TL;DR: Pengikis Python Google Maps
Bagi yang sedang terburu-buru, berikut kode lengkap scraper yang akan kami buat pada artikel kali ini. Kode ini menggunakan Selenium dengan ScraperAPI dalam mode proxy untuk mengekstrak data bisnis dari hasil pencarian Google Maps:
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
import time
import csv
# Selenium Wire configuration to use a proxy
api_key = 'YOUR_SCRAPERAPI_KEY'
seleniumwire_options = {
'proxy': {
'http': f'http://scraperapi.render=true.country_code=us:{api_key}@proxy-server.scraperapi.com:8001',
'verify_ssl': False,
},
}
chrome_options = Options()
chrome_options.add_argument("--headless=new")
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options, seleniumwire_options=seleniumwire_options)
# URL of the web page
url = "https://www.google.com/maps/search/pizza+in+new+york"
# Open the web page
driver.get(url)
try:
button = driver.find_element(By.XPATH,'//*(@id="yDmH0d")/c-wiz/div/div/div/div(2)/div(1)/div(3)/div(1)/div(1)/form(2)/div/div/button/div(3)')
button.click()
print("Accepted cookies.")
except:
print("No cookies consent required.")
# Set an implicit wait time to wait for JavaScript to render
driver.implicitly_wait(30) # Wait for max 30 seconds
# Scrolls within a specific panel by simulating Page Down key presses.
def scroll_panel_down(driver, panel_xpath, presses, pause_time):
# Find the panel element
panel_element = driver.find_element(By.XPATH, panel_xpath)
# Ensure the panel is in focus by clicking on it
actions = ActionChains(driver)
actions.move_to_element(panel_element).click().perform()
# Send the Page Down key to the panel element
for _ in range(presses):
actions = ActionChains(driver)
actions.send_keys(Keys.PAGE_DOWN).perform()
time.sleep(pause_time)
panel_xpath = '//*(@id="QA0Szd")/div/div/div(1)/div(2)/div'
scroll_panel_down(driver, panel_xpath, presses=5, pause_time=1)
# Get the page HTML source
page_source = driver.page_source
# Parse the HTML using BeautifulSoup
soup = BeautifulSoup(page_source, "lxml")
# Find all elements using its class
titles = soup.find_all(class_="hfpxzc")
ratings = soup.find_all(class_='MW4etd')
reviews = soup.find_all(class_='UY7F9')
services = soup.find_all(class_='Ahnjwc')
# Print the number of places found
elements_count = len(titles)
print(f"Number of places found: {elements_count}")
# Specify the CSV file path
csv_file_path = 'maps_pizza_places.csv'
# Open a CSV file in write mode
with open(csv_file_path, 'w', newline='', encoding='utf-8') as csv_file:
# Create a CSV writer object
csv_writer = csv.writer(csv_file)
# Write the header row (optional, adjust according to your data)
csv_writer.writerow(('Place', 'Rating', 'Reviews', 'Service options'))
# Write the extracted data
for i, title in enumerate(titles):
title = title.get('aria-label')
rating = (ratings(i).text + "/5") if i
catatan: Pengganti 'YOUR_SCRAPERAPI_KEY' dengan kunci API unik Anda dari dasbor ScraperAPI Anda. Belum punya akun? Daftar hari ini dan dapatkan 5.000 kredit scraping gratis untuk mulai mengumpulkan data dalam hitungan menit!
Kode ini menghapus nama bisnis, ulasan, peringkat, dan opsi layanan untuk restoran pizza New York dari Google Maps dan menyimpan datanya ke file CSV.
Mengikis Google Maps dengan Python dan Selenium (Pendekatan Tanpa Kepala)
Salah satu cara mendapatkan data Google Maps adalah melalui API resmi, namun cara ini memiliki beberapa kekurangan. Mendapatkan kunci API itu rumit karena Anda perlu menyiapkan proyek Google Cloud. Keterbatasan mencakup batas akses data, batas kueri, dan potensi biaya yang terkait dengan penggunaan data yang tinggi.
Mengembangkan alat pengikis Google Maps Anda sendiri bisa menjadi tantangan besar jika Anda tidak memiliki pengalaman beberapa tahun. Anda harus bersiap menghadapi berbagai tantangan yang dihadirkan oleh Google, termasuk perlindungan IP (proxy), cookie dan sesi, emulasi browser, pembaruan situs web, dll.
