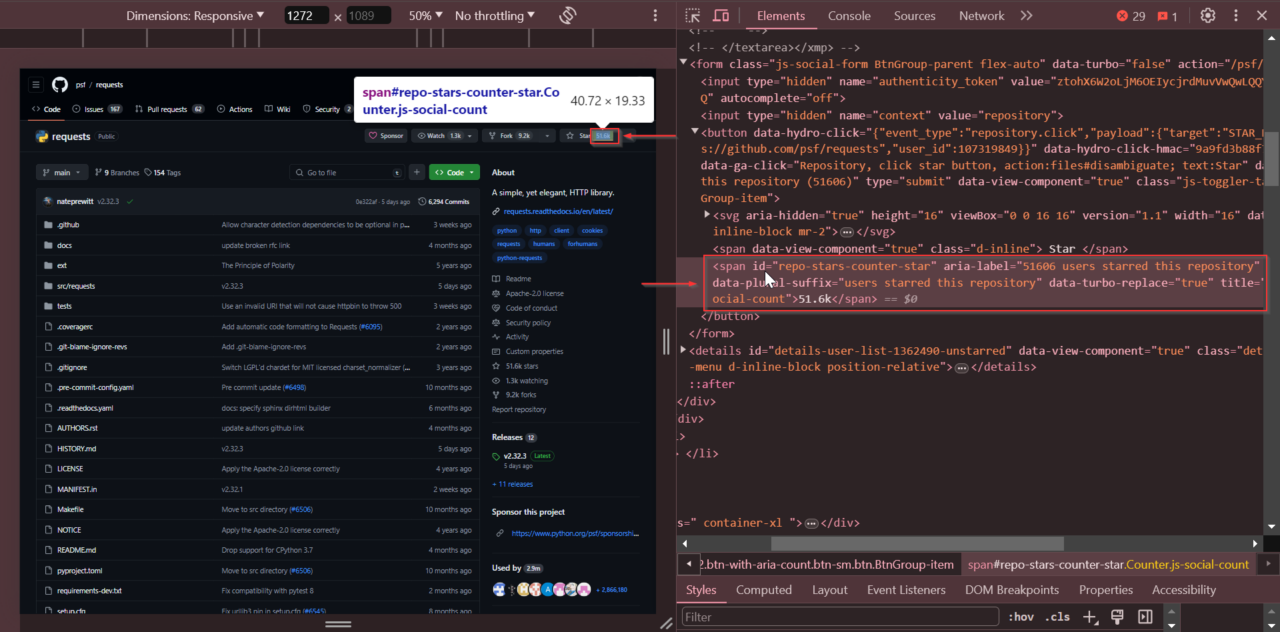
Selanjutnya kita mencari jumlah bintang. Temukan jumlah bintang di bagian atas halaman repositori. Klik kanan jumlah bintang dan pilih “Periksa.”
Jumlah bintang berada dalam satu Tandai dengan ID
repo-stars-counter-star.
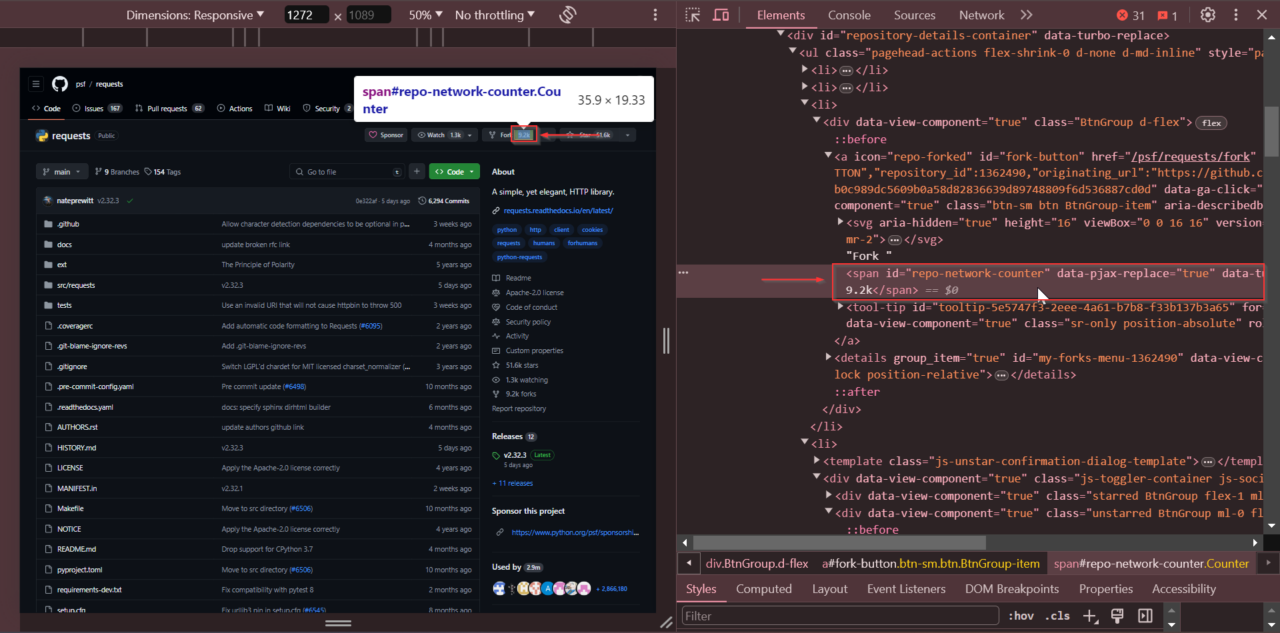
Juga, klik kanan pada jumlah garpu dan pilih “Periksa” untuk mendapatkan jumlah garpu. Jumlah garpu ada dalam satu Tandai dengan ID repo-network-counter.
