Siap untuk memulai? Ayo selami!
Memahami Ikhtisar AI Google
Cuplikan atau ikhtisar Google AI lebih dari sekadar jawaban cepat - cuplikan atau ikhtisar ini penuh dengan wawasan berharga. Saat Google menampilkan cuplikan yang dihasilkan AI di bagian atas hasil penelusuran, Google memberikan apa yang diyakininya sebagai jawaban terbaik atas sebuah pertanyaan berdasarkan analisis jutaan halaman web.
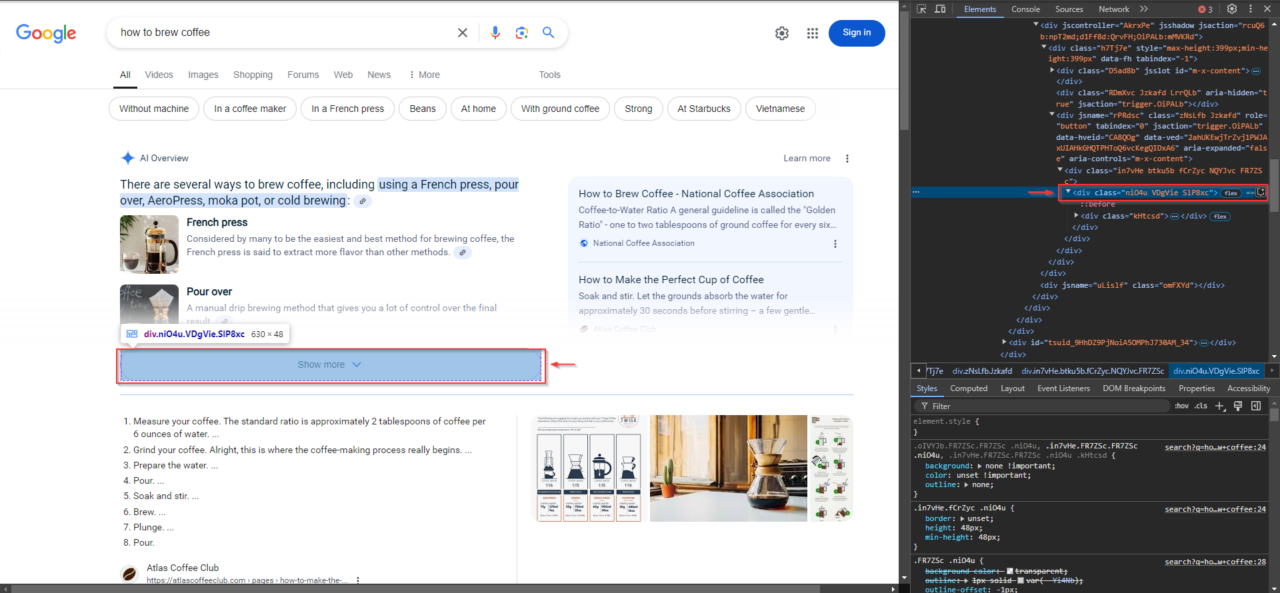
Mari kita lihat contoh nyata. Jika Anda menelusuri “cara menyeduh kopi” di Google, Anda mungkin melihat ikhtisar AI yang terlihat seperti ini:
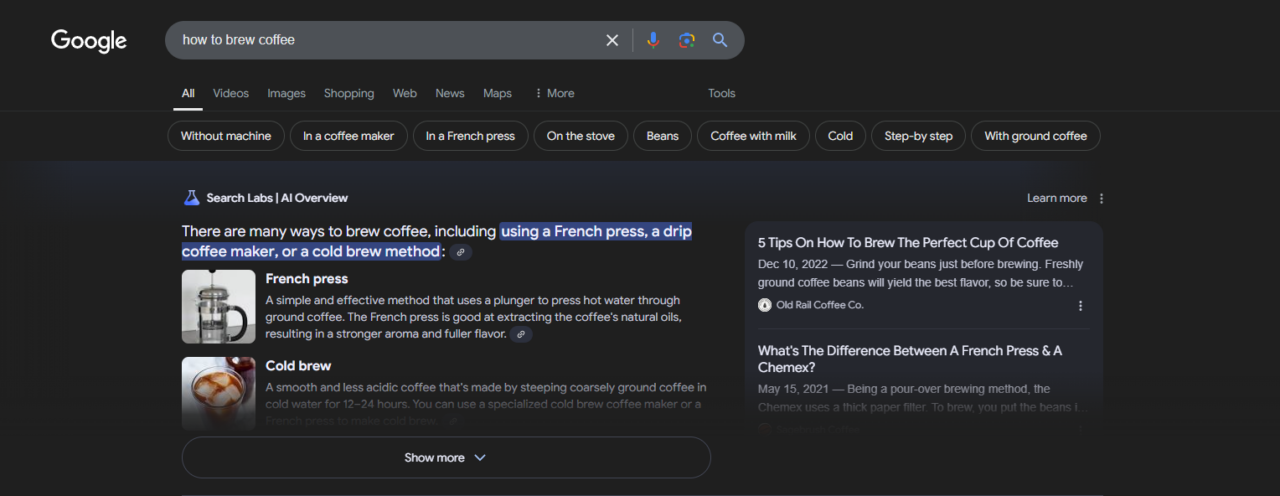
Untuk mengekstrak data ini secara efektif, penting untuk mengidentifikasi pemilih yang tepat untuk setiap bagian cuplikan. Inilah cara saya melakukannya:
1. Identifikasi kelas konten
Konten utama cuplikan AI ada di elemen dengan kelas WaaZC. Elemen ini mencakup deskripsi teks dan cuplikan yang relevan dengan kueri penelusuran. Anda dapat menggunakan alat Inspeksi browser Anda untuk menemukan kelas ini dan melihat bagaimana Google menyusun informasi ini.
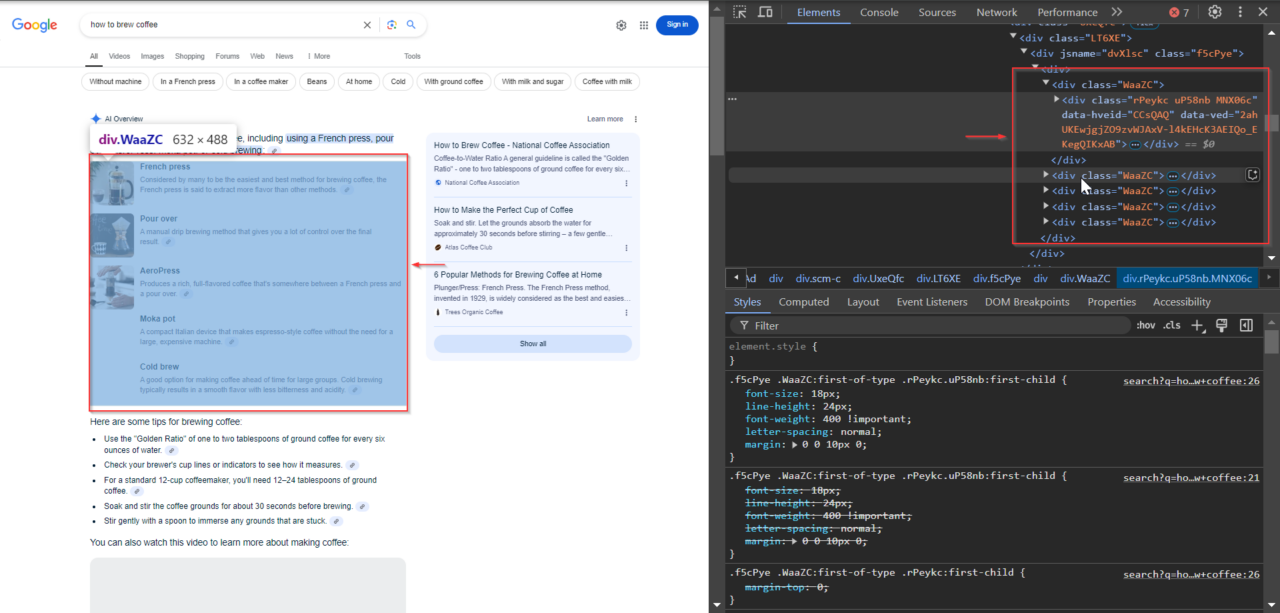
2. Menemukan link terkait
Di bawah cuplikan, Google sering kali menyertakan tautan terkait ke sumber resmi yang digunakan perusahaan untuk membuat cuplikan. Tautan ini ada dalam elemen dengan kelas VqeGe. Memeriksa strukturnya akan mengungkapkan wadah yang berisi tautan ini sehingga dapat diekstraksi bersama dengan cuplikannya.