Untungnya, ada beberapa alat pihak ketiga bagus yang bisa kita gunakan. Kami menggunakan Selenium untuk berinteraksi dengan Google Maps seperti pengguna sebenarnya. Sasaran kami adalah hasil Google Maps untuk restoran di New York yang menyajikan pizza. Untuk menangani pengelolaan proxy dan rendering JavaScript serta melewati mekanisme anti-scraping Google Maps, kami mengintegrasikan ScraperAPI ke dalam penyiapan kami.
Persyaratan
Untuk mengikuti tutorial ini, pastikan alat-alat berikut diinstal pada komputer Anda:
- ular piton: Unduh dan instal Python versi terbaru dari situs resminya.
- peramban Google Chrome.
- Perpustakaan: Instal perpustakaan Python yang diperlukan menggunakan pip:
pip install selenium selenium-wire webdriver-manager beautifulsoup4 lxml
Ini menginstal:
- Selenium: Digunakan untuk mengotomatiskan interaksi browser web dengan Python
- Selenium Wire: Ekstensi kuat untuk Python Selenium yang memberi Anda akses ke persyaratan dasar browser Selenium Anda. Berguna untuk integrasi proxy.
- Webdriver Manager: Menyederhanakan pengelolaan driver biner untuk berbagai browser.
- BeautifulSoup: Mem-parsing data HTML dan XML.
- LXML: Pustaka penguraian XML yang sering digunakan bersama dengan BeautifulSoup untuk meningkatkan kecepatan dan kinerja.
Anda juga memerlukan akun ScraperAPI. Jika Anda belum memilikinya, Anda dapat mendaftar di sini untuk menerima kunci API guna mengautentikasi permintaan Anda.
Ikhtisar tata letak Google Maps
Sebelum kita mulai melakukan scraping, kita perlu memahami di mana datanya berada dan dalam bentuk apa. Pada artikel ini kami akan mencoba mencari “Pizza di New York”.
Mengklik entri atau peta akan membawa Anda ke antarmuka utama Google Maps. Di sini Anda akan melihat bahwa semua hasil pencarian tercantum di panel kiri dan informasi peta yang lebih rinci ditampilkan di sebelah kanan.
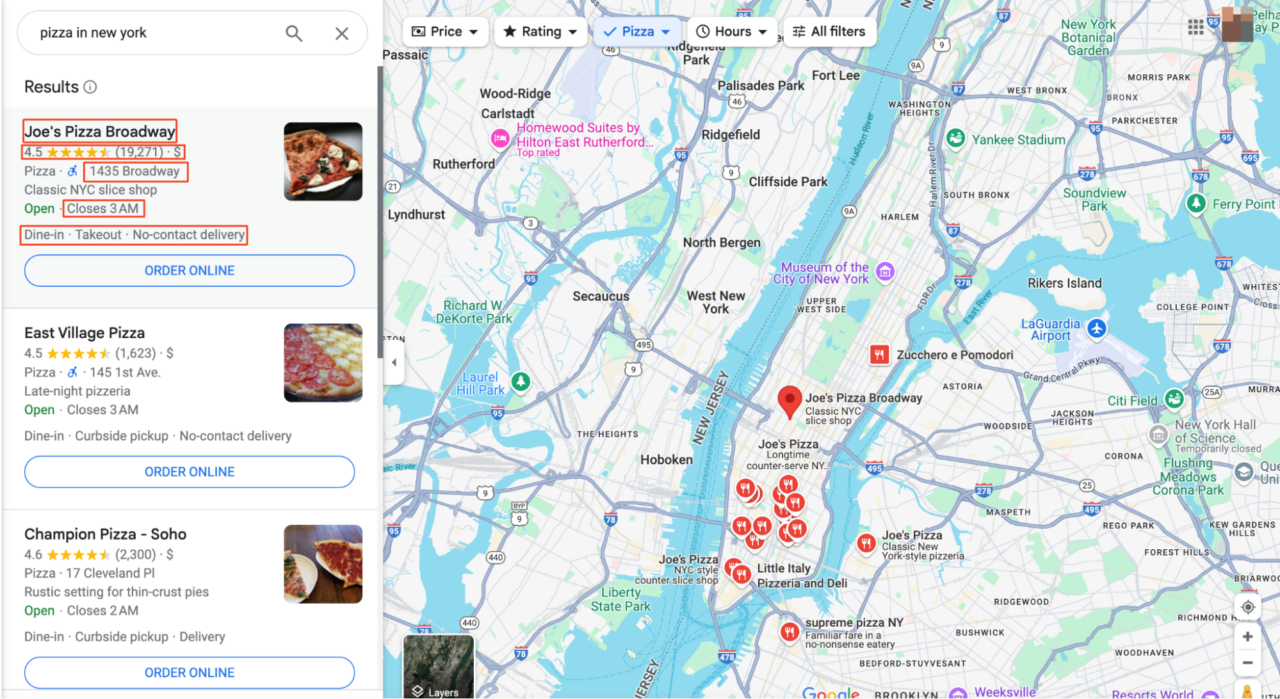
Untuk mengetahui bagian halaman mana yang berisi informasi yang kita perlukan, buka DevTools (F12atau klik kanan pada halaman dan pilih “Memeriksa"). DevTools memungkinkan Anda mengarahkan kursor ke berbagai bagian halaman web untuk melihat elemen HTML yang sesuai.