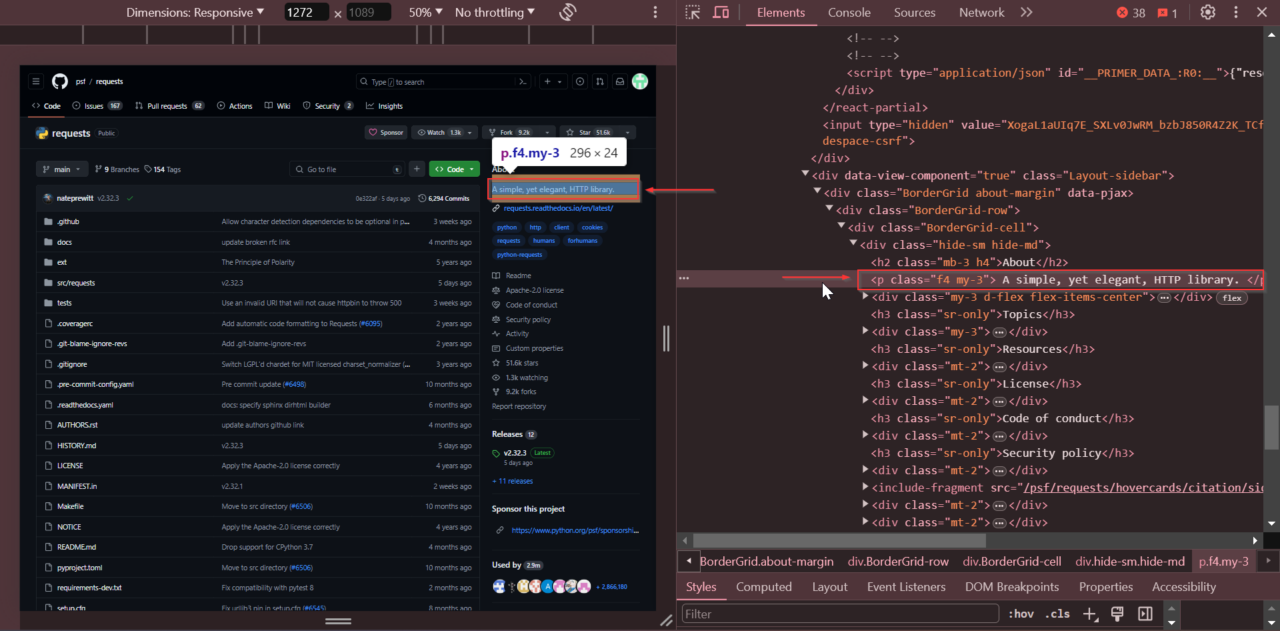
Selanjutnya kita mencari deskripsi repositori. Lihat di bagian Tentang di bagian atas halaman. Klik kanan dan pilih “Periksa.”
Deskripsi disimpan di a hari bersama kelas
f4 my-3.
Menggunakan DevTools untuk memeriksa elemen ini memungkinkan kita menentukan tag dan atribut yang tepat yang diperlukan untuk mengekstrak data yang kita inginkan.
Sekarang kita tahu di mana menemukan semuanya, kita bisa mengkodekan proses ekstraksi.
Langkah 6: Ekstrak data repositori GitHub
Sekarang kita sudah familiar dengan struktur HTML halaman repositori GitHub, mari kita ekstrak data yang relevan.
Kami menginisialisasi kamus untuk menyimpan data yang diambil, dan kemudian mengekstrak setiap informasi langkah demi langkah.
Pertama kita membuat kamus kosong bernama repo untuk menyimpan data yang diekstraksi.
Untuk mengekstrak nama repositori, kami mencari ini Tandai dengan atribut itemprop="name". Kami menggunakan sup.find() untuk menemukan tag dan kemudian mendapatkan konten teksnya get_text() dan menyimpannya di repo Kamus di bawah kunci name.
name_html_element = soup.find('strong', {"itemprop": "name"})
repo('name') = name_html_element.get_text().strip()
Selanjutnya, kita mengekstrak waktu commit terakhir dengan mencari
soup.find() Untuk menemukan tag ini, ekstrak tagnya datetime Atribut untuk mendapatkan stempel waktu yang tepat dan menyimpannya dalam kamus repo di bawah
latest_commit Kunci.
Itu find() Metode menemukan yang pertama
relative_time_html_element = soup.find('relative-time')
repo('latest_commit') = relative_time_html_element('datetime')
Selanjutnya kita menemukan Tandai dengan ID
repo-stars-counter-star untuk menentukan jumlah bintang. Kami juga menemukan itu Tandai dengan ID
repo-network-counter untuk penghitungan garpu.
Lalu kita gunakan soup.find() untuk menemukan setiap tag, lalu bawa konten teksnya bersama Anda get_text() dan menyimpannya di
repo Kamus di bawah tombol stars Dan
forksmasing-masing.
stars_element = soup.find('span', {"id": "repo-stars-counter-star"})
repo('stars') = stars_element.get_text().strip()
forks_element = soup.find('span', {"id": "repo-network-counter"})
repo('forks') = forks_element.get_text().strip()
Terakhir, kami mengekstrak deskripsi repositori dengan menggunakan
hari bersama kelas f4 my-3. Kita gunakan
soup.find() untuk menemukan tag, lalu ambil konten teksnya menggunakan
get_text() dan menyimpannya di repo Kamus.
description_html_element = soup.find('p', {"class": "f4 my-3"})
repo('description') = description_html_element.get_text().strip()
