
Jika Anda mengerjakan proyek pengikisan web yang besar (misalnya, pengikisan informasi produk), Anda mungkin menemukan halaman yang diberi nomor halaman. Merupakan praktik umum bagi e-niaga dan situs web konten untuk membagi konten menjadi beberapa halaman guna meningkatkan pengalaman pengguna. Namun, penomoran halaman web scraping membuat pekerjaan kita sedikit lebih rumit.
Pada artikel ini Anda akan mempelajari cara membuat web scraper pagination hanya dalam beberapa menit dan tanpa diblokir oleh teknik anti-scraping.
Meskipun Anda dapat mengikuti tutorial ini tanpa pengetahuan sebelumnya, mungkin ada baiknya Anda membaca terlebih dahulu panduan Scrapy untuk pemula kami untuk penjelasan lebih mendalam tentang kerangka kerja tersebut sebelum Anda memulai.
Tanpa basa-basi lagi, mari kita mulai!
Menggores situs web dengan pagination menggunakan Python Scrapy
Untuk tutorial ini, kita akan mencari kategori Topi Pria SnowAndRock untuk mengekstrak semua nama produk, harga, dan tautan.
Sedikit penafian: Kami menulis artikel ini menggunakan Mac, jadi Anda perlu sedikit menyesuaikannya agar dapat berfungsi di PC. Kalau tidak, semuanya akan sama.
TLDR: Berikut cuplikan singkat tentang cara menangani pagination di Scrapy menggunakan tombol Berikutnya.:
next_page = response.css('a(rel=next)').attrib('href')
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
Baca terus untuk penjelasan mendetail tentang cara menerapkan kode ini dalam skrip Anda dan cara menangani halaman tanpa tombol “Lanjutkan”.
1. Siapkan lingkungan pengembangan Anda
Sebelum kita mulai menulis kode, kita perlu menyiapkan lingkungan kita agar berfungsi dengan Scrapy, pustaka Python yang dirancang untuk web scraping. Ini memungkinkan kami merayapi dan mengekstrak data dari situs web, mengurai data mentah ke dalam format terstruktur, dan memilih elemen menggunakan pemilih CSS dan/atau XPath.
Pertama, mari buat direktori baru (kita sebut saja pagination scraper) dan buat lingkungan virtual Python di dalamnya menggunakan perintah python -m venv venv. Dimana venv kedua adalah nama lingkungan Anda - tetapi Anda dapat menyebutnya apapun yang Anda inginkan.
Untuk mengaktifkannya cukup ketik source venv/bin/activate. Prompt Anda akan terlihat seperti ini:
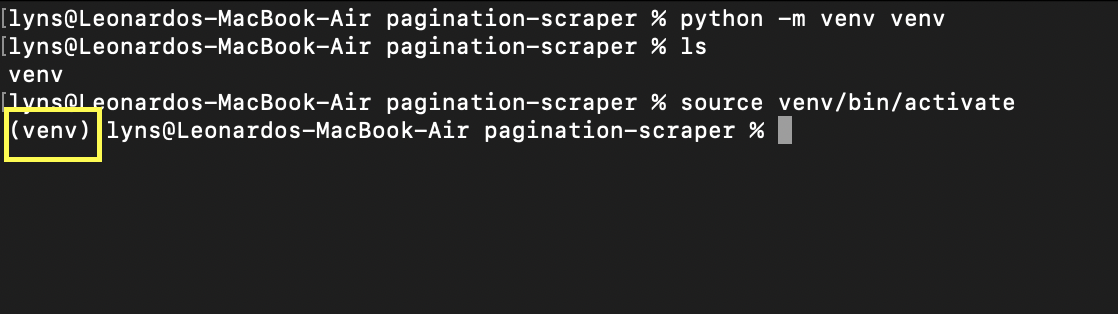
Sekarang menginstal Scrapy semudah mengetik pip3 install scrapy - mungkin diperlukan beberapa detik untuk mengunduh dan menginstal.
Setelah selesai, kita mengetik cd venv dan membuat proyek scrapy baru: scrapy startproject scrapypagination.