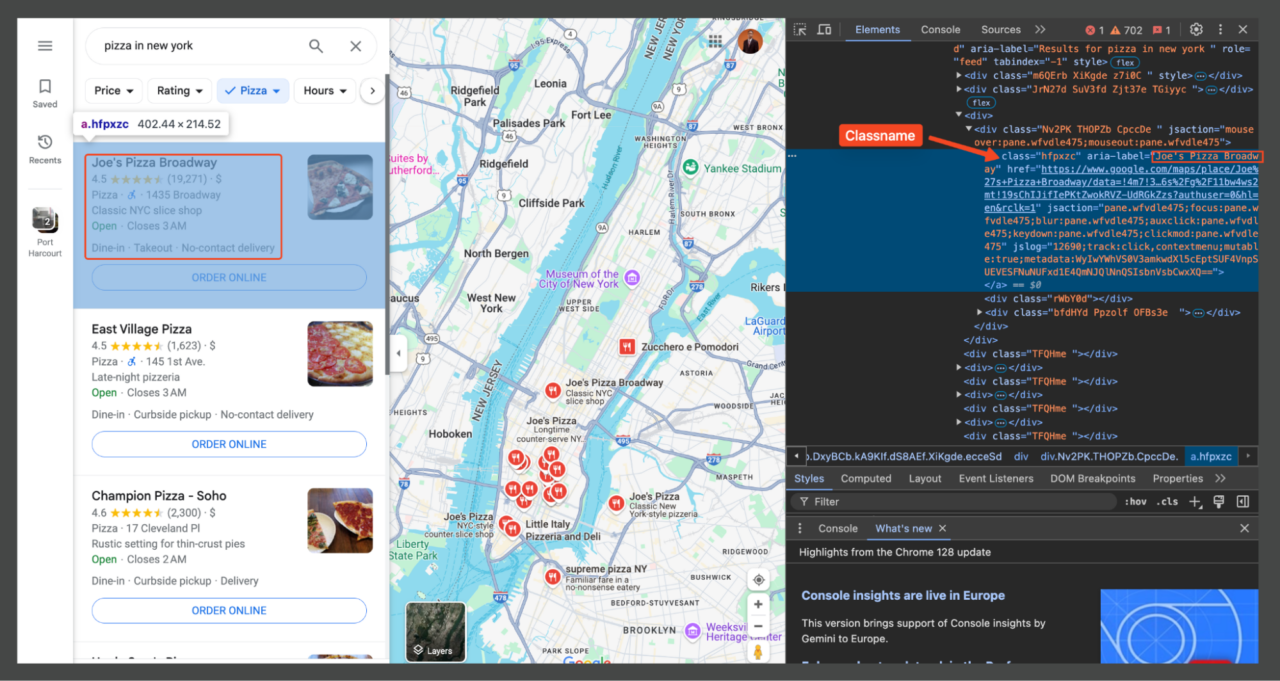
Setiap elemen pada halaman dapat ditargetkan menggunakan pemilih CSS. Misalnya, judul tempat (misalnya "Joe's Pizza") biasanya diapit oleh elemen dengan kelas tertentu (hfpxzc). Kami kemudian menggunakan Beautiful Soup untuk menemukan semua elemen kelas ini.