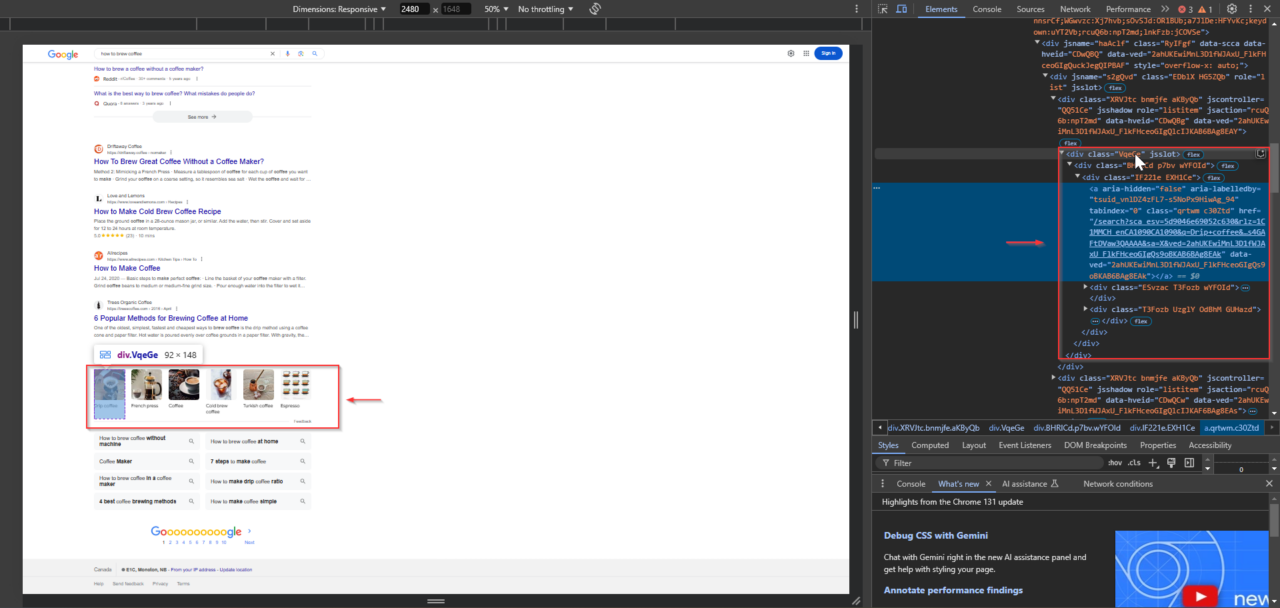
3. Temukan tombol “Tampilkan Lebih Banyak”.
Kueri dengan konten cuplikan AI yang lebih panjang mungkin menampilkan tombol Tampilkan Lebih Banyak. Tombol ini penting untuk memperluas konten guna memastikan tidak ada yang terlewat. Untuk mengidentifikasinya, klik kanan tombol “Show More” di browser Anda dan pilih "Memeriksa"lalu klik kanan item yang disorot di panel DevTools dan pilih “Salin XPath”.
Cuplikan ini dapat membantu Anda memahami:
- Apa yang ingin diketahui orang: Dengan melihat pertanyaan yang diterima cuplikan AI, Anda dapat mengetahui apa yang ditelusuri orang dan bagaimana Google menjawab pertanyaan mereka. Dengan cara ini Anda dapat dengan cepat melihat apa yang populer dan relevan.
- Apa yang dihargai oleh Google: Google memilih jenis jawaban tertentu untuk disorot, seperti petunjuk langkah demi langkah, daftar, atau definisi singkat. Memperhatikan pola-pola ini akan membantu Anda melihat jenis konten apa yang paling dihargai oleh AI Google.
- Cara meningkatkan konten Anda: Karena cuplikan ini mencerminkan gagasan Google tentang jawaban yang baik, mempelajari kata-kata dan strukturnya dapat membantu Anda memahami cara membuat konten Anda lebih ramah penelusuran.
Cuplikan AI sering kali juga berisi tautan ke sumber tempat Google memperoleh informasi. Tautan ini meningkatkan kredibilitas cuplikan dan menunjukkan situs web mana yang dianggap resmi oleh Google untuk topik tersebut. Mengikis tautan dan cuplikan ini dapat mengungkapkan hubungan yang berguna untuk penelitian lebih lanjut.