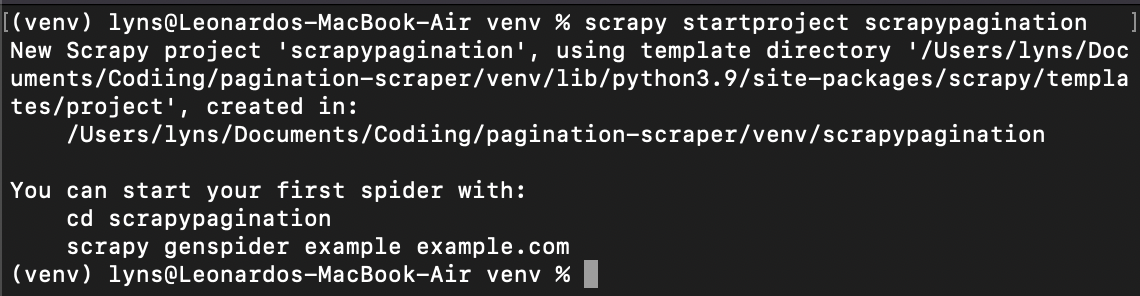
Sekarang Anda dapat melihat bahwa Scrapy telah memulai proyek kami dengan menginstal semua file yang diperlukan.
2. Siapkan ScraperAPI untuk menghindari larangan
Bagian tersulit dalam menangani halaman yang diberi nomor halaman bukanlah menulis skrip itu sendiri, melainkan tidak membiarkan server memblokir bot kita.
Untuk melakukan ini kita perlu membuat fungsi (atau serangkaian fungsi) yang merotasi alamat IP kita setelah beberapa kali mencoba (yang berarti kita juga memerlukan akses ke kumpulan alamat IP). Beberapa situs web juga menggunakan teknik tingkat lanjut seperti CAPTCHA dan profil perilaku browser.
Untuk menghemat waktu dan kerumitan, kami menggunakan ScraperAPI, API yang memanfaatkan pembelajaran mesin, kumpulan browser besar-besaran, proxy pihak ketiga, dan analisis statistik selama bertahun-tahun untuk secara otomatis menangani mekanisme anti-bot apa pun yang mungkin ditemui skrip kami.
Yang terbaik dari semuanya, menyiapkan ScraperAPI di proyek kami mudah dilakukan dengan Scrapy:
import scrapy
from urllib.parse import urlencode
API_KEY = '51e43be283e4db2a5afb62660xxxxxxx'
def get_scraperapi_url(url):
payload = {'api_key': API_KEY, 'url': url}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
Seperti yang Anda lihat, kami mendefinisikan metode get_scraperapi_url() untuk membantu kami membuat URL tujuan pengiriman permintaan. Pertama, kami menambahkan dependensi kami di atas dan kemudian menambahkan variabel API_KEY yang berisi kunci API kami - untuk mendapatkan kunci Anda, cukup mendaftar untuk mendapatkan akun ScraperAPI gratis dan Anda akan menemukannya di dasbor Anda.
Metode ini membuat URL untuk permintaan setiap URL yang ditemukan oleh scraper kami, dan itulah sebabnya kami menyiapkannya dengan cara ini, bukan cara yang lebih langsung yang hanya menempelkan semua parameter langsung ke URL seperti ini:
start_urls = ('http://api.scraperapi.com?api_key={yourApiKey}&url={URL}')
3. Memahami struktur URL website
Struktur URL cukup unik untuk setiap situs web. Pengembang cenderung menggunakan struktur yang berbeda untuk membuat navigasi lebih mudah bagi mereka dan dalam beberapa kasus untuk mengoptimalkan pengalaman navigasi untuk crawler mesin pencari seperti Google dan pengguna sebenarnya.
Untuk mengekstrak konten yang diberi halaman, kita perlu memahami cara kerjanya dan membuat rencana yang sesuai. Tidak ada cara yang lebih baik untuk melakukan ini selain memeriksa halaman dan melihat bagaimana URL itu sendiri berubah dari satu halaman ke halaman berikutnya.
Jadi jika kita membuka https://www.snowandrock.com/c/mens/accessories/hats.html dan menggulir ke produk terakhir yang terdaftar, kita dapat melihat bahwa produk tersebut menggunakan penomoran halaman dan tombol berikutnya.
