
Jika Anda melihat variabel HTML, Anda akan melihat bahwa kali ini Anda mendapatkan halaman hasil pencarian lengkap seperti yang diminta.
Sementara kita melakukannya, mari kita muat juga responnya ke dalam objek BeautifulSoup:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html.text)
Manis! Sekarang setelah Anda memiliki jawaban lengkap di objek BeautifulSoup, Anda dapat mulai mengekstraksi data yang relevan dari objek tersebut.
Mengikis atribut produk
Cara termudah untuk mengetahui cara mengekstrak data yang Anda perlukan adalah dengan menggunakan alat pengembang yang tersedia di hampir semua browser utama.
Anda dapat menggunakan alat pengembang untuk menjelajahi struktur DOM halaman.
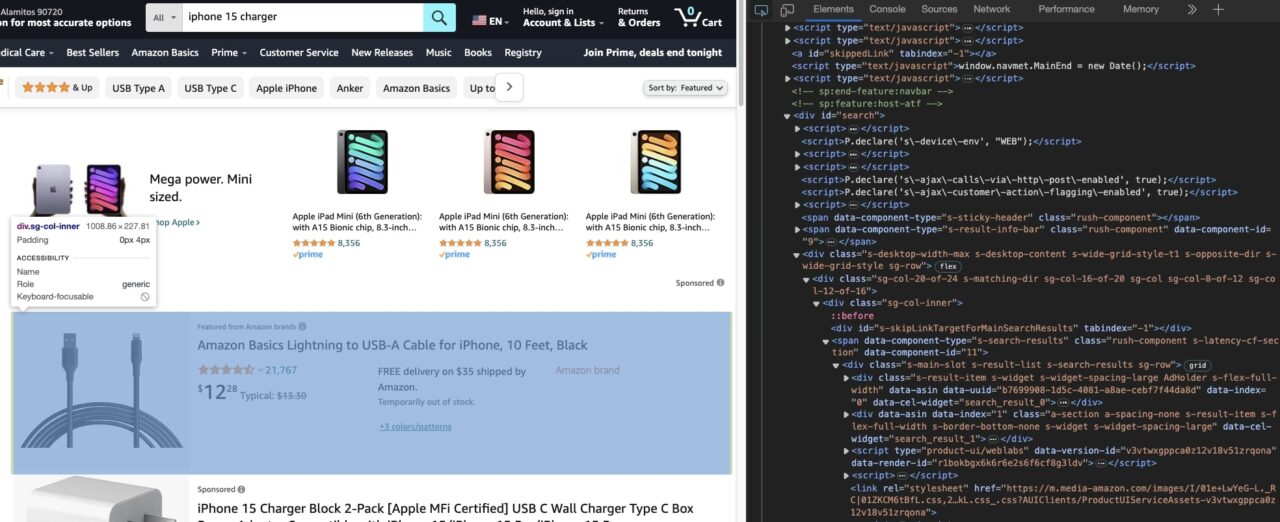
Tujuan utamanya adalah untuk mengetahui atribut tag HTML mana yang dapat Anda gunakan untuk menargetkan tag HTML secara unik.
Seringkali Anda akan mengandalkannya id Dan class Atribut. Kemudian Anda dapat meneruskan atribut ini ke BeautifulSoup dan memintanya mengembalikan teks/atribut yang ingin Anda ekstrak dari tag tertentu.
Mengekstrak nama produk
Mari kita lihat bagaimana Anda dapat mengekstrak nama produk. Ini akan memberi Anda pemahaman yang baik tentang proses umum.