Mengakses cuplikan ini dapat menjadi tantangan karena Google secara aktif mencoba memblokir akses otomatis. Namun jangan khawatir - panduan ini akan menunjukkan dengan tepat cara mengatasi hambatan ini dan mengekstrak data yang Anda perlukan!
Persyaratan proyek
Inilah yang Anda perlukan untuk memulai proyek:
1. Kawat selenium
Selenium Wire adalah perpustakaan yang memperluas fungsionalitas Selenium. Hal ini mempermudah pengaturan proxy sehingga permintaan Anda tampak seolah-olah berasal dari alamat IP yang berbeda. Fitur ini penting karena Google dapat memblokir permintaan dari IP yang sama jika permintaan tersebut masuk terlalu sering.
Dengan menggunakan Selenium Wire dengan ScraperAPI, Anda dapat mengotomatiskan pencarian Google sekaligus meminimalkan risiko pemblokiran. ScraperAPI menangani hal-hal seperti rotasi IP dan resolusi CAPTCHA, yang diperlukan untuk kelancaran interaksi dengan halaman hasil mesin pencari Google (SERP).
Instal dengan pip:
pip install selenium selenium-wire
Anda juga memerlukan ChromeDriver atau WebDriver lain yang kompatibel dan sesuai dengan versi browser Anda. Pastikan itu tersedia di Anda PATHatau tentukan jalur dalam skrip Anda.
2. API Pengikis
Masuk ke ScraperAPI untuk mendapatkan kunci API Anda jika Anda belum melakukannya. Setelah mendaftar, Anda akan menerima kunci unik yang Anda perlukan untuk mengautentikasi permintaan Anda.
3. Sup yang enak
BeautifulSoup membantu kami menganalisis hasil pencarian Google secara efisien setelah ScraperAPI memuat halaman.
Instal dengan pip:
pip install beautifulsoup4
Dengan alat-alat ini, kita bisa mulai mengikis!
Cara mengikis cuplikan Google AI dengan ScraperAPI dan Python
Sekarang setelah kita memahami cuplikan AI dan menyiapkan alatnya, mari kita mulai proses pengikisan yang sebenarnya.
Langkah 1: Impor perpustakaan dan atur variabel
Sebelum kita mempelajari fitur-fitur utama, mari kita mulai dengan mengimpor perpustakaan yang diperlukan dan menyiapkan variabel. Berikut ikhtisar singkat tentang fungsi setiap bagian:
- Impor:
seleniumwire.webdriver: Ini adalah alat utama yang kami gunakan untuk mengontrol browser, memungkinkan skrip kami berinteraksi dengan hasil penelusuran Google seolah-olah itu adalah pengguna sebenarnya.selenium.webdriver.common.by: Kami menggunakan ini untuk menemukan elemen pada halaman, seperti: B. tombol “Tampilkan lebih banyak”.By.XPATH.selenium.common.exceptions: Kami akan menggunakan ini untuk menangani kesalahan sepertiNoSuchElementExceptionDanTimeoutExceptionmembuat skrip kami lebih tangguh.time: Kami menambahkan penundaantimeuntuk memberi kesempatan pada konten dinamis untuk dimuat sebelum kami menghapusnya.csv: Kami akan menggunakancsvuntuk menyimpan data yang kami ekstrak ke file CSV agar mudah dianalisis.BeautifulSoup: Kami menggunakan BeautifulSoup untuk mengurai HTML halaman guna menemukan dan mengekstrak titik data spesifik yang kami perlukan.
- variabel:
url: URL kueri penelusuran Google (misalnya “cara membuat kopi”). Ubah ini ke kueri apa pun yang ingin Anda cari.show_more_xpath: XPath digunakan untuk menemukan tombol Tampilkan Lebih Banyak sehingga kita dapat memperluas konten tersembunyi jika ada.content_classDanlink_classes: Nama kelas CSS yang membantu kami menargetkan konten cuplikan AI laman dan tautan terkait.output_file: Nama file CSV tempat kita menyimpan data hasil ekstrak.max_retries: Menetapkan jumlah maksimum percobaan ulang jika terjadi kesalahan saat pengikisan.