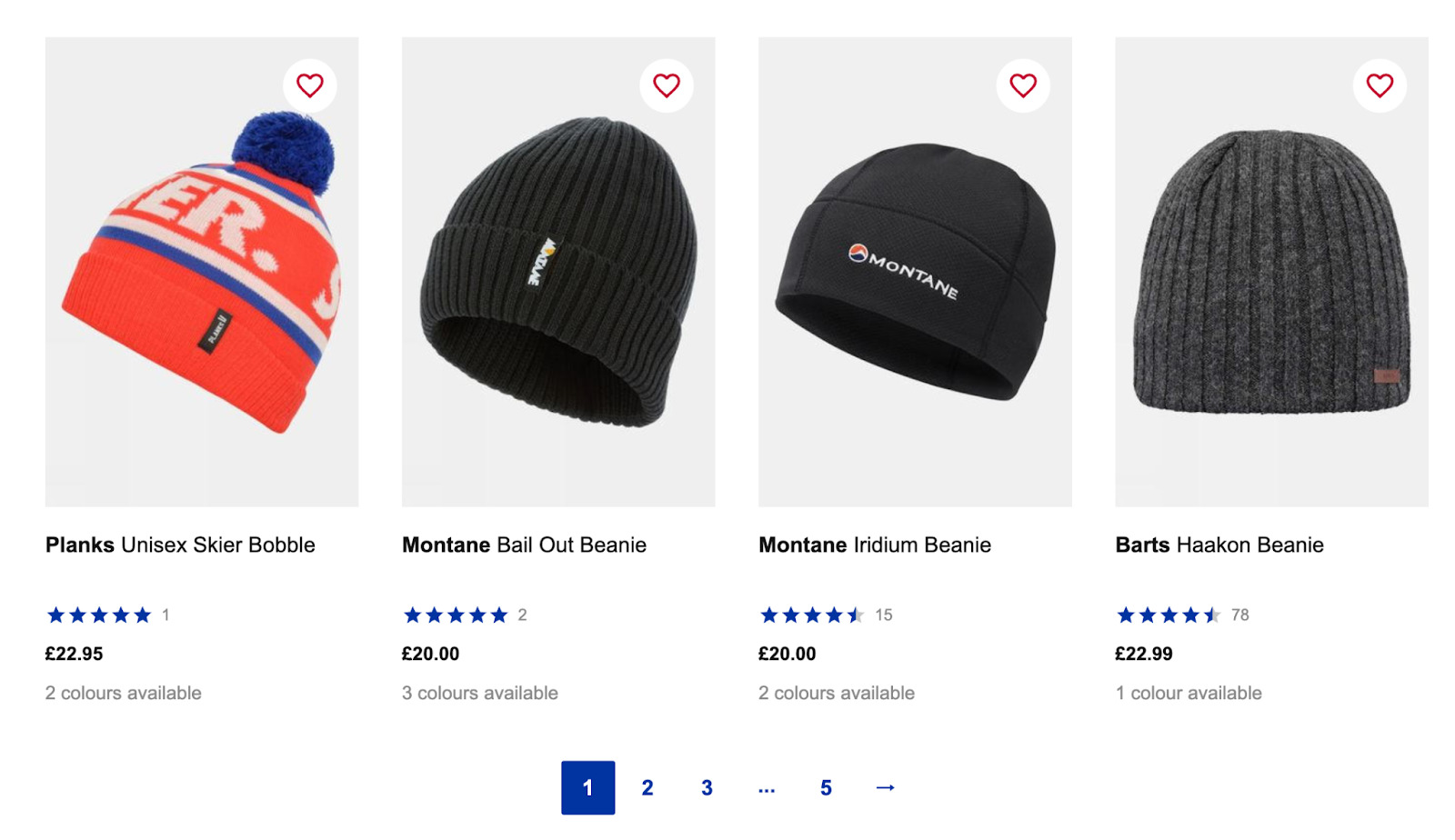
Ini adalah berita bagus karena lebih mudah memilih tombol "Berikutnya" di setiap halaman daripada menelusuri setiap nomor halaman. Bagaimanapun, mari kita lihat bagaimana URL berubah ketika Anda mengklik halaman kedua.