Selain itu, Google Maps tidak menggunakan penomoran halaman tradisional. Sebaliknya, lebih banyak hasil yang terus dimuat saat Anda menggulir daftar ke bawah. Sekarang setelah kita memahami tata letak ini dan penyeleksi yang relevan, sekarang kita dapat melanjutkan dengan menulis skrip pengikisan yang menargetkan elemen spesifik ini untuk mengekstrak informasi yang kita perlukan.
Langkah 1: Menyiapkan lingkungan Anda
Pertama, mari persiapkan lingkungan Python kita dengan perpustakaan yang diperlukan untuk web scraping Google Maps. Buka file proyek di editor kode Anda masing-masing dan impor perpustakaan yang diinstal di atas.
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
import time
import csv
Di sini kami menggunakan:
seleniumwirealih-alih Selenium biasa untuk memungkinkan integrasi proxy yang mudah- Itu
webdriver_managerPaket ini secara otomatis mengunduh versi ChromeDriver yang sesuai dan mengelolanya untuk kami - Itu
By,ActionChainsDanKeysImpor dari Selenium membantu kami berinteraksi dengan situs, misalnya. B. saat menggulir dan mengklik elemen - Akhirnya kita impor
timeuntuk menambahkan penundaan dancsvuntuk menyimpan data kami yang tergores.
Langkah 2: Konfigurasikan Selenium dan ScraperAPI
Selanjutnya, kami mengonfigurasi Selenium agar berfungsi dengan ScraperAPI, layanan pengikisan web canggih yang membantu kami melewati mekanisme anti-pengikisan ketat Google dengan merotasi proxy, memproses CAPTCHA, membuat header dan cookie yang sesuai, dan banyak lagi.
api_key = 'YOUR_SCRAPERAPI_KEY'
seleniumwire_options = {
'proxy': {
'http': f'http://scraperapi.render=true.country_code=us:{api_key}@proxy-server.scraperapi.com:8001',
'verify_ssl': False,
},
}
chrome_options = Options()
chrome_options.add_argument("--headless=new")
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options, seleniumwire_options=seleniumwire_options)
catatan: Buat akun ScraperAPI gratis dan ganti 'YOUR_SCRAPERAPI_KEY' dengan kunci API Anda.
Di sinilah kami membangun selenium-wire untuk menggunakan ScraperAPI sebagai proksi kami. Untuk menggunakan Selenium dengan ScraperAPI dengan benar, Anda harus menggunakan mode proksi kami seperti proksi lainnya. Itu username karena proxynya adalah scraperapi dan password adalah kunci API Anda.
Untuk mengaktifkan fungsionalitas tambahan saat menggunakan API dalam mode proksi, Anda dapat meneruskan parameter ke API dengan menambahkannya ke nama pengguna yang dipisahkan oleh titik. URL proksi berisi parameter seperti render=trueyang memastikan bahwa JavaScript dijalankan, dan country_code=us untuk menargetkan pertanyaan kami secara geografis ke Amerika Serikat.
Mode tanpa kepala memungkinkan skrip kami berjalan tanpa membuka jendela browser yang terlihat, meningkatkan kinerja dan mengurangi konsumsi sumber daya. Kami juga menggunakan ChromeDriverManager untuk mengelola instalasi dan pembaruan driver Chrome secara otomatis.
Bahasa Indonesia:sumber: Untuk informasi lebih lanjut, lihat dokumentasi port proxy kami.
Langkah 3: Akses Google Maps
Sekarang kita memberitahu browser kita untuk menavigasi ke halaman Google Maps untuk istilah pencarian yang kita inginkan, dalam contoh ini “pizza di New York”. Tindakan ini memuat halaman seolah-olah pengguna telah memasukkan permintaan pencarian secara manual ke dalam bilah pencarian Google.
url = "https://www.google.com/maps/search/pizza+in+new+york"
driver.get(url)
Langkah 4: Lewati pop-up cookie
Google Maps mungkin menampilkan pop-up persetujuan cookie ketika Selenium mencoba membuka tautan.