- Konfigurasi ScraperAPI:
API_KEY: Pengganti"Your_ScraperAPI_Key"dengan kunci ScraperAPI unik Anda.proxy_options: Mengonfigurasi pengaturan proksi ScraperAPI untuk Selenium Wire.
Metode port proksi ScraperAPI adalah cara mudah untuk mengintegrasikan fitur proksi seperti rotasi IP, resolusi CAPTCHA, dan rendering JavaScript ke dalam scraper Anda. Daripada mengonfigurasi beberapa opsi rumit, Anda cukup terhubung melalui server proxy yang melakukan segalanya untuk Anda.
Berikut cara pengaturannya dalam kode kami:
proxy_options = {
'proxy': {
'https': f'http://scraperapi.render=true:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
proxy-server.scraperapi.com:8001: Ini adalah server proxy ScraperAPI yang mendengarkan di port8001. Ini menangani semua permintaan termasuk rotasi IP, resolusi CAPTCHA, dan rendering konten JavaScript.render=true: Parameter ini mengaktifkan rendering JavaScript, yang penting untuk memuat penuh halaman dinamis Google.- Autentikasi: Itu
API_KEYtertanam langsung ke URL proksi dan mengautentikasi permintaan Anda tanpa memerlukan pengaturan tambahan apa pun. - Pengecualian:
no_proxymemastikan permintaan lokal (sepertilocalhost) melewati proxy dan dengan demikian menghindari overhead yang tidak perlu.
Penggunaan metode ini menyederhanakan integrasi proxy, memungkinkan Anda fokus pada logika scraping sementara ScraperAPI melakukan pekerjaan berat di latar belakang.
Untuk informasi mendetail tentang metode port proxy ScraperAPI dan opsi konfigurasi, lihat dokumentasi kami.
Berikut ini kode pengaturan awal selengkapnya:
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException, TimeoutException
import time
import csv
from bs4 import BeautifulSoup
# Variables
url = 'https://www.google.com/search?q=how+to+brew+coffee'
show_more_xpath = "/html/body/div(3)/div/div(13)/div(1)/div(2)/div/div/div(1)/div/div(1)/div/div/div/div(1)/div/div(3)/div/div"
content_class = "WaaZC"
link_classes = "VqeGe"
output_file = "extracted_data.csv"
max_retries = 3
# ScraperAPI configuration
API_KEY = "Your_Scraperapi_Key"
proxy_options = {
'proxy': {
'https': f'http://scraperapi.render=true:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
Langkah 2: Menyiapkan WebDriver
Selanjutnya kita perlu menyiapkan WebDriver, yang memungkinkan kita mengontrol browser dan berinteraksi dengan Google. Itu setup_driver Fungsi ini menginisialisasi instance Selenium WebDriver dengan konfigurasi proksi ScraperAPI.
Fungsi ini juga membuka URL target (dalam contoh ini, pencarian Google untuk “cara menyeduh kopi”) dan mengembalikan contoh driver.
def setup_driver():
driver = webdriver.Chrome(seleniumwire_options=proxy_options)
driver.get(url)
return driver
Dengan memanggil fungsi ini kita dapat menggunakan kembali driver dalam beberapa langkah tanpa perlu mengkonfigurasi ulang proxy atau membuka kembali browser setiap saat.
Langkah 3: Klik tombol “Tampilkan Lebih Banyak”.
Terkadang cuplikan AI Google berisi informasi tambahan yang tersembunyi di balik tombol "Tampilkan Lebih Banyak". Misalnya, pada gambar sebelumnya, cuplikan menunjukkan beberapa metode pembuatan kopi, namun beberapa konten ini mungkin tidak dapat diakses sampai Anda mengklik Tampilkan Lebih Banyak.
Untuk memastikan bahwa kami menangkap semua data yang tersedia dalam cuplikan ini, skrip kami perlu menemukan dan mengklik tombol Tampilkan Lebih Banyak jika ada. Dengan cara ini kami dapat memperluas cuplikan dan menghapus konten tambahan apa pun.