Inilah yang kami temukan:
- Halaman 1: https://www.snowandrock.com/c/mens/accessories/hats.html?page=0&size=48
- Halaman 2: https://www.snowandrock.com/c/mens/accessories/hats.html?page=1&size=48
- Halaman 3: https://www.snoandrock.com/c/mens/accessories/hats.html?page=2&size=48
Perhatikan bahwa ketika Anda kembali ke halaman melalui navigasi, URL halaman pertama berubah dan berubah menjadi halaman=0. Meskipun kami menggunakan tombol Berikutnya untuk menavigasi penomoran halaman situs web ini, hal ini tidak mudah dalam setiap kasus.
Memahami struktur ini, kita dapat membuat fungsi untuk mengubah parameter halaman di URL dan menambahnya sebesar 1 sehingga kita dapat berpindah ke halaman berikutnya tanpa tombol Berikutnya.
Catatan: Tidak semua halaman mengikuti struktur yang sama. Oleh karena itu, selalu periksa parameter mana yang berubah dan bagaimana caranya.
Sekarang setelah kita mengetahui URL asli permintaan tersebut, kita dapat membuat laba-laba khusus.
4. Mengirim permintaan pertama menggunakan metode Start_Requests()
Untuk permintaan pertama, kami membuat kelas Spider dan memberinya nama Pagi:
class PaginationScraper(scrapy.Spider):
name = "pagi"
Kemudian kita mendefinisikan metode start_requests() :
def start_requests(self):
start_urls = ('https://www.snowandrock.com/c/mens/accessories/hats.html')
for url in start_urls:
yield scrapy.Request(url=get_scraperapi_url(url), callback=self.parse)
Sekarang kita telah menjalankan skrip kita, skrip tersebut akan mengirimkan setiap URL baru yang ditemukannya ke metode ini, di mana URL baru tersebut akan digabungkan dengan hasilnya. get_scraperapi_url() Metodenya, mengirimkan permintaan melalui server ScraperAPI dan mengamankan proyek kami.
5. Struktur parser kami
Setelah menguji selector kami dengan Scrapy Shell, berikut adalah selector yang kami kembangkan:
def parse(self, response):
for hats in response.css('div.as-t-product-grid__item'):
yield {
'name': hats.css('.as-a-text.as-m-product-tile__name::text').get(),
'price': hats.css('.as-a-price__value--sell strong::text').get(),
'link': hats.css('a').attrib('href'),
}
Jika Anda belum familiar dengan Scrapy Shell atau Scrapy secara umum, ada baiknya Anda membaca tutorial Scrapy lengkap kami yang membahas semua dasar-dasar yang perlu Anda ketahui.
Namun, pada dasarnya kami memilih semua div yang berisi informasi yang kami inginkan (response.css('div.as-t-product-grid__item') lalu ekstrak nama, harga dan link produk.
6. Lakukan gerakan cepat pada penomoran halaman
Besar! Kami memiliki informasi yang kami butuhkan dari halaman pertama, sekarang bagaimana? Ya, kita perlu memberi tahu parser kita untuk menemukan URL baru dan mengirimkannya ke start_requests() Metode yang kami definisikan sebelumnya. Dengan kata lain, kita perlu mencari ID atau kelas yang memungkinkan kita memasukkan link ke tombol Berikutnya.
Secara teknis kita bisa menggunakan kelas tersebut ‘.as-a-btn.as-a-btn--pagination as-m-pagination__item’ tapi untungnya ada target yang lebih baik: rel=next. Ini tidak akan tertukar dengan penyeleksi lainnya dan memilih atribut dengan Scrapy sangatlah mudah.
next_page = response.css('a(rel=next)').attrib('href')
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
Sekarang lakukan iterasi antar halaman hingga tidak ada lagi halaman di penomoran halaman - jadi kita tidak perlu menyiapkan mekanisme penghentian lainnya.