Klik kanan nama produk dan klik Periksa:
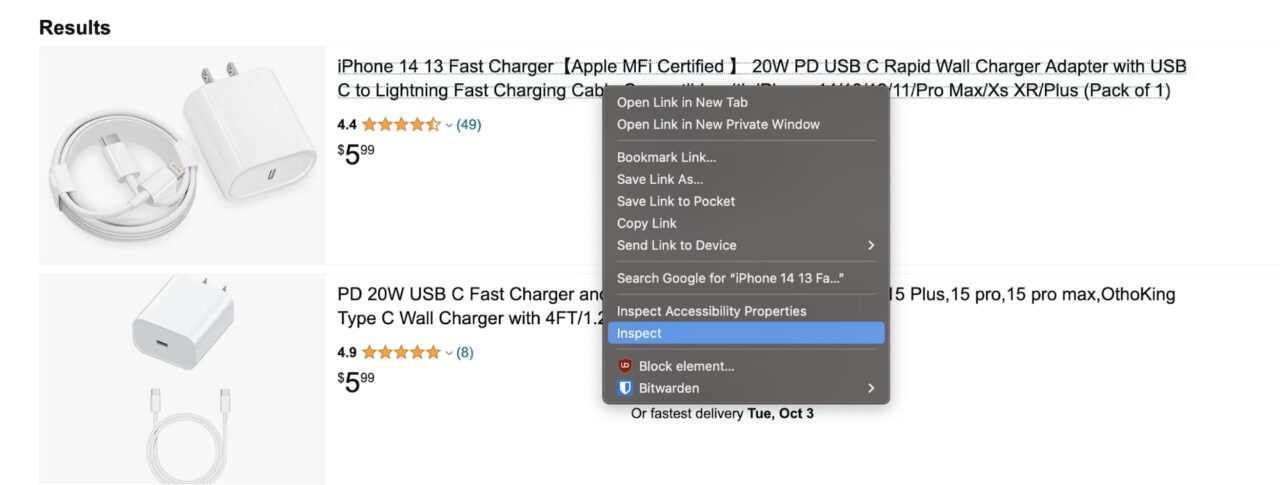
Ini akan membuka alat pengembang:
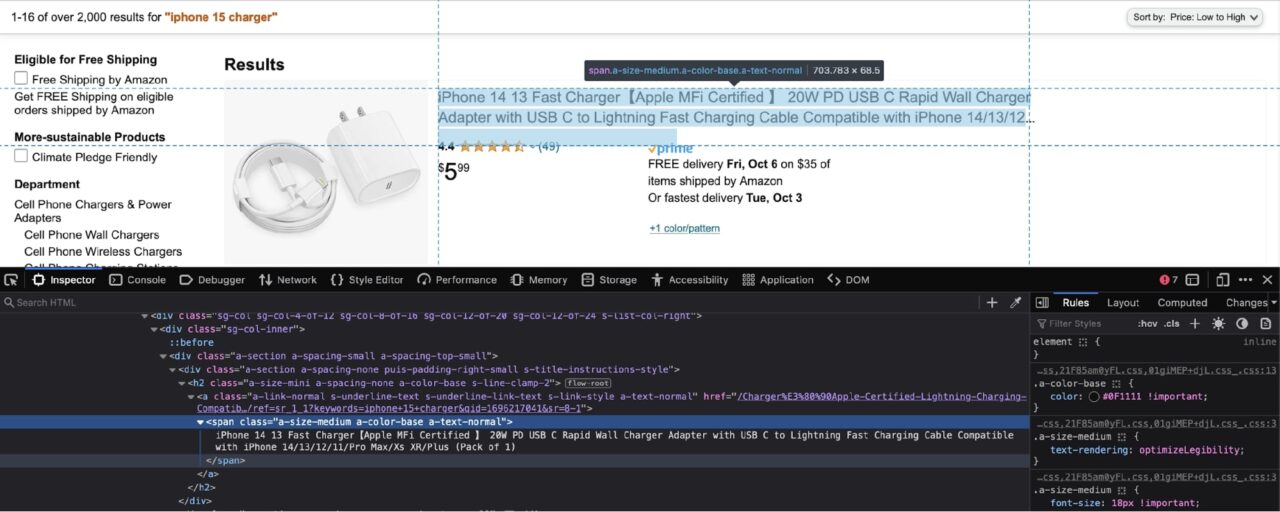
Seperti yang Anda lihat pada tangkapan layar di atas, nama produk disarangkan dalam rentang dengan kelas berikut: a-size-medium a-color-base a-text-normal.