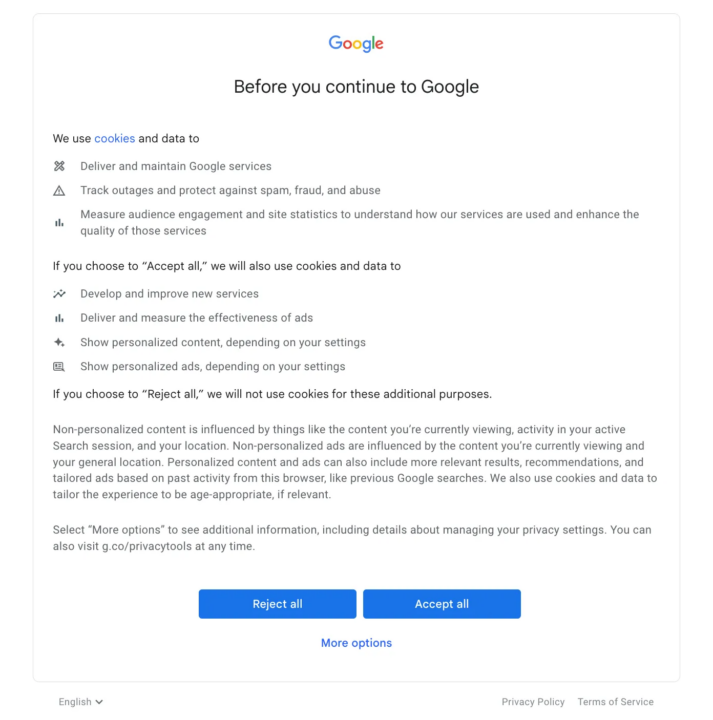
Untuk menyiasatinya, kita perlu menerima popup ini secara terprogram.
try:
button = driver.find_element(By.XPATH, '//*(@id="yDmH0d")/c-wiz/div/div/div/div(2)/div(1)/div(3)/div(1)/div(1)/form(2)/div/div/button/div(3)')
button.click()
print("Accepted cookies.")
except:
print("No cookies consent required.")
Kami akan mencoba untuk “Terima semuanyatombol ” di popup persetujuan cookie. Kami menggunakan blok coba-kecuali karena popup mungkin tidak selalu muncul. Di dalam blok coba driver.find_element(By.XPATH, '...') mencari elemen tombol menggunakan XPath-nya. Jika ditemukan, button.click() mensimulasikan klik pada tombol. Jika item tidak ditemukan (yang berarti popup tidak ada), blok pengecualian dijalankan dan pesan dicetak ke konsol.
Catatan: Menggunakan ScraperAPI akan mencegah munculnya tantangan CAPTCHA. Namun, disarankan untuk merencanakan hal ini untuk berjaga-jaga.
Langkah 5: Gulir dan muat lebih banyak hasil
Google Maps secara dinamis memuat lebih banyak hasil saat Anda menggulir halaman ke bawah. Kami menyimulasikan perilaku pengguliran ini untuk memuat lebih banyak data.
def scroll_panel_down(driver, panel_xpath, presses, pause_time):
panel_element = driver.find_element(By.XPATH, panel_xpath)
actions = ActionChains(driver)
actions.move_to_element(panel_element).click().perform()
for _ in range(presses):
actions = ActionChains(driver)
actions.send_keys(Keys.PAGE_DOWN).perform()
time.sleep(pause_time)
panel_xpath = '//*(@id="QA0Szd")/div/div/div(1)/div(2)/div'
scroll_panel_down(driver, panel_xpath, presses=5, pause_time=1)
Di Sini, panel_xpath mengidentifikasi area yang berisi hasil pencarian. Itu scroll_panel_down() Fungsi ini didefinisikan untuk mengirimkan serangkaian penekanan tombol halaman ke bawah ke panel ini, memaksanya memuat hasil tambahan. Parameternya presses=5 Dan pause_time=1 Tentukan berapa kali tombol harus ditekan dan berapa lama waktu tunggu di antara setiap penekanan. Metode ini memastikan bahwa kita dapat mengakses semua data yang tersedia dengan mensimulasikan tindakan pengguliran pengguna.
Langkah 6: Analisis data dengan BeautifulSoup
Setelah hasilnya dimuat, langkah selanjutnya adalah mengurai HTML dan mengekstrak informasi relevan seperti nama perusahaan, peringkat, ulasan, dan opsi layanan menggunakan BeautifulSoup.
page_source = driver.page_source
soup = BeautifulSoup(page_source, "lxml")
titles = soup.find_all(class_="hfpxzc")
ratings = soup.find_all(class_='MW4etd')
reviews = soup.find_all(class_='UY7F9')
services = soup.find_all(class_='Ahnjwc')
Kami pertama-tama mendapatkan seluruh sumber halaman driver.page_source. Ini akan memberi kita konten HTML halaman tersebut setelah semua interaksi kita (scrolling, dll.) selesai. Kami kemudian membuat objek BeautifulSoup, meneruskan sumber halaman dan mengetik “lxml” untuk menganalisis konten.