Jika Anda mengikutinya, file Anda akan terlihat seperti ini:
import scrapy
from urllib.parse import urlencode
API_KEY = '51e43be283e4db2a5afb62660xxxxxx'
def get_scraperapi_url(url):
payload = {'api_key': API_KEY, 'url': url}
proxy_url = 'http://api.scraperapi.com/?' + urlencode(payload)
return proxy_url
class PaginationScraper(scrapy.Spider):
name = "pagi"
def start_requests(self):
start_urls = ('https://www.snowandrock.com/c/mens/accessories/hats.html')
for url in start_urls:
yield scrapy.Request(url=get_scraperapi_url(url), callback=self.parse)
def parse(self, response):
for hats in response.css('div.as-t-product-grid__item'):
yield {
'name': hats.css('.as-a-text.as-m-product-tile__name::text').get(),
'price': hats.css('.as-a-price__value--sell strong::text').get(),
'link': hats.css('a').attrib('href'),
}
next_page = response.css('a(rel=next)').attrib('href')
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
Sekarang siap digunakan!
Menangani penomoran halaman tanpa tombol berikutnya
Sejauh ini kita telah melihat cara membuat web scraper yang menelusuri pagination menggunakan link di tombol Berikutnya - ingat bahwa Scrapy sebenarnya tidak dapat berinteraksi dengan halaman tersebut, jadi tidak akan berfungsi jika tombolnya harus diklik satu kali. demi satu sehingga lebih banyak konten yang ditampilkan.
Namun, apa jadinya jika itu bukan suatu pilihan? Dengan kata lain, bagaimana kita dapat menavigasi penomoran halaman tanpa bergantung pada tombol “Berikutnya”?
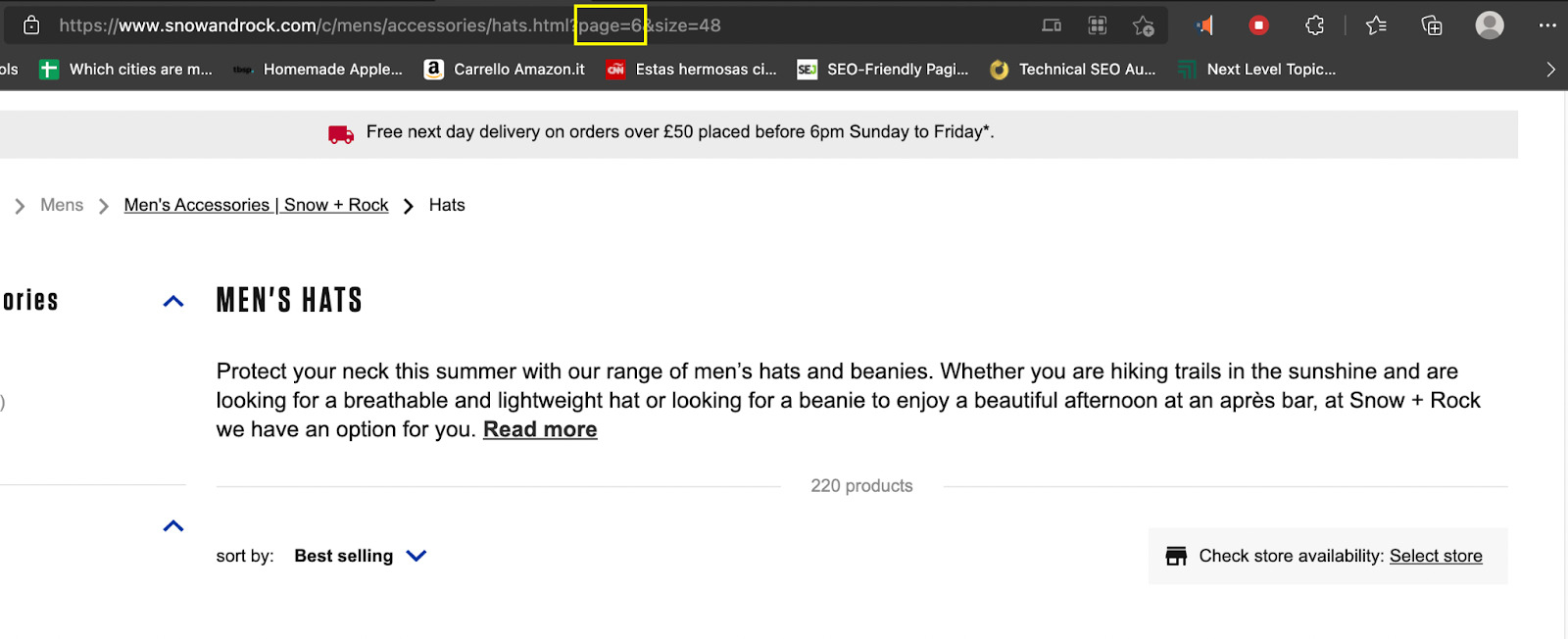
Di sini berguna untuk memahami struktur URL situs web:
- Halaman 1: https://www.snowandrock.com/c/mens/accessories/hats.html?page=0&size=48
- Halaman 2: https://www.snowandrock.com/c/mens/accessories/hats.html?page=1&size=48
- Halaman 3: https://www.snoandrock.com/c/mens/accessories/hats.html?page=2&size=48
Satu-satunya hal yang berubah antar URL adalah parameter halaman, yang bertambah 1 untuk setiap halaman berikutnya. Apa artinya ini bagi naskah kita? Pertama-tama kita perlu mengubah cara kita mengirimkan permintaan asli dengan menambahkan variabel baru:
class PaginationScraper(scrapy.Spider):
name = "pagi"
page_number = 1
start_urls = ('http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.snowandrock.com/c/mens/accessories/hats.html?page=0&size=48')