Pada titik ini Anda harus membuat keputusan: Anda dapat meminta BeautifulSoup untuk mengekstrak semuanya spans dengan kelas-kelas ini dari halaman, atau Anda dapat mengekstrak hasil apa pun div dan kemudian melewatinya divs dan ekstrak data untuk setiap produk.
Secara umum, saya lebih memilih metode terakhir karena membantu mengidentifikasi produk yang mungkin tidak memiliki semua data yang diperlukan. Tutorial ini juga memperkenalkan metode yang sama.
Oleh karena itu, Anda sekarang perlu mengidentifikasi div yang membungkus setiap elemen hasil:
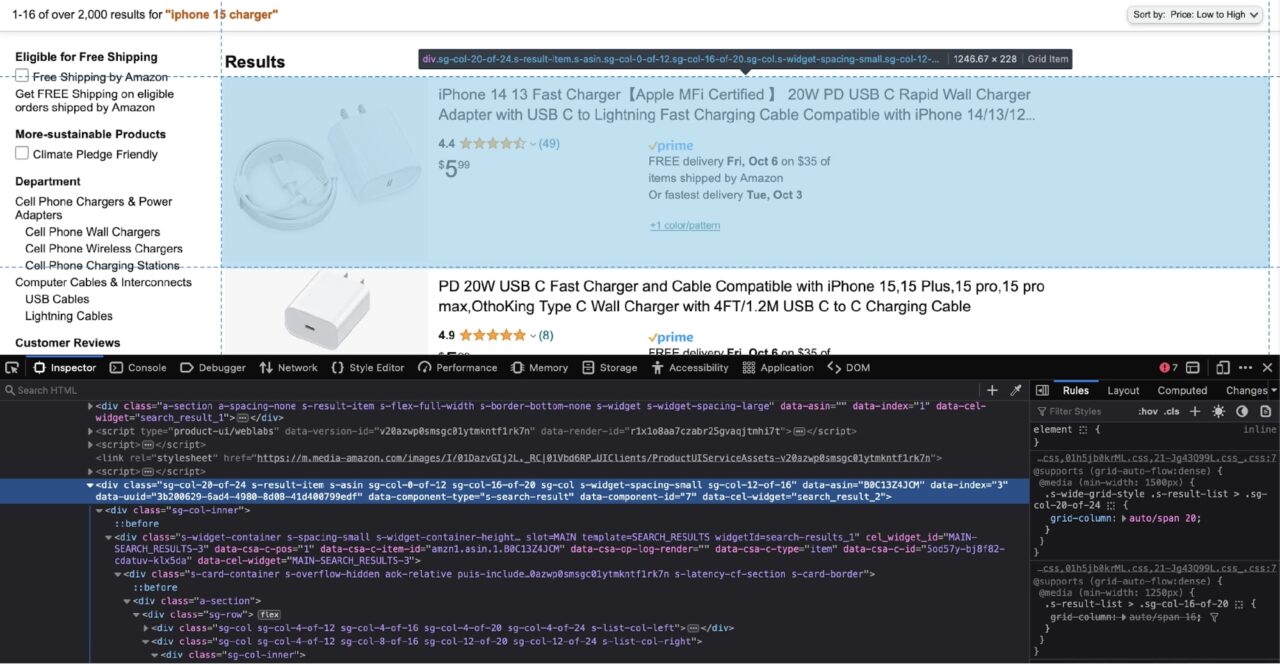
Menurut tangkapan layar di atas, setiap hasil disarangkan menjadi satu div hari dengan itu data-component-type Atribut dari s-search-result.
Mari gunakan informasi ini untuk mengekstrak seluruh hasil divs lalu ulangi dan ekstrak judul produk yang disarangkan:
results = soup.find_all('div', attrs={'data-component-type': 's-search-result'})
for r in results:
print(r.select_one('.a-size-medium.a-color-base.a-text-normal').text)
Berikut rincian sederhana tentang fungsi kode ini:
- Ini menggunakan
find_all()Metode dari BeautifulSoup - Ini mengembalikan semua elemen yang cocok dari HTML
- Ia kemudian menggunakan
select_one()Metode untuk mengekstrak elemen pertama yang cocok dengan pemilih CSS yang diteruskan
Mengamati bahwa kita menambahkan titik (.) sebelum setiap nama kelas. Ini memberitahu BeautifulSoup bahwa pemilih CSS yang diteruskan adalah nama kelas. Juga tidak ada spasi antar nama kelas. Hal ini penting karena menginformasikan BeautifulSoup bahwa setiap kelas berasal dari tag HTML yang sama.