Selanjutnya kita menggunakan BeautifulSoup's find_all Metode untuk mencari semua elemen dengan nama kelas tertentu yang sesuai dengan data yang ingin kita ekstrak.
Langkah 7: Simpan data ke file CSV
Terakhir, kami menyimpan data yang diekstraksi ke dalam file CSV menggunakan kemampuan pemrosesan file Python.
csv_file_path = 'pizza_maps_places.csv'
with open(csv_file_path, 'w', newline='', encoding='utf-8') as csv_file:
csv_writer = csv.writer(csv_file)
csv_writer.writerow(('Place', 'Rating', 'Reviews', 'Service options'))
for i, title in enumerate(titles):
title = title.get('aria-label')
rating = (ratings(i).text + "/5") if i
Fase ini biasanya melibatkan penyimpanan data dan melakukan pembersihan data. Hal ini dapat mencakup, misalnya, menghapus karakter yang tidak diperlukan, memperbaiki kesalahan data, atau menghilangkan string kosong.
- Kami membuka file bernama '
pizza_maps_places.csv' dalam mode tulis untuk memastikan kami menggunakannyautf-8Pengkodean untuk memproses karakter khusus. - Lalu kami mengulang data yang kami ambil. Untuk setiap restoran, kami mengekstrak judul dari “
aria-label' Atribut elemen judul. - Kami menerima teks ulasan dan menggantung “
/5” atau gunakan 'N/A' jika tidak ditemukan peringkat. - Demikian pula, kami mengekstrak jumlah ulasan dan opsi layanan dengan menggunakan “
N/A' sebagai pengganti jika datanya hilang. - Kami kemudian menulis data setiap restoran sebagai baris ke file CSV kami.
- Setelah perulangan, kami mencetak pesan konfirmasi dengan jalur file.
- Akhirnya kami menelepon
driver.quit()untuk menutup browser dan mengakhiri sesi Selenium, mengosongkan sumber daya sistem.
Lengkapi Google Maps Scraper dengan Selenium
Berikut skrip lengkap kami untuk menelusuri Google Maps untuk menemukan tempat pizza di New York.
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
import time
import csv
# Selenium Wire configuration to use a proxy
api_key = 'YOUR_SCRAPERAPI_KEY'
seleniumwire_options = {
'proxy': {
'http': f'http://scraperapi.render=true.country_code=us:{api_key}@proxy-server.scraperapi.com:8001',
'verify_ssl': False,
},
}
chrome_options = Options()
chrome_options.add_argument("--headless=new")
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options, seleniumwire_options=seleniumwire_options)
# URL of the web page
url = "https://www.google.com/maps/search/pizza+in+new+york"
# Open the web page
driver.get(url)
try:
button = driver.find_element(By.XPATH,'//*(@id="yDmH0d")/c-wiz/div/div/div/div(2)/div(1)/div(3)/div(1)/div(1)/form(2)/div/div/button/div(3)')
button.click()
print("Accepted cookies.")
except:
print("No cookies consent required.")
# Set an implicit wait time to wait for JavaScript to render
driver.implicitly_wait(30) # Wait for max 30 seconds
# Scrolls within a specific panel by simulating Page Down key presses.
def scroll_panel_down(driver, panel_xpath, presses, pause_time):
# Find the panel element
panel_element = driver.find_element(By.XPATH, panel_xpath)
# Ensure the panel is in focus by clicking on it
actions = ActionChains(driver)
actions.move_to_element(panel_element).click().perform()
# Send the Page Down key to the panel element
for _ in range(presses):
actions = ActionChains(driver)
actions.send_keys(Keys.PAGE_DOWN).perform()
time.sleep(pause_time)
panel_xpath = '//*(@id="QA0Szd")/div/div/div(1)/div(2)/div'
scroll_panel_down(driver, panel_xpath, presses=5, pause_time=1)
# Get the page HTML source
page_source = driver.page_source
# Parse the HTML using BeautifulSoup
soup = BeautifulSoup(page_source, "lxml")
# Find all elements using its class
titles = soup.find_all(class_="hfpxzc")
ratings = soup.find_all(class_='MW4etd')
reviews = soup.find_all(class_='UY7F9')
services = soup.find_all(class_='Ahnjwc')
# Print the number of places found
elements_count = len(titles)
print(f"Number of places found: {elements_count}")
# Specify the CSV file path
csv_file_path = 'maps_pizza_places.csv'
# Open a CSV file in write mode
with open(csv_file_path, 'w', newline='', encoding='utf-8') as csv_file:
# Create a CSV writer object
csv_writer = csv.writer(csv_file)
# Write the header row (optional, adjust according to your data)
csv_writer.writerow(('Place', 'Rating', 'Reviews', 'Service options'))
# Write the extracted data
for i, title in enumerate(titles):
title = title.get('aria-label')
rating = (ratings(i).text + "/5") if i
Setelah Anda menjalankan skrip ini, terminal akan menunjukkan kepada Anda apakah terminal harus menerima cookie, berapa banyak lokasi yang diekstraksi, dan di mana file CSV dengan semua informasi yang diekstraksi disimpan.