Dalam hal ini, kami juga menggunakan struktur cURL langsung ScraperAPI karena kami hanya mengubah satu parameter - artinya tidak perlu membuat URL yang sepenuhnya baru. Dengan cara ini, setiap kali ada perubahan, permintaan akan terus dikirim melalui server ScraperAPI.
Selanjutnya, kita perlu mengubah kondisi kita di akhir untuk beradaptasi dengan logika baru:
next_page = 'http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.snowandrock.com/c/mens/accessories/hats.html?page=' + str(PaginationScraper.page_number) + '&size=48'
if PaginationScraper.page_number
Apa yang terjadi di sini adalah kita mengakses variabel page_number melalui PaginationScraper() Metode untuk mengganti nilai parameter halaman dalam URL.
Ia kemudian memeriksa apakah nilai nomor halaman kurang dari 6 - karena tidak ada hasil lagi setelah halaman 5.
Asalkan syaratnya terpenuhi, maka akan bertambah page_number Nilai dengan 1 dan kirimkan URL untuk parsing dan scraping dll hingga page_number adalah 6 atau lebih.
Ini dia Kode lengkap untuk mengikis halaman yang diberi nomor halaman tanpa tombol Berikutnya:
import scrapy
class PaginationScraper(scrapy.Spider):
name = "pagi"
page_number = 1
start_urls = ('http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660xxxxxxx&url=https://www.snowandrock.com/c/mens/accessories/hats.html?page=0&size=48')
def parse(self, response):
for hats in response.css('div.as-t-product-grid__item'):
yield {
'name': hats.css('.as-a-text.as-m-product-tile__name::text').get(),
'price': hats.css('.as-a-price__value--sell strong::text').get(),
'link': 'https://www.snowandrock.com/' + hats.css('a').attrib('href')
}
next_page = 'http://api.scraperapi.com?api_key=51e43be283e4db2a5afb62660fc6ee44&url=https://www.snowandrock.com/c/mens/accessories/hats.html?page=' + str(PaginationScraper.page_number) + '&size=48'
if PaginationScraper.page_number
Ringkasan
Baik Anda mengumpulkan data real estat atau menelusuri platform e-commerce seperti Etsy, berurusan dengan penomoran halaman adalah hal biasa dan Anda harus bersiap untuk menjadi kreatif.
Data alternatif telah menjadi suatu keharusan bagi hampir setiap industri di dunia, dan kemampuan untuk menciptakan scraper yang kompleks dan efisien akan memberi Anda keunggulan kompetitif yang besar.
Apakah Anda seorang pengembang lepas atau pemilik bisnis yang siap berinvestasi dalam pengikisan web, ScraperAPI memiliki semua alat yang Anda butuhkan untuk mengumpulkan data dengan mudah dengan secara otomatis menghilangkan semua hambatan bagi Anda.
Sampai jumpa lagi, selamat menggores!