Jika Anda baru mengenal penyeleksi CSS, pastikan untuk membaca lembar contekan penyeleksi CSS kami. Kami akan membahas dasar-dasar penyeleksi CSS dan memberi Anda kerangka kerja yang mudah digunakan untuk mempercepat prosesnya.
Mengekstraksi harga produk
Sekarang Anda telah mengekstrak nama produk, mengekstraksi harga produk cukup mudah.
Ikuti langkah yang sama dari bagian terakhir dan gunakan alat pengembang untuk memeriksa harga:
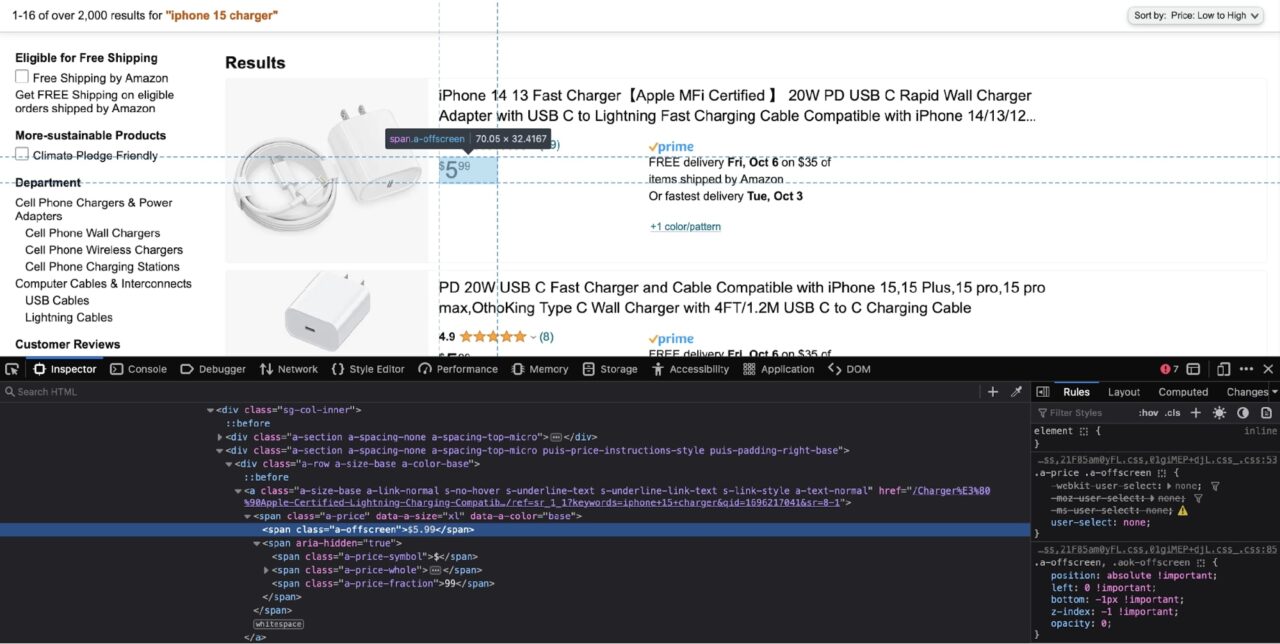
Harganya bisa diekstraksi dari kisaran dengan kelasnya a-offscreen. Itu span itu sendiri bersarang di dalam yang lain span dengan kelas a-price. Dengan pengetahuan ini, Anda dapat membuat pemilih CSS:
for r in results:
# -- truc --
print(r.select_one('.a-price .a-offscreen').text)
Karena Anda ingin menargetkan cakupan bersarang kali ini, Anda perlu menambahkan spasi di antara nama kelas.
Mengekstrak gambar produk
Coba ikuti langkah-langkah dari dua bagian sebelumnya untuk membuat sendiri kode yang relevan. Berikut adalah tangkapan layar dari gambar yang sedang diperiksa di jendela Alat Pengembang:

Itu img Tag memiliki kelas s-image. Anda dapat mengatasi hal ini secara spesifik img Sorot dan ekstrak src Atribut (URL gambar) dengan kode ini:
for r in results:
# -- truc --
print(r.select_one('.s-image').attrs('src'))
Catatan: Poin ekstra jika Anda melakukannya sendiri!
Kode pengikis lengkap
Anda memiliki semua bagian untuk menyusun kode pengikis yang lengkap.
Berikut adalah versi scraper yang sedikit dimodifikasi yang menempatkan semua hasil produk ke dalam daftar di bagian paling akhir:
import requests
from bs4 import BeautifulSoup
url = "https://www.amazon.com/s?k=iphone+15+charger&s=price-asc-rank"
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.157 Safari/537.36',
'Accept-Language': 'en-US, en;q=0.5'
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.text)
results = soup.find_all('div', attrs={'data-component-type': 's-search-result'})
result_list = ()
for r in results:
result_dict = {
"title": r.select_one('.a-size-medium.a-color-base.a-text-normal').text,
"price": r.select_one('.a-price .a-offscreen').text,
"image": r.select_one('.s-image').attrs('src')
}
result_list.append(result_dict)
Anda dapat dengan mudah menggunakan daftar hasil ini untuk berbagai API atau menyimpan informasi ini dalam spreadsheet untuk analisis lebih lanjut.
Menggunakan titik akhir data terstruktur
Tutorial ini tidak terlalu fokus pada kesulitan dalam menghapus Amazon dalam skala besar.
Amazon terkenal karena melarang scraper dan mempersulit pengikisan data dari situs webnya.
Anda sudah melihat ini di awal tutorial ketika permintaan tanpa header yang benar diblokir oleh Amazon.
Untungnya, ada solusi mudah untuk masalah ini. Daripada mengirim permintaan langsung ke Amazon, Anda dapat mengirim permintaan ke titik akhir data terstruktur ScraperAPI dan ScraperAPI akan merespons dengan data tergores dalam JSON yang diformat dengan baik.

Ini adalah fitur ScraperAPI yang sangat kuat karena Anda tidak perlu khawatir akan diblokir oleh Amazon atau selalu memperbarui scraper Anda dengan perubahan konstan Amazon dalam teknik anti-bot.
Bagian terbaiknya adalah ScraperAPI menyediakan 5.000 kredit API gratis selama 7 hari sebagai uji coba, dan kemudian memberikan paket gratis yang berlimpah dengan 1.000 kredit API berulang untuk membuat Anda terus maju. Ini cukup untuk mengekstrak data untuk penggunaan umum.
Anda dapat memulai dengan cepat dengan membuka halaman dasbor ScraperAPI dan mendaftar akun baru:
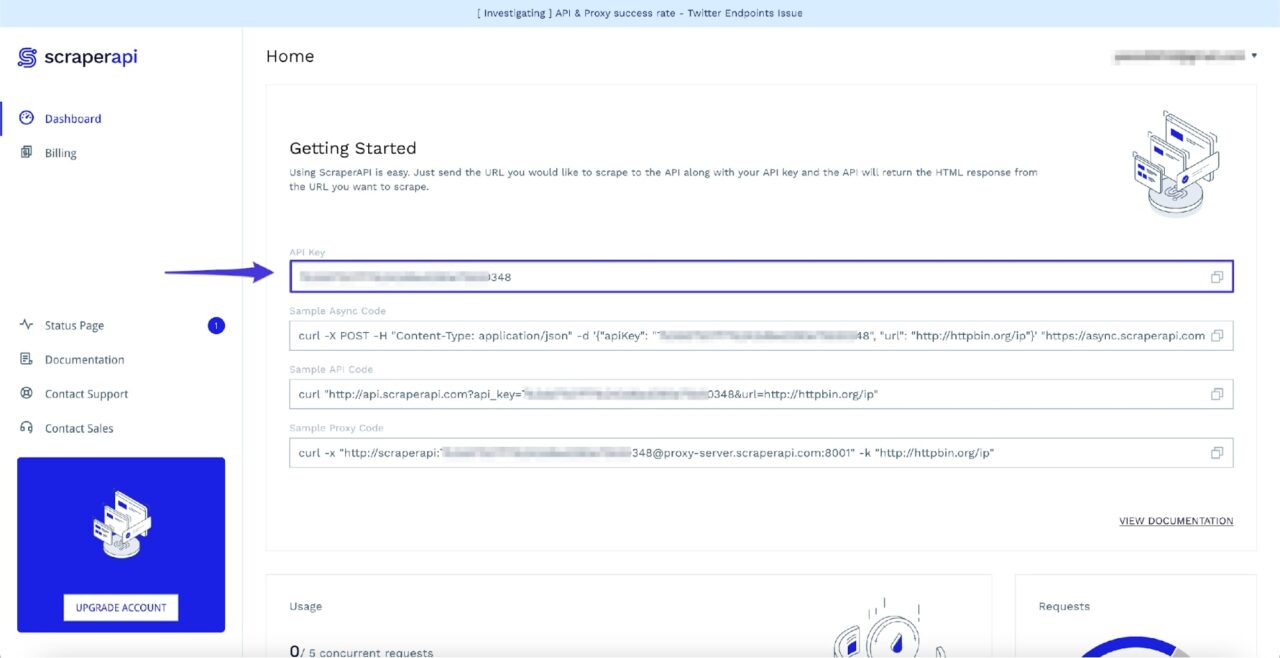
Setelah masuk, Anda akan melihat kunci API Anda:
Sekarang Anda dapat mengakses hasil pencarian Amazon melalui titik akhir Data Terstruktur menggunakan kode berikut:
import requests
payload = {
'api_key': 'API_KEY,
'query': 'iphone 15 charger',
's': 'price-asc-rank'
}
response = requests.get('https://api.scraperapi.com/structured/amazon/search', params=payload)
print(response.json())
Catatan: Jangan lupa untuk mengganti penggantinya API_KEY dalam kode di atas dengan kunci API ScraperAPI Anda sendiri.
Seperti yang mungkin sudah Anda ketahui, Anda dapat meneruskan sebagian besar parameter kueri yang diterima Amazon sebagai bagian dari payload. Ini berarti bahwa semua nilai pengurutan berikut ini valid untuk s Masukkan muatannya:
- Harga: Tinggi ke rendah =
price-desc-rank - Harga: Rendah ke tinggi =
price-asc-rank - Disorot =
rerelevanceblender - Rata-rata Ulasan pelanggan =
review-rank - Pendatang baru =
date-desc-rank
Jika Anda menginginkan hal yang sama result_list Untuk mengambil data dari bagian terakhir, Anda dapat menambahkan kode berikut di akhir:
result_list = ()
for r in response.json()('results'):
result_dict = {
"title": r('name')
"price": r('price_string'),
"image": r('image')
}
result_list.append(result_dict)
Untuk informasi selengkapnya tentang titik akhir ini, lihat dokumen ScraperAPI.
Ringkasan
Tutorial ini adalah ikhtisar singkat tentang cara mengikis data dari Amazon.
- Ini mengajarkan Anda metode solusi sederhana untuk sistem deteksi bot yang digunakan oleh Amazon.
- Ini menunjukkan kepada Anda bagaimana menggunakan berbagai metode yang disediakan oleh BeautifulSoup untuk mengekstrak data yang diperlukan dari dokumen HTML.
- Terakhir, Anda mempelajari tentang titik akhir data terstruktur yang ditawarkan oleh ScraperAPI dan cara memecahkan berbagai macam masalah.
Jika Anda siap memperluas pengumpulan data Anda dari beberapa halaman menjadi ribuan atau bahkan jutaan halaman, rencana bisnis kami adalah tempat yang tepat untuk memulai.
Apakah Anda memerlukan lebih dari 10 juta kredit API? Hubungi bagian penjualan untuk paket khusus yang mencakup semua fitur premium, dukungan premium, dan manajer akun.
Sampai jumpa lagi, selamat menggores!