Apakah Anda ingin melakukan ini dengan Javascript? Lihat panduan komprehensif kami untuk membuat scraper Google Maps (dalam Javascript).
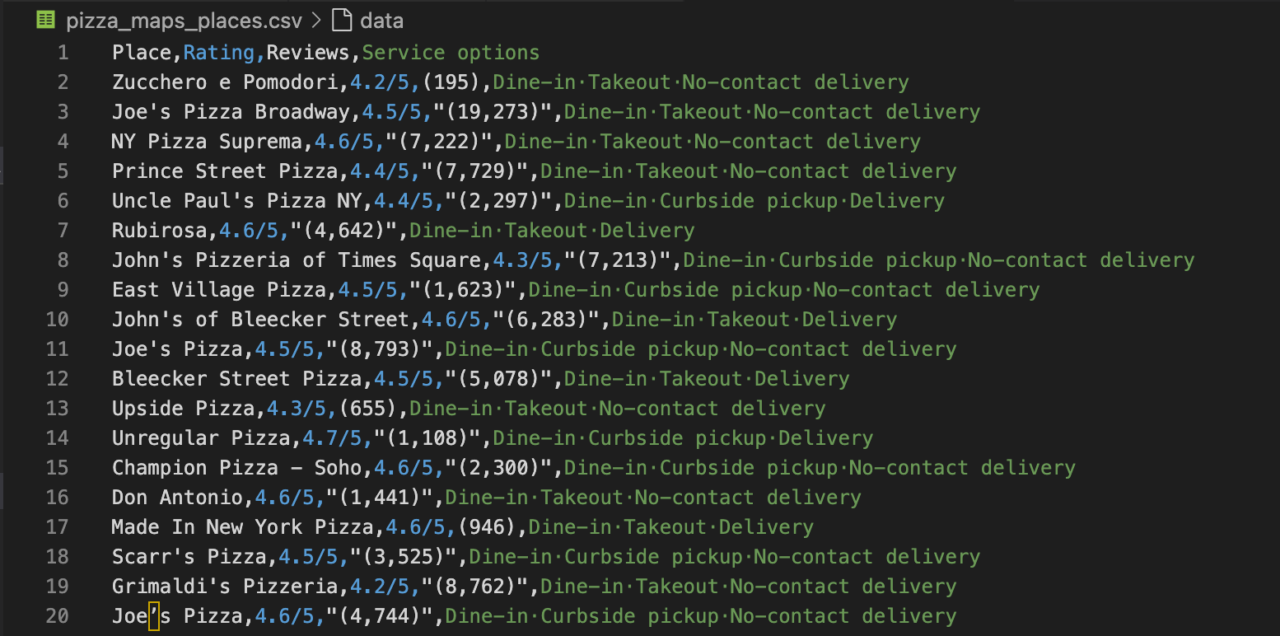
Mengikis Google Maps menggunakan instruksi rendering ScraperAPI (pendekatan API)
Di bagian sebelumnya, kami menggunakan Selenium untuk mengekstrak data dari Google Maps. Meskipun metode ini efektif, metode ini memerlukan penanganan otomatisasi browser secara langsung, yang mungkin rumit dan membutuhkan banyak sumber daya.
ScraperAPI menawarkan pendekatan yang lebih sederhana dengan menggunakan kumpulan perintah renderingnya. Hal ini memungkinkan kami melakukan tugas otomatisasi serupa seperti menggulir halaman pemuatan tanpa akhir atau mengklik tombol dengan lebih sedikit kode dan tenaga.