Itu click_show_more Fungsi ini mencoba menemukan dan mengklik tombol Tampilkan Lebih Banyak menggunakan XPath-nya. Jika berhasil, ia mengembalikan True, memberi tahu seluruh kode kita bahwa konten telah diperluas. Jika tombol tidak ditemukan atau terjadi kesalahan, False dikembalikan.
def click_show_more(driver):
"""Attempt to find and click the 'Show More' button"""
try:
element_to_click = driver.find_element(By.XPATH, show_more_xpath)
element_to_click.click()
print("Show More button clicked successfully.")
return True
except NoSuchElementException:
print("Show More button not found")
return False
except Exception as e:
print(f"Error clicking Show More button: {e}")
return False
Langkah 4: Ekstrak konten dan tautan
Setelah konten terlihat sepenuhnya, kita dapat mulai mengekstraksi. Fungsi ekstrak_konten menghapus konten teks dan tautan terkait dari halaman.
- Konten teks: Kami menggunakan BeautifulSoup untuk mengurai HTML sumber halaman dan menemukan semua elemen dengan kelas yang ditentukan di dalamnya
content_class. Kelas ini menargetkan bagian yang berisi cuplikan AI. Teks dari setiap cuplikan diekstraksi dan disimpan di acontentDaftar sebagai kamus dengan kuncinya"Section Text". - Tautan terkait: Kami juga mencari elemen tautan terkait
link_classes. Tautan apa punhrefAtribut (URL) disimpan dalam daftar tautan sebagai kamus dengan kuncinya"Related Links".
Keduanya content dan daftar tautan diringkas combined_datayang berisi semua informasi yang diekstraksi untuk disimpan pada langkah berikutnya.
def extract_content(driver):
"""Extract text content and links from the specified elements"""
content = ()
links = ()
try:
# Extracting text content
soup = BeautifulSoup(driver.page_source, 'html.parser')
text_elements = soup.find_all('div', class_=content_class)
for text_element in text_elements:
extracted_text = text_element.text
print(f"Extracted Text: {extracted_text}")
content.append({"Section Text": extracted_text})
except Exception as e:
print(f"Error extracting content: {e}")
try:
# Extracting related links
related_link_divs = soup.find_all('div', class_=link_classes)
for div in related_link_divs:
href = div.find('a')('href')
print(href)
links.append({"Related Links": href})
except Exception as e:
print(f"Error extracting links: {e}")
# Combine content and links into a single list for CSV
combined_data = content + links
return combined_data
Langkah 5: Simpan data ke file CSV
Sekarang kita telah mengumpulkan data, sekarang saatnya menyimpannya untuk dianalisis. Itu save_to_csv Fungsi ini menulis konten yang diekstraksi dan menautkan ke file CSV.
Inilah cara kami melakukannya:
- Cari datanya: Pertama kita periksa apakah data dapat disimpan. Jika tidak, kami mencetak pesan dan segera menghentikan fungsinya.
- Buka berkas CSV: Ketika data tersedia, kami membuka (atau membuat) file CSV dengan nama yang ditentukan
output_file. Kami menetapkan judul ke "Teks Bagian" dan "Tautan Terkait" agar sesuai dengan struktur data kami. - Tulis data: Terakhir, kami menulis setiap entri
combined_dataSisipkan baris demi baris ke dalam file CSV agar siap dianalisis.
def save_to_csv(data, filename):
"""Save extracted data to CSV file"""
if not data:
print("No data to save")
return False
headers = ('Section Text', 'Related Links')
try:
with open(filename, 'w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=headers)
writer.writeheader()
for item in data:
writer.writerow(item)
print(f"Data saved to {filename} successfully.")
return True
except Exception as e:
print(f"Error saving to CSV: {e}")
return False
Hal ini memastikan bahwa data yang kami ekstrak disimpan dengan aman dalam format CSV yang mudah digunakan.
Langkah 6: Gabungkan semuanya ke dalam fungsi utama
Sekarang mari kita gabungkan semuanya menjadi milik kita main Berfungsi untuk menangani seluruh proses pengikisan dari awal hingga akhir. Inilah cara kami melakukannya:
- Ulangi logika: Kita mulai dengan pengaturan
retry_countke nol untuk mengulangi proses pengikisanmax_retriesjika ada masalah yang muncul. - Inisialisasi WebDriver: Kami akan menelepon
setup_driver()untuk membuka browser dan memuat halaman pencarian. - Klik "Tampilkan lebih banyak" dan ekstrak isinya: Kami akan mencoba
click_show_more()Berikutnya. Jika klik untuk memperluas konten lebih lanjut berhasil, kami mengekstrak semua data yang terlihatextract_content(). - Simpan data dalam format CSV: Kami akan menelepon
save_to_csv()untuk menuliskannya ke file CSV setelah kami memiliki data. Jika langkah ini berhasil diselesaikan, selesai! - Tutup browser dan coba lagi jika perlu: Setelah setiap upaya, kami menutup WebDriver dan menunggu 2 detik sebelum mencoba lagi jika perlu. Ketika jumlah percobaan ulang telah habis, kami akan menerima pesan yang memberitahukan bahwa kami telah mencapai batas.
def main():
retry_count = 0
while retry_count
Terakhir, jangan lupa memanggil fungsi utama Anda agar semuanya berjalan dan mengekstrak data Anda:
if __name__ == "__main__":
main()
Berikut ini contoh tampilan file CSV:
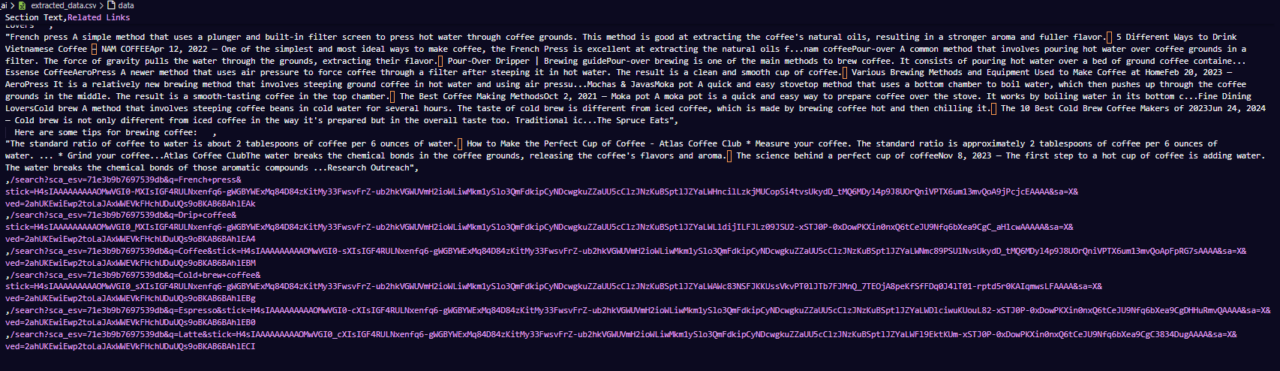
Langkah terakhir ini menyatukan semuanya dan memberi kita skrip otomatis yang siap mengekstrak dan menyimpan cuplikan Google AI untuk dianalisis!
Kode lengkap
Berikut kode lengkapnya jika Anda ingin langsung mulai melakukan scraping:
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException, TimeoutException
import time
import csv
from bs4 import BeautifulSoup
# Variables
url = 'https://www.google.com/search?q=how+to+brew+coffee'
show_more_xpath = "/html/body/div(3)/div/div(13)/div(1)/div(2)/div/div/div(1)/div/div(1)/div/div/div/div(1)/div/div(3)/div/div"
content_class = "WaaZC"
link_classes = "VqeGe"
output_file = "extracted_data.csv"
max_retries = 3
# ScraperAPI configuration
API_KEY = "Your_ScraperAPI_Key"
proxy_options = {
'proxy': {
'https': f'http://scraperapi.render=true:{API_KEY}@proxy-server.scraperapi.com:8001',
'no_proxy': 'localhost,127.0.0.1'
}
}
def setup_driver():
driver = webdriver.Chrome(seleniumwire_options=proxy_options)
driver.get(url)
return driver
def click_show_more(driver):
"""Attempt to find and click the 'Show More' button"""
try:
element_to_click = driver.find_element(By.XPATH, show_more_xpath)
element_to_click.click()
print("Show More button clicked successfully.")
return True
except NoSuchElementException:
print("Show More button not found")
return False
except Exception as e:
print(f"Error clicking Show More button: {e}")
return False
def extract_content(driver):
"""Extract text content and links from the specified elements"""
content = ()
links = ()
try:
# Extracting text content
soup = BeautifulSoup(driver.page_source, 'html.parser')
text_elements = soup.find_all('div', class_=content_class)
for text_element in text_elements:
extracted_text = text_element.text
print(f"Extracted Text: {extracted_text}")
content.append({
"Section Text": extracted_text
})
except Exception as e:
print(f"Error extracting content: {e}")
try:
# Extracting related links
related_link_divs = soup.find_all('div', class_=link_classes)
for div in related_link_divs:
href = div.find('a')('href')
print(href)
links.append({
"Related Links": href
})
except Exception as e:
print(f"Error extracting links: {e}")
# Combine content and links into a single list for CSV
combined_data = content + links
return combined_data
def save_to_csv(data, filename):
"""Save extracted data to CSV file"""
if not data:
print("No data to save")
return False
# Define the CSV headers
headers = ('Section Text', 'Related Links')
try:
with open(filename, 'w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=headers)
writer.writeheader()
for item in data:
writer.writerow(item)
print(f"Data saved to {filename} successfully.")
return True
except Exception as e:
print(f"Error saving to CSV: {e}")
return False
def main():
retry_count = 0
while retry_count
Kiat tambahan: Menangani cuplikan AI yang hilang
Terkadang cuplikan AI Google tidak ditampilkan secara konsisten, bahkan untuk kueri yang dibuat dengan baik. Berikut beberapa tip tambahan untuk membantu Anda menangani kasus ketika cuplikan AI tidak segera tersedia:
1. Tingkatkan jumlah percobaan ulang
Kode kita saat ini sudah berisi logika pengulangan. Namun, jika cuplikan AI muncul tidak konsisten, pertimbangkan untuk meningkatkannya max_retries. Mengizinkan lebih banyak upaya akan memberikan peluang lebih besar bagi skrip untuk menangkap cuplikan saat dimuat pada upaya berikutnya. Mulailah dengan menggandakan percobaan ulang jika cuplikan hilang setelah beberapa upaya pertama Anda.
2. Tambahkan sedikit penundaan di antara percobaan ulang
Memperkenalkan sedikit penundaan di antara percobaan ulang, like time.sleep(5)dapat meningkatkan hasil dengan memberi Google waktu tambahan untuk memuat cuplikan. Menambahkan penundaan ini setelah setiap percobaan ulang membantu menghindari akses berulang kali ke Google terlalu cepat, yang juga dapat mengakibatkan pembatasan kecepatan.
3. Bereksperimenlah dengan pertanyaan serupa
Jika Anda masih tidak melihat cuplikan AI, mungkin ada gunanya bereksperimen dengan varian kueri yang sedikit berbeda yang mungkin memicu cuplikan dengan lebih andal. Misalnya, jika pertanyaan pertama Anda adalah "Cara membuat kopi", coba gunakan frasa terkait seperti "Cara terbaik membuat kopi" atau "Langkah-langkah membuat kopi".
4. Catat hasil setiap percobaan
Pertimbangkan untuk menambahkan fitur logging untuk melacak apakah cuplikan berhasil diambil pada setiap upaya. Hal ini membantu Anda menganalisis pola dari waktu ke waktu—seperti dalam kueri tertentu atau saat cuplikan lebih sering muncul—sehingga Anda dapat menyempurnakan pendekatan sesuai kebutuhan.
5. Pantau data yang kosong
Jika extract_content() Jika hasilnya kosong setelah semua percobaan ulang, Anda harus mencatatnya sebagai upaya yang gagal. Dengan melacak kueri mana yang tidak memicu cuplikan, Anda dapat menyesuaikan pendekatan dan menghindari penghapusan kueri tersebut berulang kali.
Ringkasan
Dan itu saja! Cuplikan AI Google tidak hanya memberikan jawaban cepat - cuplikan juga menunjukkan apa yang diminati orang, apa yang sedang tren, dan konten apa yang dihargai Google. Dengan mengumpulkan dan menganalisis cuplikan ini, Anda mengumpulkan data dan memperoleh wawasan yang dapat membantu Anda membuat konten yang lebih relevan dan berdampak.
Dengan langkah-langkah yang kami uraikan, Anda akan memiliki semua yang Anda perlukan untuk mengumpulkan data ini. Untuk membuatnya lebih mudah, cobalah ScraperAPI – yang menangani rotasi IP, CAPTCHA, dan rendering, sehingga Anda dapat menggunakan wawasan ini untuk meningkatkan strategi konten Anda tanpa harus mengkhawatirkan kendala teknis.
Selamat bersenang-senang!