Cara menggunakan instruksi rendering ScraperAPI
Set Instruksi Render memungkinkan Anda mengirim instruksi ke browser tanpa kepala melalui ScraperAPI, yang menginstruksikan tindakan apa yang harus diambil saat merender halaman. Instruksi ini dikirim sebagai objek JSON di header permintaan API.
Jadi kita bisa menggunakan ScraperAPI untuk mencari restoran pizza di Google Maps di New York, mereplikasi apa yang kita capai dengan Selenium tetapi dengan cara yang lebih efisien
import requests
from bs4 import BeautifulSoup
import csv
api_key = 'YOUR_SCRAPERAPI_KEY'
url = 'https://api.scraperapi.com/'
# Define the target Google Maps URL
target_url = 'https://www.google.com/maps/search/pizza+in+new+york'
# div.VfPpkd-RLmnJb
# Construct the instruction set for Scraper API
headers = {
'x-sapi-api_key': api_key,
'x-sapi-render': 'true',
'x-sapi-instruction_set': '({"type": "loop", "for": 5, "instructions": ({"type": "scroll", "direction": "y", "value": "bottom" }, {"type": "click", "selector": {"type": "css", "value": "div.VfPpkd-RLmnJb"}}, { "type": "wait", "value": 5 }) })'
}
payload = {'url': target_url, 'country_code': 'us'}
response = requests.get(url, params=payload, headers=headers)
soup = BeautifulSoup(response.text, "lxml")
# Find all listing elements using the class "Nv2PK"
listings = soup.find_all("div", class_="Nv2PK")
# Print the number of places found
elements_count = len(listings)
print(f"Number of places found: {elements_count}")
# Specify the CSV file path
csv_file_path = 'render_map_results.csv'
# Open a CSV file in write mode
with open(csv_file_path, 'w', newline='', encoding='utf-8') as csv_file:
# Create a CSV writer object
csv_writer = csv.writer(csv_file)
# Write the header row (optional, adjust according to your data)
csv_writer.writerow(('Place', 'Rating', 'Reviews', 'Service options'))
# Iterate through each listing and extract information
for listing in listings:
title_tag = listing.find("a", class_="hfpxzc")
rating_tag = listing.find("span", class_="MW4etd")
review_tag = listing.find("span", class_="UY7F9")
service_tags = listing.find_all("div", class_="Ahnjwc")
title = title_tag.get('aria-label') if title_tag else 'N/A'
rating = rating_tag.text if rating_tag else 'N/A'
reviews = review_tag.text if review_tag else 'N/A'
service_options = ', '.join((service.text for service in service_tags)) if service_tags else 'N/A'
# Write a row to the CSV file
csv_writer.writerow((title, rating, reviews, service_options))
print(f"Data has been saved to '{csv_file_path}'")
Catatan: Untuk informasi selengkapnya tentang penggunaan kumpulan perintah render dan contoh tambahan, lihat dokumentasi ScraperAPI.
Bagian terpenting dari pengaturan ini adalah kamus header, yang meliputi:
- Itu
x-sapi-api_keyuntuk otentikasi dengan ScraperAPI x-sapi-renderdisetel ke true untuk mengaktifkan rendering JavaScript, danx-sapi-instruction_setyang berisi instruksi untuk browser.
Di set perintah kami, kami mengklik semua elemen yang cocok dengan pemilih div.VfPpkd-RLmnJb jika itu ada. Kami melakukan ini untuk melewati popup cookie. Kami kemudian menggulir halaman lima kali dalam satu putaran dan menunggu lima detik di antara setiap tindakan. Pendekatan ini secara efektif memuat lebih banyak hasil secara dinamis, serupa dengan perilaku pengguliran.
Kesimpulan: Apa yang dapat Anda lakukan dengan data Google Maps?
Artikel ini memandu Anda mengumpulkan data dari Google Maps dan menunjukkan cara mengumpulkan informasi berharga seperti nama bisnis, peringkat, ulasan, dan opsi layanan. Berikut adalah beberapa kemungkinan penggunaan data yang baru Anda kumpulkan:
- Riset pasar
- Analisis pesaing
- Analisis sentimen pelanggan
- Optimalisasi layanan berbasis lokasi
- Deteksi tren
Apakah Anda lelah terus-menerus diblokir oleh Google? Coba ScraperAPI secara gratis dan nikmati pengikisan yang mudah dan terukur dalam hitungan menit!
Untuk informasi selengkapnya, lihat sumber daya berikut:
