
Mengekstraksi data dari situs web menjadi hal yang penting dalam berbagai bidang, mulai dari pengumpulan data hingga analisis persaingan. Namun, mungkin sulit untuk menangkap konten yang dimuat melalui JavaScript, permintaan AJAX, dan interaksi kompleks menggunakan alat sederhana. Di sinilah alat otomatisasi browser tanpa kepala seperti Playwright berperan.
Di blog ini, kita akan melihat penggunaan Playwright untuk web scraping. Kami akan mengeksplorasi manfaatnya, pengikisan halaman tunggal dan ganda, penanganan kesalahan, klik tombol, pengiriman formulir, dan teknik penting seperti menggunakan proxy untuk melewati deteksi dan mencegat permintaan. Selanjutnya perbandingan dengan alat web scraping dan otomatisasi lainnya seperti Puppeteer dan Selenium.
Apa itu penulis naskah drama?
Playwright adalah kerangka kerja sumber terbuka populer berdasarkan Node.js untuk pengujian dan otomatisasi web. Ini memungkinkan pengujian Chromium, Firefox dan WebKit dengan satu API. Dikembangkan oleh Microsoft, Playwright menyediakan otomatisasi web lintas browser yang efisien, andal, dan cepat. Ia bekerja di berbagai platform termasuk Windows, Linux dan macOS dan mendukung semua browser web modern. Selain itu, Penulis Drama menawarkan dukungan lintas bahasa untuk TypeScript, JavaScript, Python, .NET, dan Java.
Memulai dengan Penulis Drama
Sebelum melakukan scraping situs web, kami menyiapkan lingkungan Node.js dan Python sistem kami untuk Playwright.
Pengaturan dan instalasi proyek
Untuk nodejs:
Pastikan Anda menginstal Node.js versi terbaru di sistem Anda. Untuk proyek ini kami menggunakan Node.js v20.9.0.
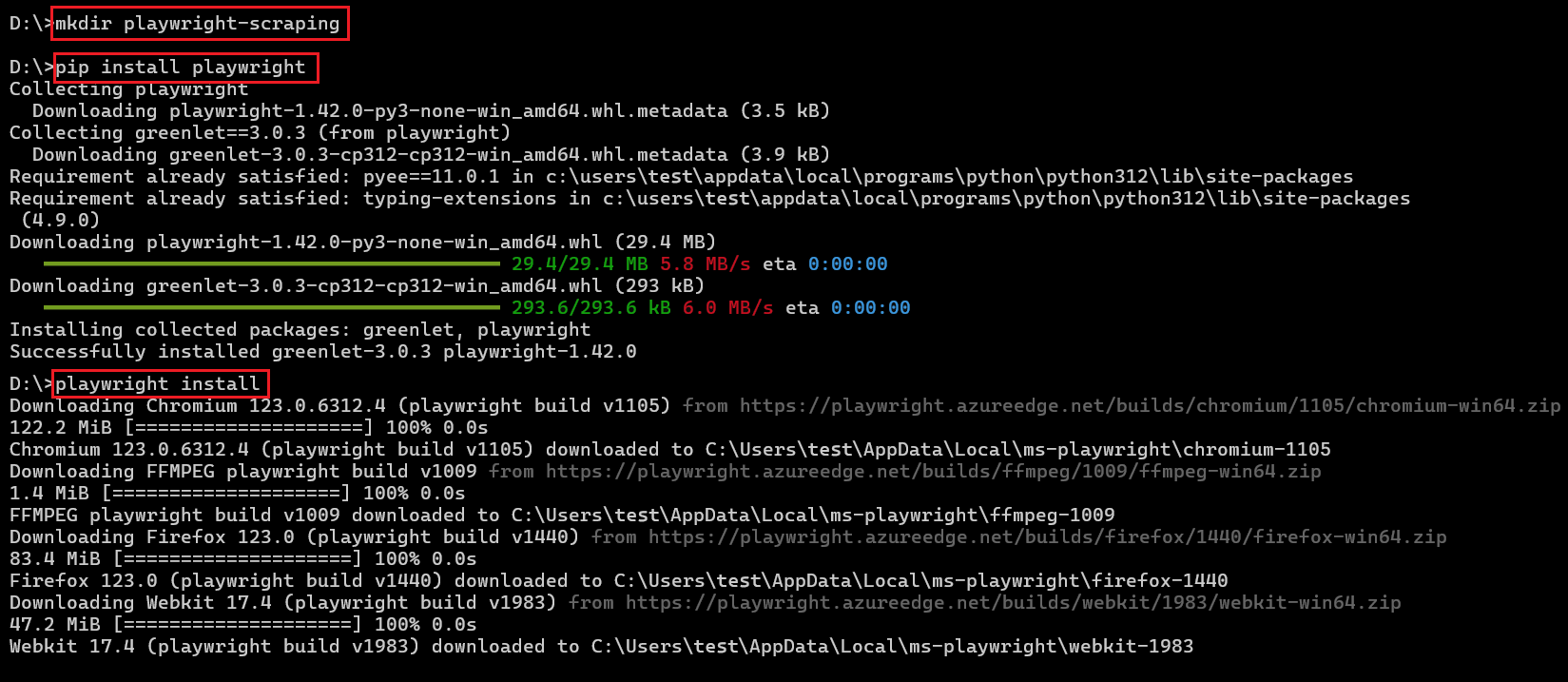
Buat direktori baru untuk proyek Anda, navigasikan ke sana, dan jalankan untuk menginisialisasi proyek Node.js npm init. Itu npm init -y Perintah itu menciptakannya package.json File dengan semua dependensi.
mkdir playwright-scraping
cd playwright-scraping
npm init -ySekarang Anda dapat menginstal Playwright menggunakan NPM:
npm install playwrightUntuk menggunakan Penulis Drama, Anda juga harus menginstal browser yang kompatibel. Setiap versi Playwright memerlukan biner browser tertentu. Jalankan perintah berikut untuk menginstal versi browser terbaru:
npx playwright installIni akan menginstal versi terbaru Chromium, Firefox dan WebKit. Anda dapat menggunakan salah satu browser ini dalam kode Anda, tetapi untuk tutorial ini kami akan menggunakan Chromium.
Seperti inilah proses lengkapnya:
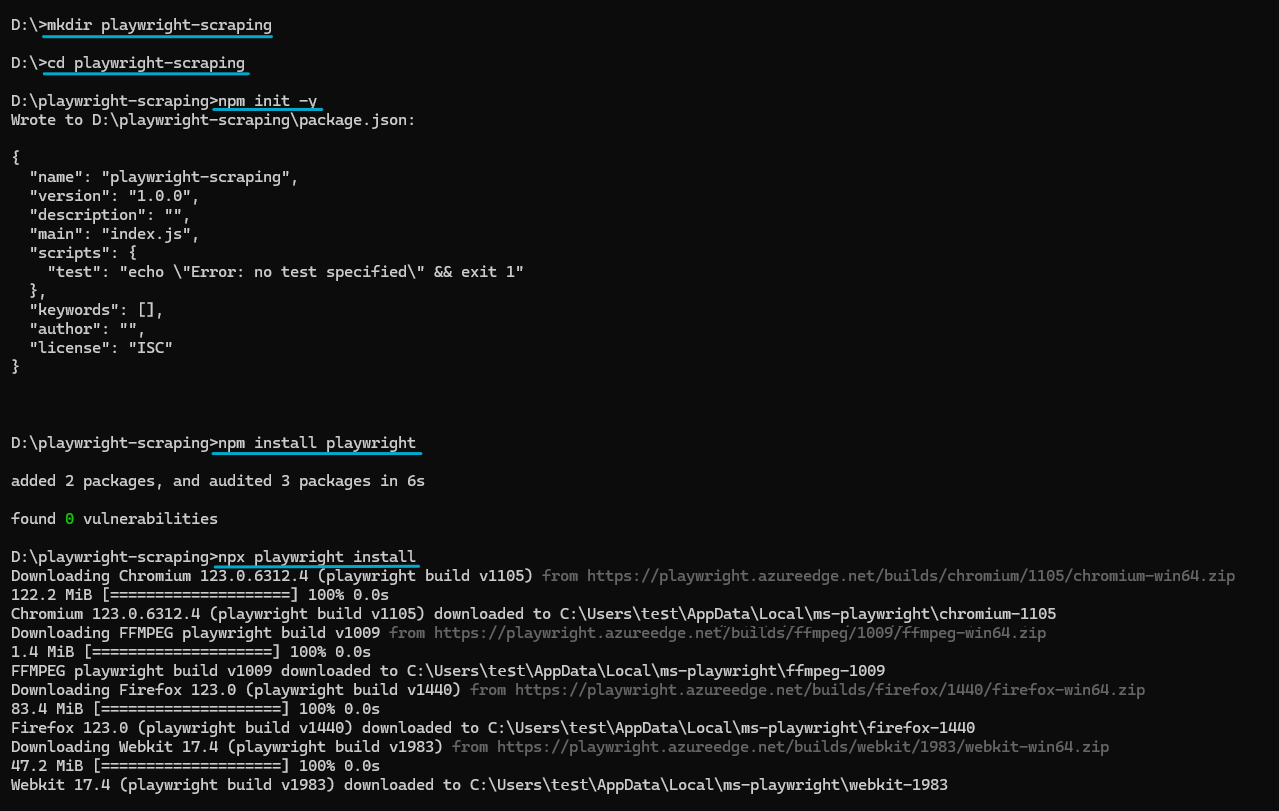
Buka ini package.json Tambahkan dan tambahkan file "type": "module" untuk mendukung sintaksis JavaScript modern.
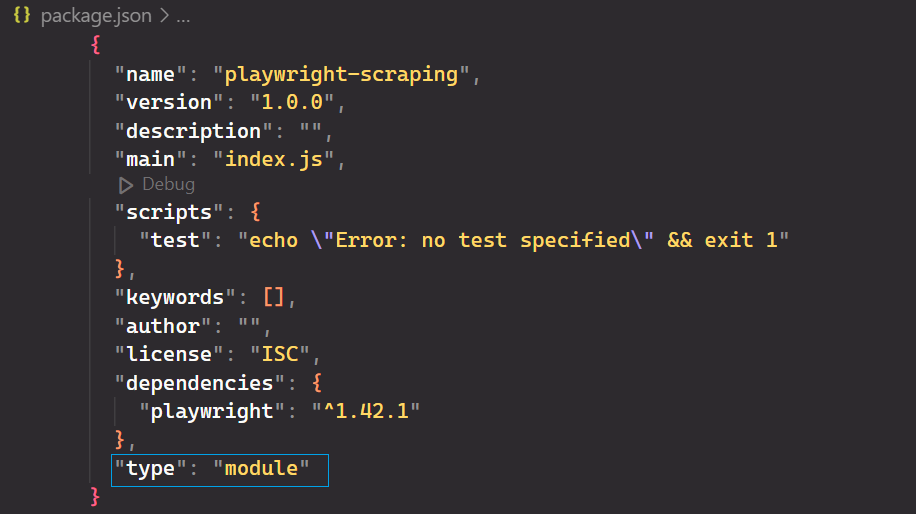
Terakhir, buka proyek di editor kode favorit Anda dan buat file baru bernama index.js.
Untuk Python:
Pastikan Anda menginstal Python versi terbaru di sistem Anda. Selanjutnya, instal pustaka Playwright Python dan browser yang diperlukan.
pip install playwright
playwright installSeperti inilah proses lengkapnya:
Peluncuran Penulis Drama
Untuk nodejs:
Mari kita tulis kode Playwright pertama kita yang membuka halaman baru di browser Chromium.
import { chromium } from 'playwright';
async function main() {
// Launch a new instance of a Chromium browser with headless mode
// disabled for visibility
const browser = await chromium.launch({
headless: false
});
// Create a new Playwright context to isolate browsing session
const context = await browser.newContext();
// Open a new page/tab within the context
const page = await context.newPage();
// Navigate to the GitHub topics homepage
await page.goto('<https://github.com/topics>');
// Wait for 1 second to ensure page content loads properly
await page.waitForTimeout(1000);
// Close the browser instance after task completion
await browser.close();
}
// Execute the main function
main();Kode di atas mengimpor chromium Modul untuk mengendalikan browser berbasis Chromium. Browser Chromium baru yang terlihat kemudian akan diluncurkan chromium.launch() dengan headless Opsi disetel ke False. Halaman browser baru akan terbuka dan page.goto() Fungsi ini menavigasi ke halaman web topik GitHub. Setelah menunggu beberapa saat, pengguna dapat melihat halaman tersebut sebelum ditutup secara permanen.
Untuk Python:
Penulis naskah drama untuk Python menawarkan API sinkron dan asinkron. Contoh berikut menunjukkan cara kerja API asinkron:
from playwright.async_api import async_playwright
import asyncio
async def main():
# Initialize Playwright asynchronously
async with async_playwright() as p:
# Launch a Chromium browser instance with headless mode disabled
browser = await p.chromium.launch(headless=False)
# Create a new context within the browser to isolate browsing session
context = await browser.new_context()
# Create a new page/tab within the context
page = await context.new_page()
# Navigate to the GitHub topics homepage
await page.goto('<https://github.com/topics>')
# Wait for 1 second to ensure page content loads properly
await page.wait_for_timeout(1000)
# Close the browser instance after task completion
await browser.close()
# Run the main function asynchronously
asyncio.run(main())Baik kode Node.js maupun Python memiliki kesamaan, namun ada beberapa perbedaan utama. Python menggunakan perpustakaan Asyncio untuk operasi asinkron. Selain itu, konvensi penamaan fungsi berbeda, dengan Python menggunakan “snake_case” (mis. wait_for_timeout) dan JavaScript dengan camelCase (mis. waitForTimeout).
Contoh berikut menunjukkan cara kerja API sinkron:
from playwright.sync_api import sync_playwright
def main():
# Initialize Playwright synchronously
with sync_playwright() as p:
# Launch a Chromium browser instance with headless mode disabled
browser = p.chromium.launch(headless=False)
# Create a new context within the browser to isolate browsing session
context = browser.new_context()
# Create a new page/tab within the context
page = context.new_page()
# Navigate to the GitHub topics homepage
page.goto('<https://github.com/topics>')
# Wait for 1 second to ensure page content loads properly
page.wait_for_timeout(1000)
# Close the browser instance after task completion
browser.close()
if __name__ == '__main__':
main()Kode Node.js dan Python di atas membuka halaman berikut.
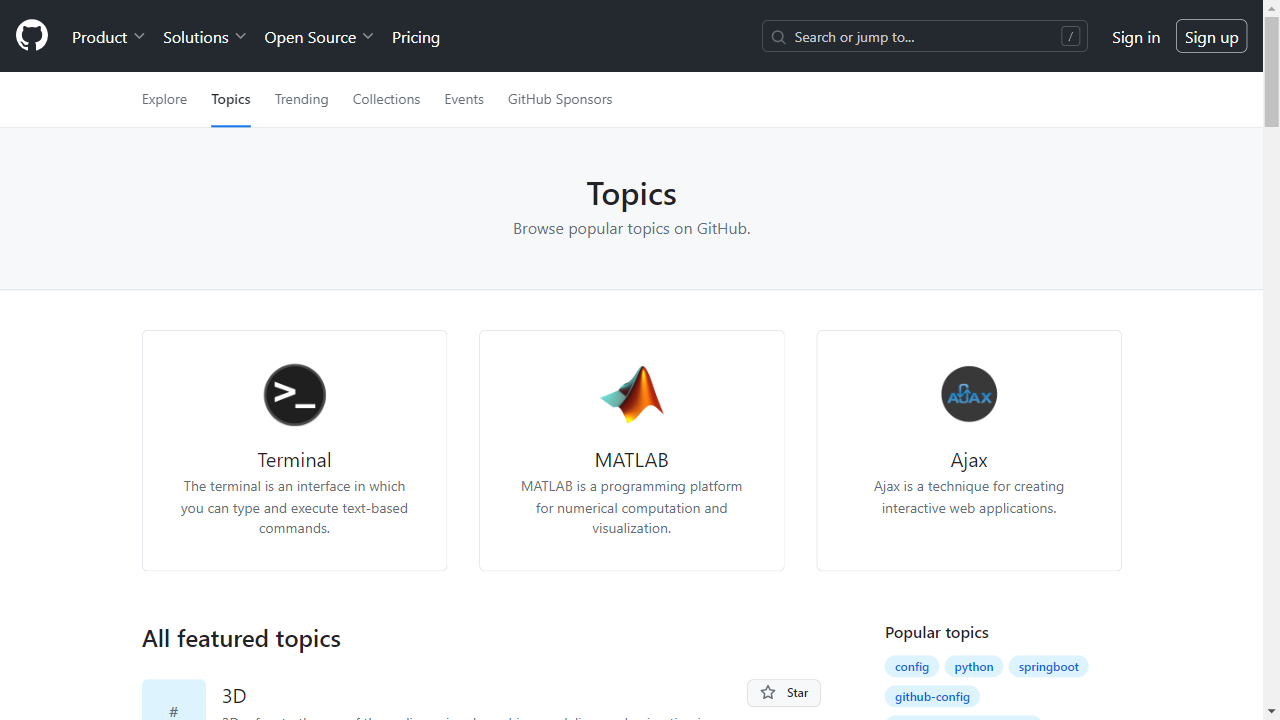
Goresan dasar dengan penulis naskah
Sekarang lingkungan Anda sudah siap, mari selami beberapa web scraping dasar dengan Playwright. Anda dapat melakukan semua hal yang biasa Anda lakukan secara manual di browser, mulai dari mengambil tangkapan layar hingga merayapi beberapa halaman.
Memilih data yang akan dikikis
Kami akan mengekstrak data dari topik GitHub. Ini memungkinkan Anda memilih topik dan jumlah repositori yang ingin Anda ekstrak. Scraper kemudian mengembalikan informasi yang terkait dengan topik yang dipilih.
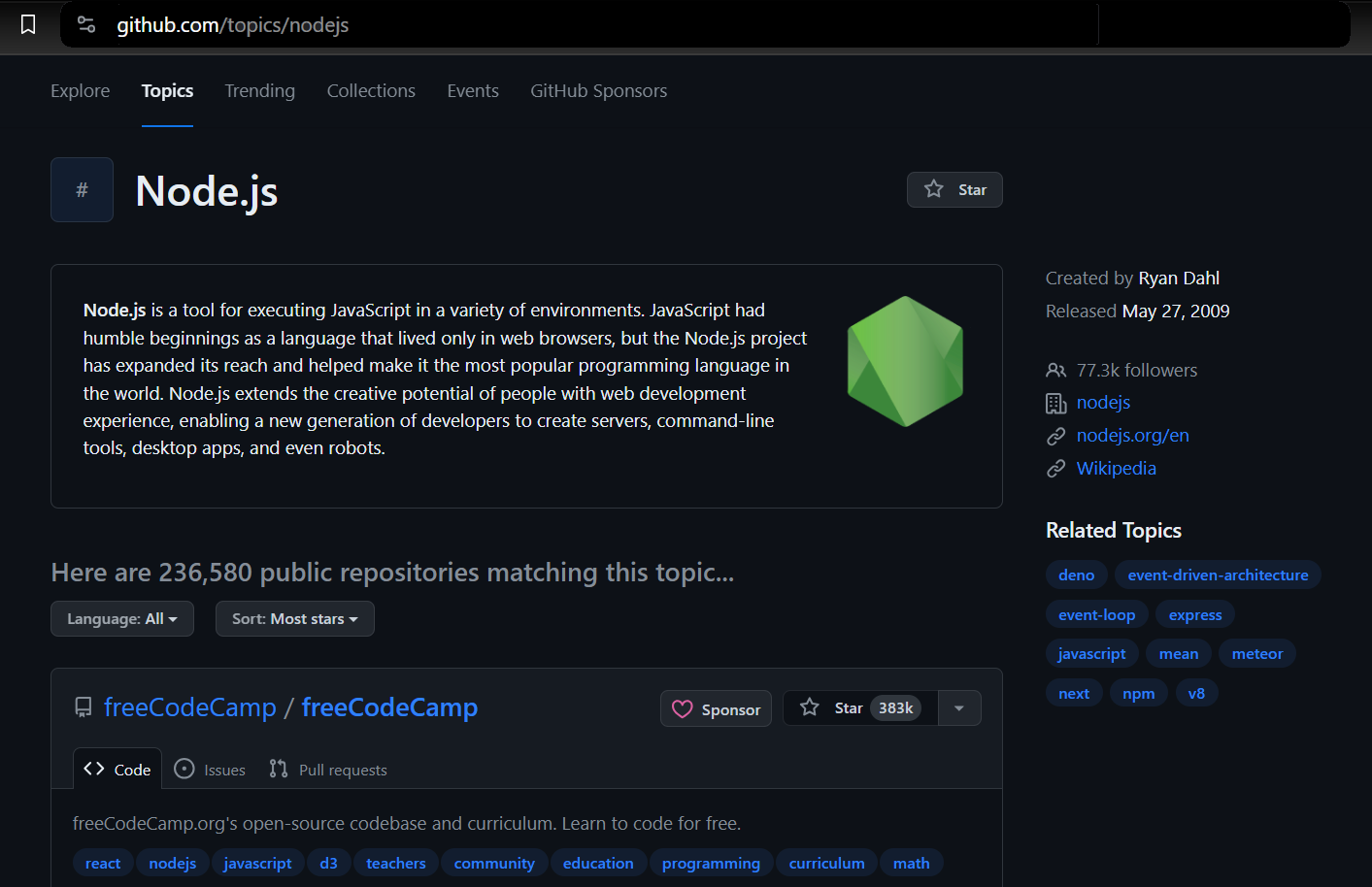
Kami menggunakan Penulis Drama untuk meluncurkan browser, menavigasi ke halaman topik GitHub, dan mengekstrak informasi yang diperlukan. Ini mencakup detail seperti pemilik repositori, nama repositori, URL repositori, jumlah bintang repositori, deskripsinya, dan semua tag terkait.
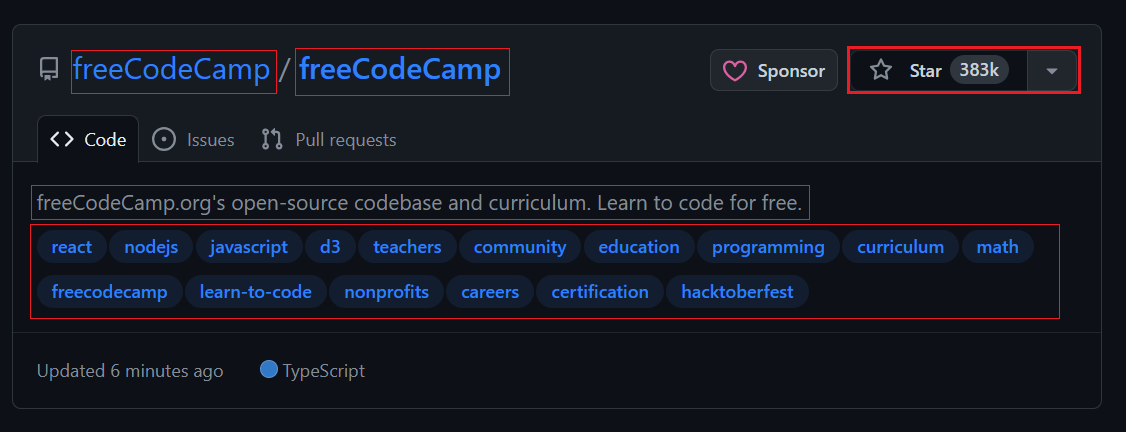
Menemukan item dan mengekstraksi data
Saat Anda membuka halaman topik, Anda akan melihat 20 repositori. Setiap entri ditampilkan sebagai <article> -Elemen menampilkan informasi tentang repositori tertentu. Anda dapat memperluas setiap item untuk melihat informasi lebih rinci tentang repositori terkait.
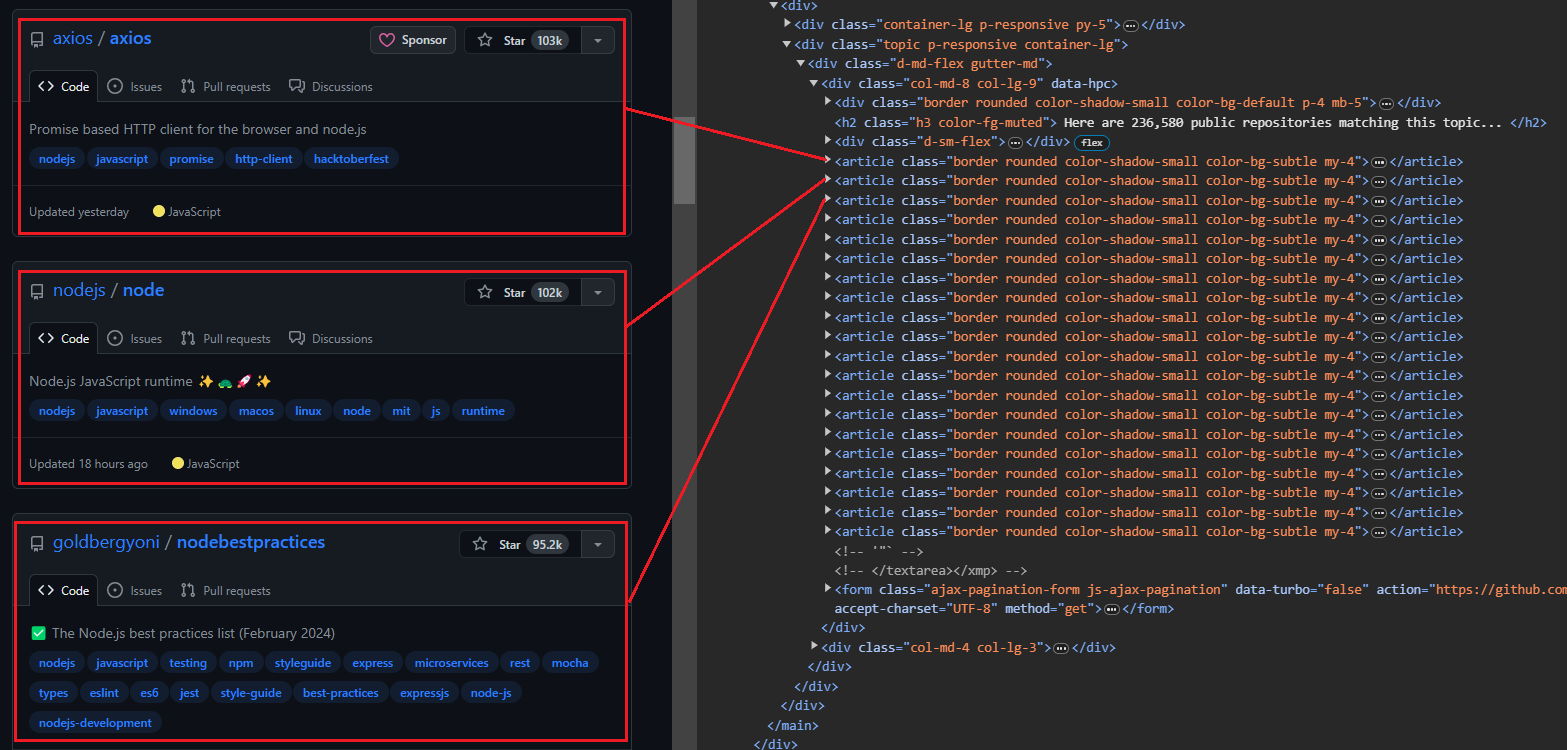
Gambar di bawah menunjukkan tampilan yang diperluas <article> Elemen yang menampilkan semua informasi tentang repositori.
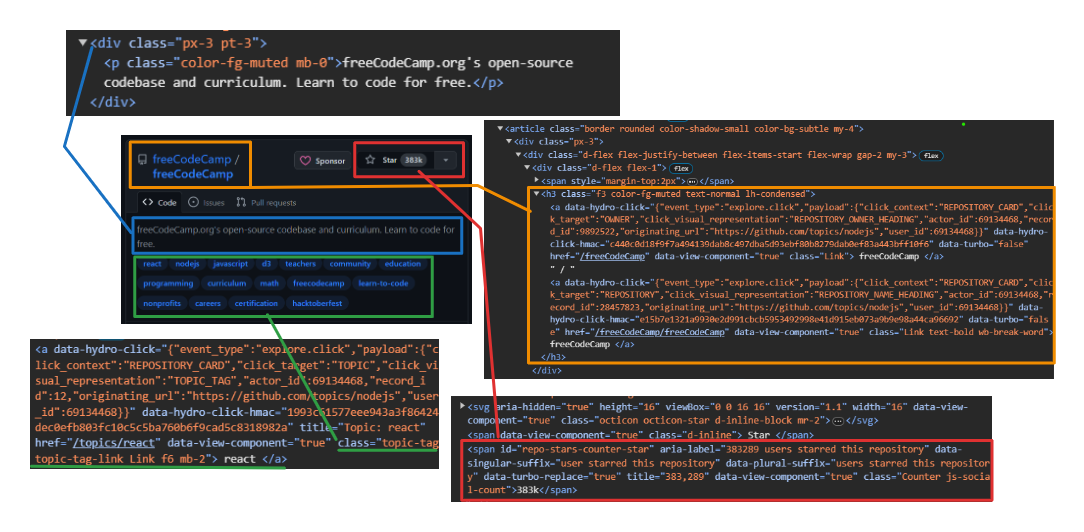
Mengekstraksi informasi pengguna dan repositori:
- Pengguna: Gunakan
h3 > a:first-childuntuk mengatasi tag jangkar pertama secara langsung di dalam a<h3>Label. - Nama Repositori: Menargetkan anak kedua di dalamnya
<h3>Induk. Anak ini berisi nama dan URL. Gunakan itutextContentProperti untuk mengekstrak nama dangetAttribute('href')Metode untuk mengekstrak URL. - Jumlah bintang: penggunaan
#repo-stars-counter-staruntuk memilih elemen dan mengekstrak nomor sebenarnya darinyatitleAtribut. - Deskripsi Repositori: Penggunaan
div.px-3 > puntuk memilih paragraf pertama dalam adivdengan kelaspx-3. - Tag repositori: Penggunaan
a.topic-taguntuk memilih semua tag jangkar dengan kelastopic-tag.
Fitur umum:
Untuk menggunakan penyeleksi di atas secara efektif, berikut adalah fitur umumnya:
$$eval(selector, function): Fungsi ini memilih semua elemen yang cocokselectordan meneruskannya ke sebagai arrayfunction. Nilai kembalian dari fungsi tersebut kemudian dikembalikan.$eval(selector, function): Fungsi ini memilih elemen pertama yang cocok denganselectordan meneruskannya sebagai argumen kepadafunction. Nilai kembalian dari fungsi tersebut kemudian dikembalikan.querySelector(selector): Fungsi ini mengembalikan elemen pertama yang cocok denganselector.querySelectorAll(selector): Fungsi ini mengembalikan daftar semua elemen yang cocokselector.
Berikut cuplikan kodenya:
repos.forEach(repo => {
const user = repo.querySelector('h3 > a:first-child').textContent.trim();
const repoLink = repo.querySelector('h3 > a:nth-child(2)');
const repoName = repoLink.textContent.trim();
const repoUrl = repoLink.getAttribute('href');
const repoStar = repo.querySelector('#repo-stars-counter-star').getAttribute('title');
const repoDescription = repo.querySelector('div.px-3 > p').textContent.trim();
const tagsElements = Array.from(repo.querySelectorAll('a.topic-tag'));
const tags = tagsElements.map(tag => tag.textContent.trim());Mari kita lihat keseluruhan proses mengekstraksi semua repositori dari satu halaman.
Prosesnya dimulai dengan fungsi page.$$eval. Fungsi ini memilih semua elemen dengan kelas border dalam article Tandai dan teruskan sebagai array ke fungsi yang disediakan. Kami mendefinisikan semua variabel dan penyeleksi di dalam fungsi ini.
const extractedRepos = await page.$$eval('article.border', repos => { ... });Buat juga array kosong bernama repoData untuk menyimpan informasi yang diekstraksi.
const repoData = ();Iterasi melalui setiap elemen di repos Array untuk mengekstrak semua data yang relevan untuk setiap repositori menggunakan penyeleksi yang disediakan.
repos.forEach(repo => { ... });Terakhir, data yang diekstraksi untuk setiap repositori ditambahkan ke repoData Array, dan array dikembalikan.
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });Berikut adalah kode untuk semua langkah di atas.
const extractedRepos = await page.$$eval('article.border', repos => {
const repoData = ();
repos.forEach(repo => {
const user = repo.querySelector('h3 > a:first-child').textContent.trim();
const repoLink = repo.querySelector('h3 > a:nth-child(2)');
const repoName = repoLink.textContent.trim();
const repoUrl = repoLink.getAttribute('href');
const repoStar = repo.querySelector('#repo-stars-counter-star').getAttribute('title');
const repoDescription = repo.querySelector('div.px-3 > p').textContent.trim();
const tagsElements = Array.from(repo.querySelectorAll('a.topic-tag'));
const tags = tagsElements.map(tag => tag.textContent.trim());
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });
});
return repoData;
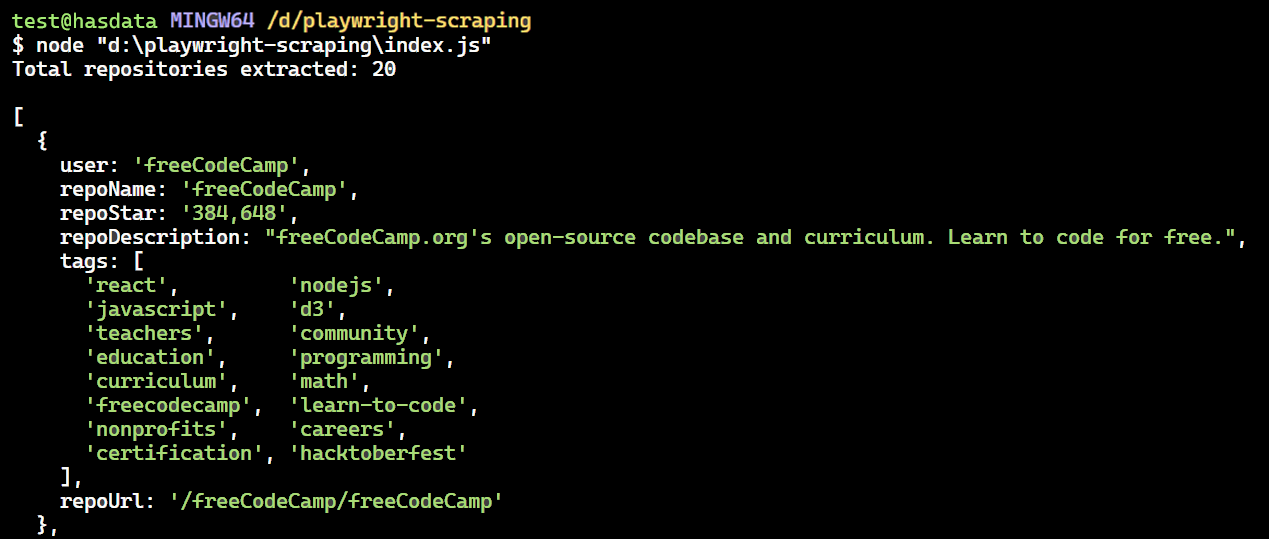
});Berikut kode lengkapnya. Menjalankan kode ini akan mengekstrak halaman pertama Topik GitHub.
import { chromium } from 'playwright';
(async () => {
// Launch a headless browser
const browser = await chromium.launch({ headless: true });
// Open a new page
const context = await browser.newContext();
const page = await context.newPage();
// Navigate to the Node.js topic page on GitHub
await page.goto('<https://github.com/topics/nodejs>');
const extractedRepos = await page.$$eval('article.border', repos => {
// Array to store extracted data
const repoData = ();
// Extract data from each repository element
repos.forEach(repo => {
const user = repo.querySelector('h3 > a:first-child').textContent.trim();
const repoLink = repo.querySelector('h3 > a:nth-child(2)');
const repoName = repoLink.textContent.trim();
const repoUrl = repoLink.getAttribute('href');
const repoStar = repo.querySelector('#repo-stars-counter-star').getAttribute('title');
const repoDescription = repo.querySelector('div.px-3 > p').textContent.trim();
const tagsElements = Array.from(repo.querySelectorAll('a.topic-tag'));
const tags = tagsElements.map(tag => tag.textContent.trim());
// Add extracted data to the array
repoData.push({ user, repoName, repoStar, repoDescription, tags, repoUrl });
});
// Return the extracted data
return repoData;
});
console.log(`Total repositories extracted: ${extractedRepos.length}\\n`);
// Print extracted data to the console
console.dir(extractedRepos, { depth: null }); // Show all nested data
// Close the browser
await browser.close();
})();Hasilnya adalah:
Jika Anda ingin mempelajari lebih lanjut tentang web scraping dengan Node.js selain Playwright, panduan komprehensif kami tentang web scraping dengan Node.js mungkin berguna bagi Anda. Artikel ini membahas pustaka dan teknik tambahan untuk meningkatkan kemampuan scraping Anda dengan Node.js
Teknik pengikisan tingkat lanjut
Kami telah berhasil menghapus satu halaman. Sekarang mari beralih ke pengikisan tingkat lanjut dengan Penulis Drama. Anda dapat mengeklik tombol, mengisi formulir, merayapi beberapa halaman, dan memutar header dan proxy untuk membuat pengikisan Anda lebih andal...
Klik tombol dan tunggu tindakan
Anda dapat memuat repositori tambahan dengan mengklik tombol “Muat Lebih Banyak…” di bagian bawah halaman. Berikut adalah tindakan untuk memberitahu Penulis Drama agar memuat lebih banyak repositori:
- Tunggu hingga tombol “Muat lebih banyak…” muncul.
- Klik tombol “Muat Lebih Banyak…”.
- Tunggu hingga repositori baru dimuat sebelum melanjutkan.
Mengklik tombol di Penulis Drama sangatlah mudah! Cukup masukkan pemilih CSS yang valid locator Metode yang secara efisien menemukan elemen pada halaman.
const button = await page.locator('button(type="submit").ajax-pagination-btn.f6');
await button.click();Dalam hal ini memang demikian page.locator() Metode ini mencari elemen tombol dengan atribut type="submit" dan kelas CSS ajax-pagination-btn Dan f6.
Menangani konten dan navigasi dinamis
Untuk mengikis beberapa halaman dengan Penulis Drama, Anda perlu mengklik tombol “Muat Lebih Banyak…” berulang kali hingga Anda mencapai bagian akhir. Namun, kita dapat menulis kode untuk mengotomatiskan proses ini dan mencari sejumlah repositori yang diinginkan. Misalnya, bayangkan ada 10.000 repositori nodejs dan Anda hanya ingin mengekstrak data untuk 1.000 repositori tersebut.
Berikut cara skrip meng-crawl beberapa halaman:
- Buka halaman topik nodejs di GitHub.
- Buat set kosong untuk menyimpan entri data repositori unik.
$$evalFitur ini mengekstrak data dari setiap repositori seperti nama pengguna, nama repositori, jumlah bintang, deskripsi, tag, dan URL.- Data yang diekstraksi hanya disimpan jika unik.
- Kode mencari “Halaman Berikutnya” menggunakan pencari lokasi tertentu. Jika tersedia, ia mengklik tombol untuk menuju ke halaman berikutnya dan mengulangi proses pengikisan.
- Jika tidak ada tombol yang ditemukan, perulangan berakhir.
- Akhirnya, browser yang dimulai ditutup.
Ini kodenya:
import { chromium } from 'playwright';
async function scrapeData(numRepos) {
const browser = await chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('<https://github.com/topics/nodejs>');
const uniqueRepos = new Set();
while (uniqueRepos.size < numRepos) {
const extractedData = await page.$$eval('article.border', repos => {
return repos.map(repo => {
const userLink = repo.querySelector('h3 > a:first-child');
const repoLink = repo.querySelector('h3 > a:last-child');
const user = userLink?.textContent.trim() || '';
const repoName = repoLink?.textContent.trim() || '';
const repoStar = repo.querySelector('#repo-stars-counter-star')?.title || '';
const repoDescription = repo.querySelector('div.px-3 > p')?.textContent.trim() || '';
const tags = Array.from(repo.querySelectorAll('a.topic-tag')).map(tag => tag.textContent.trim());
const repoUrl = repoLink?.href || '';
return { user, repoName, repoStar, repoDescription, tags, repoUrl };
});
});
extractedData.forEach(entry => uniqueRepos.add(JSON.stringify(entry)));
if (uniqueRepos.size >= numRepos) {
break;
}
const button = await page.locator('button(type="submit").ajax-pagination-btn.f6');
if (!button) {
console.log('Pagination button not found. All data scraped.');
break;
}
await button.click();
await page.waitForLoadState('networkidle');
}
const uniqueList = Array.from(uniqueRepos).slice(0, numRepos).map(entry => JSON.parse(entry));
console.dir(uniqueList, { depth: null });
await browser.close();
}
scrapeData(30);Berurusan dengan kesalahan
Beberapa kesalahan dapat terjadi saat melakukan scraping halaman web karena berbagai faktor, termasuk kesalahan manusia seperti menentukan URL yang tidak berfungsi atau gagal mengklik tombol. Selain itu, elemen data target mungkin hilang dari halaman, misalnya, repositori kode mungkin tidak memiliki deskripsi atau bintang.
Untungnya, ada strategi untuk menghadapi tantangan ini. Varian yang umum adalah menggunakan try/catch Blok. Blok ini memungkinkan Anda menangani kesalahan dengan lancar seperti navigasi halaman yang gagal atau batas waktu habis, mencegah kode Anda mogok dan memungkinkan eksekusi lanjutan.
Berikut kode lengkap dengan penanganan error dan kasus edge:
import { chromium } from 'playwright';
async function scrapeData(numRepos) {
let browser;
try {
browser = await chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('<https://github.com/topics/nodejs>');
const uniqueRepos = new Set();
while (uniqueRepos.size < numRepos) {
const extractedData = await page.$$eval('article.border', repos => {
return repos.map(repo => {
const userLink = repo.querySelector('h3 > a:first-child');
const repoLink = repo.querySelector('h3 > a:last-child');
const user = userLink?.textContent.trim() || '';
const repoName = repoLink?.textContent.trim() || '';
const repoStar = repo.querySelector('#repo-stars-counter-star')?.title || '';
const repoDescription = repo.querySelector('div.px-3 > p')?.textContent.trim() || '';
const tags = Array.from(repo.querySelectorAll('a.topic-tag')).map(tag => tag.textContent.trim());
const repoUrl = repoLink?.href || '';
return { user, repoName, repoStar, repoDescription, tags, repoUrl };
});
});
if (extractedData.length === 0) {
console.log('No articles found on this page.');
break;
}
extractedData.forEach(entry => uniqueRepos.add(JSON.stringify(entry)));
if (uniqueRepos.size >= numRepos) {
break;
}
const button = await page.locator('button(type="submit").ajax-pagination-btn.f6');
if (!button) {
console.log('Next button not found. All data scraped.');
break;
}
await button.click();
await page.waitForLoadState('networkidle');
}
const uniqueList = Array.from(uniqueRepos).slice(0, numRepos).map(entry => JSON.parse(entry));
console.dir(uniqueList, { depth: null });
} catch (error) {
console.error('Error during scraping:', error);
} finally {
if (browser) {
await browser.close();
}
}
}
scrapeData(30).catch(error => console.error('Unhandled error:', error));Menggunakan Proxy dengan Penulis Drama
Mengikis data dari situs web terkadang merupakan tantangan. Situs web mungkin membatasi akses berdasarkan lokasi Anda atau memblokir alamat IP Anda. Di sinilah proxy berperan. Proxy membantu melewati batasan ini dengan menyembunyikan alamat IP dan lokasi asli Anda.
Pertama, dapatkan proxy Anda dari daftar proxy gratis. Kemudian tambahkan objek proxy ke opsi startup browser Anda. Diatur di objek proxy server parameter untuk Anda proxyUrl. Terakhir, mulai browser dengan menelepon chromium.launch Fungsi, penyediaan launchOptions Objek yang baru saja Anda definisikan.
import { chromium } from 'playwright';
const proxyUrl="<http://20.210.113.32:80>";
const launchOptions = {
proxy: {
server: proxyUrl
}
};
(async () => {
const browser = await chromium.launch(launchOptions);
const page = await browser.newPage();
await page.goto('<http://httpbin.org/ip>');
const pageContent = await page.textContent('body');
console.log(pageContent);
})();Hasilnya adalah:
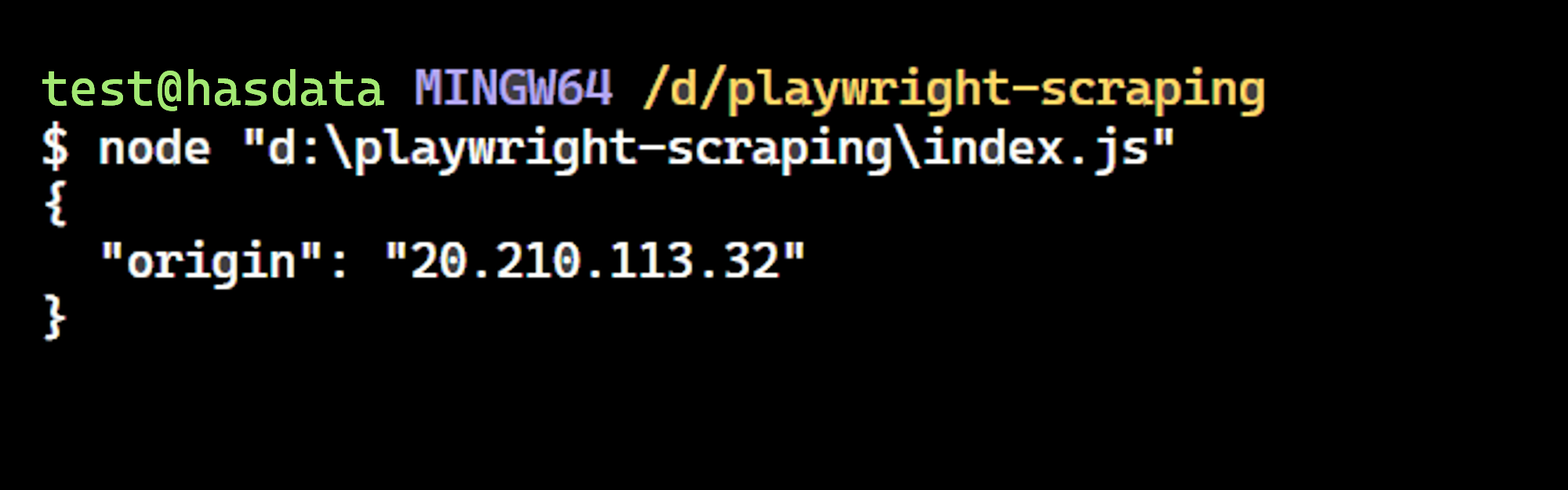
Kita berhasil! Alamat IP cocok dengan yang ada di situs web dan mengonfirmasi bahwa Penulis Drama menggunakan proxy yang ditentukan.
catatan: Proksi gratis tidak disarankan karena tidak dapat diandalkan. Secara khusus, umurnya yang pendek membuat mereka tidak cocok untuk skenario dunia nyata.
Mencegat permintaan HTTP
Playwright memungkinkan Anda memantau dan mengubah lalu lintas jaringan dengan mudah seperti permintaan HTTP dan HTTPS, XMLHttpRequests (XHRs), dan permintaan polling. Di bawah ini cuplikan kode yang menunjukkan cara mengubah header permintaan.
import { chromium } from 'playwright';
(async () => {
const browser = await chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
await page.route('<https://httpbin.org/headers>', (route, request) => {
// Get original headers
const originalHeaders = request.headers();
// Modify the Accept-Language and User-Agent headers
const modifiedHeaders = { ...originalHeaders };
modifiedHeaders('accept-language') = 'fr-FR'; // Change to French
modifiedHeaders('user-agent') = 'Mozilla/5.0 (Windows Phone 10.0; Android 4.2.1; Microsoft; RM-1127_16056) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Mobile Safari/537.36 Edge/12.10536';
// Continue the request with modified headers
route.continue({
headers: modifiedHeaders,
});
});
// Make the request with modified headers
await page.goto('<https://httpbin.org/headers>');
// Extract the data to see if the fields are updated
const response = await page.evaluate(() => {
return JSON.parse(document.querySelector('pre').textContent);
});
console.log('Response:', response);
await browser.close();
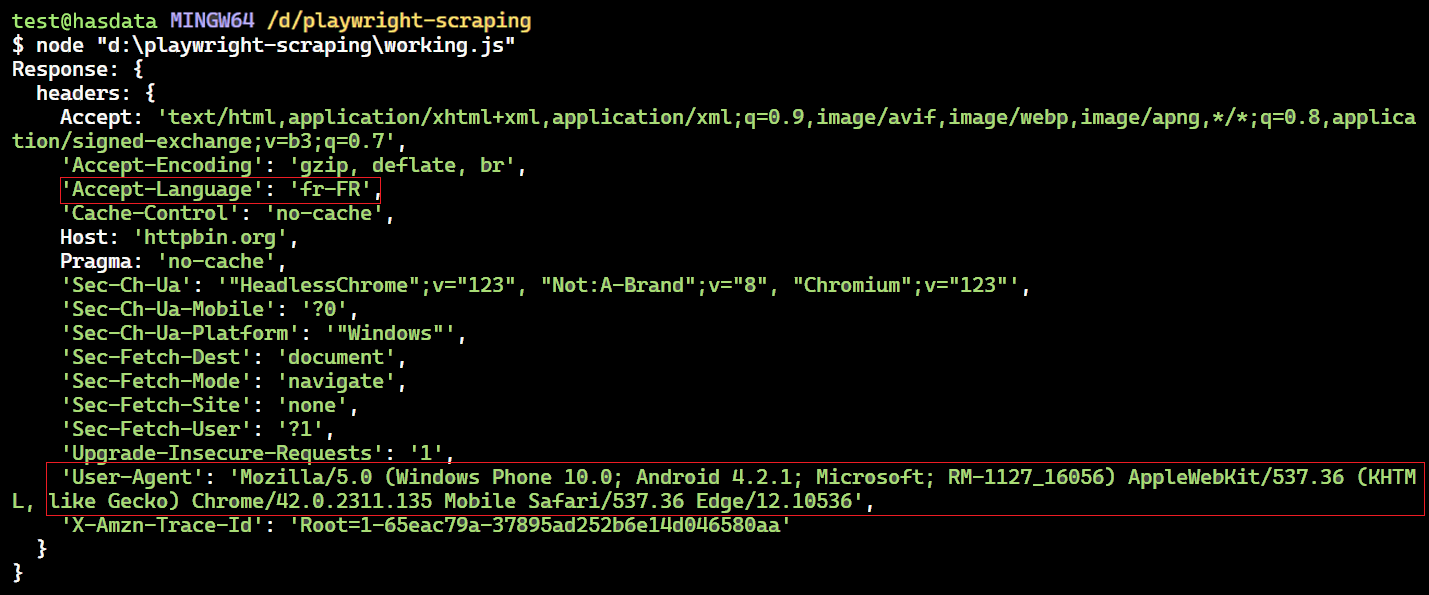
})();Kode ini menyiapkan pengendali rute untuk URL https://httpbin.org/headers. Pengendali ini mencegat permintaan dan memodifikasi header tertentu seperti “Bahasa Terima” dan “Agen Pengguna” sebelum mengirimkannya.
Ini diubah dalam fungsi handler Accept-Language Header juga 'fr-FR' (Perancis) dan User-Agent juga tajuknya. Setelah perubahan ini, handler melanjutkan permintaan dengan header yang diperbarui route.continue().
Header asli - kunjungi https://httpbin.org/headers untuk melihat header asli.
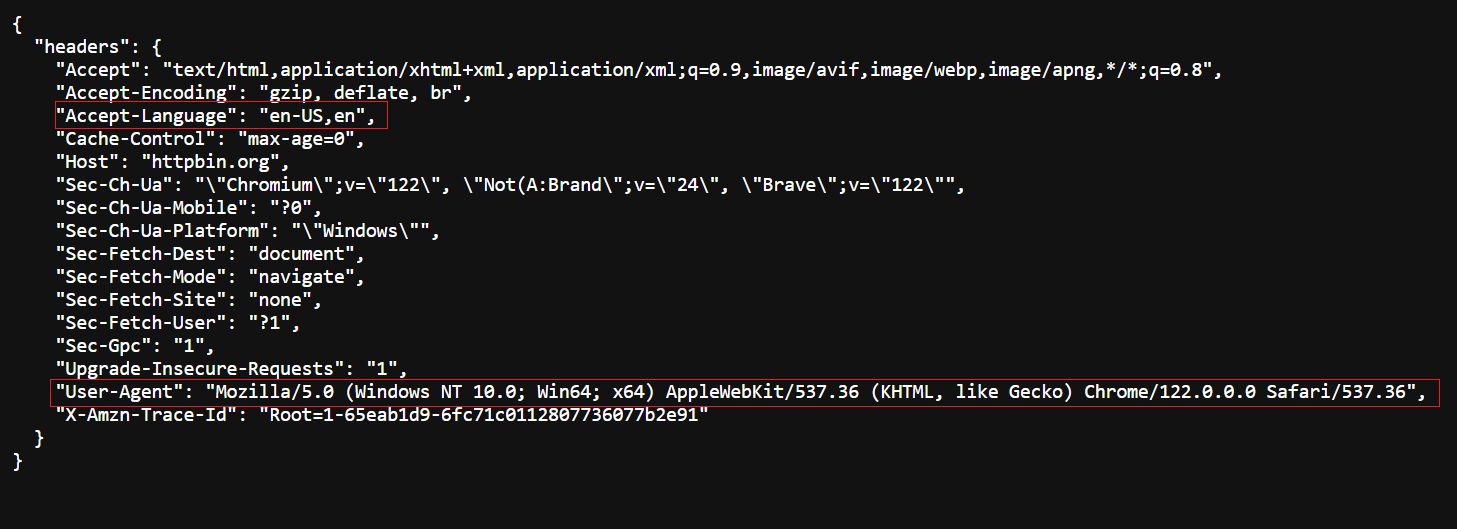
Header yang dimodifikasi - dikembalikan oleh kode kami.
Mengisi formulir
Mengisi dan mengirimkan formulir menjadi mudah dengan Penulis Drama. Anda hanya perlu meneruskan penyeleksi ke .fill() Berfungsi untuk mengisi nilai pada kolom input seperti username dan password. Kemudian gunakan itu .click() Berfungsi untuk mengirimkan formulir.
Mari kita lihat aksinya dengan masuk ke akun Reddit kami menggunakan Playwright.
import { chromium } from 'playwright';
(async () => {
const browser = await chromium.launch({ headless: true });
const page = await browser.newPage();
await page.goto('<https://reddit.com/login>');
await page.fill('input(name="username")', "satyamtri");
await page.fill('input(name="password")', "<secret-password>");
await page.click('.login');
await page.waitForNavigation();
await page.screenshot({
path: "reddit.png",
fullPage: false
});
await browser.close();
})();Hasilnya adalah:
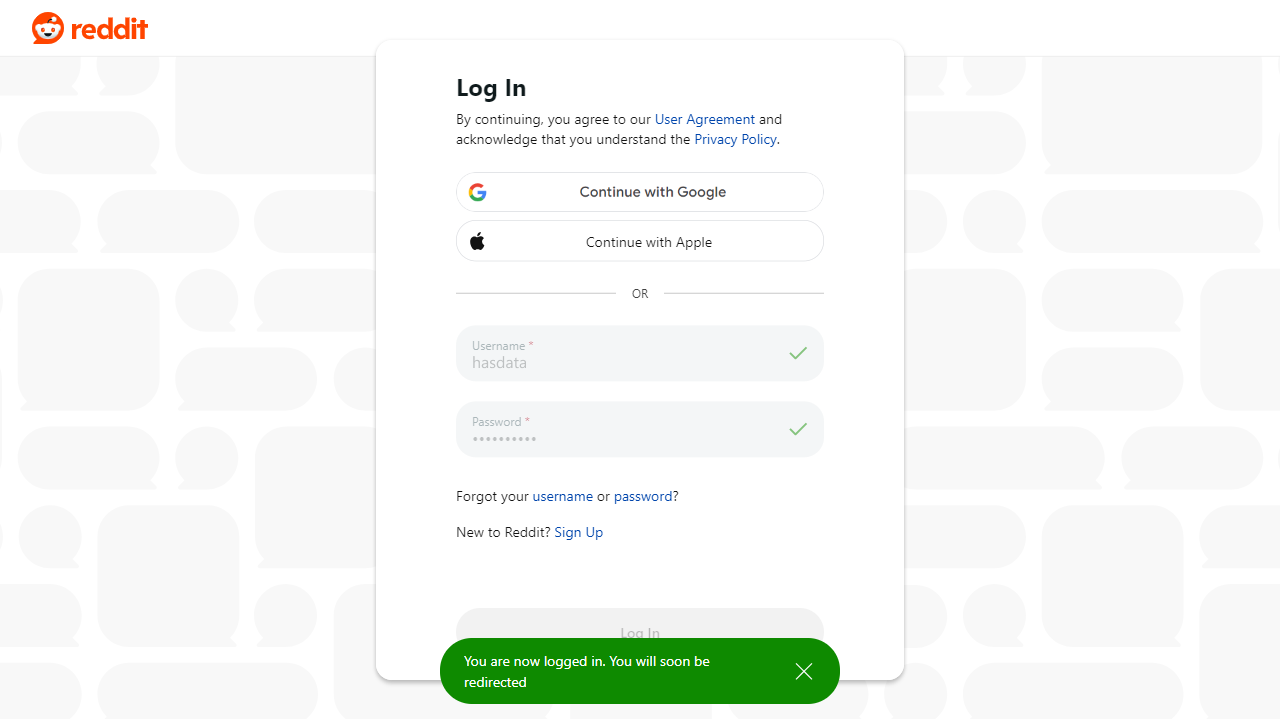
Tangkapan layar halaman web
Penulis naskah memungkinkan Anda mengambil tangkapan layar halaman web. Fitur ini berharga untuk tinjauan visual karena memungkinkan Anda mengambil cuplikan kapan saja.
import { chromium } from 'playwright';
async function screenShot() {
const browser = await chromium.launch({
headless: true
});
const context = await browser.newContext();
const page = await context.newPage();
await page.setViewportSize({ width: 1280, height: 800 }); // set screenshot dimension
await page.goto('<https://github.com/topics/nodejs>')
await page.screenshot({ path: 'images/screenshot.png' })
await browser.close()
}
screenShot();Hasilnya adalah:
Untuk menangkap seluruh halaman, atur fullPage properti ke true. Anda juga dapat mengubah format gambar jpg atau jpeg untuk menyimpan dalam format yang berbeda.
await page.screenshot({ path: 'images/screenshot.jpg', fullPage: true });Untuk menangkap area tertentu pada halaman web, gunakan clip Properti. Ini memerlukan definisi empat nilai:
x: Jarak horizontal dari sudut kiri atas area deteksi.y: Jarak vertikal dari sudut kiri atas area deteksi.width: Lebar area deteksi.height: Ketinggian area deteksi.
await page.screenshot({
path: "images/screenshot.png", fullPage: false, clip: {
x: 5,
y: 5,
width: 320,
height: 160
}
});Hasilnya adalah:
Simpan data yang tergores ke Excel
Mengesankan! Kami telah berhasil menghapus data. Mari simpan ke file Excel alih-alih mencetaknya ke konsol.
Kami akan menggunakannya exceljs Paket untuk menulis data ke file Excel. Namun sebelum Anda melakukannya, instal menggunakan perintah berikut:
npm install exceljsBerikut cuplikan kode untuk menyimpan data ke file Excel:
const workbook = new ExcelJS.Workbook();
const sheet = workbook.addWorksheet('GitHub Repositories');
sheet.columns = (
{ header: 'User', key: 'user' },
{ header: 'Repository Name', key: 'repoName' },
{ header: 'Stars', key: 'repoStar' },
{ header: 'Description', key: 'repoDescription' },
{ header: 'Repository URL', key: 'repoUrl' },
{ header: 'Tags', key: 'tags' }
);
uniqueList.forEach(entry => {
sheet.addRow(entry);
});
await workbook.xlsx.writeFile('github_repos.xlsx');Cuplikan kode menggunakan beberapa fungsi:
new ExcelJS.Workbook(): Membuat objek buku kerja ExcelJS baru.workbook.addWorksheet('GitHub Repositories'): Menambahkan lembar kerja baru bernama “Repositori GitHub” ke buku kerja.sheet.columns: Mendefinisikan kolom di lembar kerja. Setiap objek kolom menentukan header dan kunci untuk kolom tersebut.sheet.addRow(entry): Menambahkan baris data dari objek Entry ke lembar kerja (mewakili data untuk satu baris).workbook.xlsx.writeFile('github_repos.xlsx'): Menulis buku kerja ke file bernama “github_repos.xlsx” dalam format XLSX.
Kode lengkapnya:
import { chromium } from 'playwright';
import ExcelJS from 'exceljs';
async function scrapeData(numRepos) {
let browser;
try {
browser = await chromium.launch({ headless: true });
const context = await browser.newContext();
const page = await context.newPage();
await page.goto('<https://github.com/topics/nodejs>');
const uniqueRepos = new Set();
while (uniqueRepos.size < numRepos) {
const extractedData = await page.$$eval('article.border', repos => {
return repos.map(repo => {
const userLink = repo.querySelector('h3 > a:first-child');
const repoLink = repo.querySelector('h3 > a:last-child');
const user = userLink?.textContent.trim() || '';
const repoName = repoLink?.textContent.trim() || '';
const repoStar = repo.querySelector('#repo-stars-counter-star')?.title || '';
const repoDescription = repo.querySelector('div.px-3 > p')?.textContent.trim() || '';
const tags = Array.from(repo.querySelectorAll('a.topic-tag')).map(tag => tag.textContent.trim());
const repoUrl = repoLink?.href || '';
return { user, repoName, repoStar, repoDescription, tags, repoUrl };
});
});
if (extractedData.length === 0) {
console.log('No articles found on this page.');
break;
}
extractedData.forEach(entry => uniqueRepos.add(JSON.stringify(entry)));
if (uniqueRepos.size >= numRepos) {
break;
}
const button = await page.locator('button(type="submit").ajax-pagination-btn.f6');
if (!button) {
console.log('Next button not found. All data scraped.');
break;
}
await button.click();
await page.waitForLoadState('networkidle');
}
const uniqueList = Array.from(uniqueRepos).slice(0, numRepos).map(entry => JSON.parse(entry));
// Save data to Excel file
const workbook = new ExcelJS.Workbook();
const sheet = workbook.addWorksheet('GitHub Repositories');
sheet.columns = (
{ header: 'User', key: 'user' },
{ header: 'Repository Name', key: 'repoName' },
{ header: 'Stars', key: 'repoStar' },
{ header: 'Description', key: 'repoDescription' },
{ header: 'Repository URL', key: 'repoUrl' },
{ header: 'Tags', key: 'tags' }
);
uniqueList.forEach(entry => {
sheet.addRow(entry);
});
await workbook.xlsx.writeFile('github_repos.xlsx');
console.log('Data saved to excel file.');
} catch (error) {
console.error('Error during scraping:', error);
} finally {
if (browser) {
await browser.close();
}
}
}
scrapeData(30).catch(error => console.error('Unhandled error:', error));Hasilnya adalah:

Alat lain seperti Selenium dan Puppeteer menawarkan fungsi serupa dengan Penulis Drama. Namun, setiap alat memiliki kelebihan dalam hal kecepatan eksekusi, pengalaman pengembang, dan dukungan komunitas.
Playwright menonjol karena kemampuannya berjalan mulus di berbagai browser (termasuk Chromium, WebKit, dan Firefox) menggunakan satu API. Ia juga memiliki dokumentasi yang luas dan mendukung berbagai bahasa pemrograman seperti Python, Node.js, Java dan .NET.
Meskipun Puppeteer juga ramah pengembang dan mudah diatur, ia terbatas pada browser JavaScript dan Chromium. Selenium, di sisi lain, menawarkan dukungan browser dan bahasa terlengkap, namun bisa lebih lambat dan kurang ramah pengguna.
Dalam hal kecepatan, Dalang umumnya berada di urutan teratas, diikuti oleh Penulis Drama (bahkan Penulis Drama mengungguli Dalang dalam beberapa kasus). Selenium tertinggal dalam kinerja.
Mari jelajahi tren NPM dan popularitas ketiga perpustakaan ini. Data menunjukkan bahwa adopsi Penulis Drama di kalangan pengembang semakin meningkat.
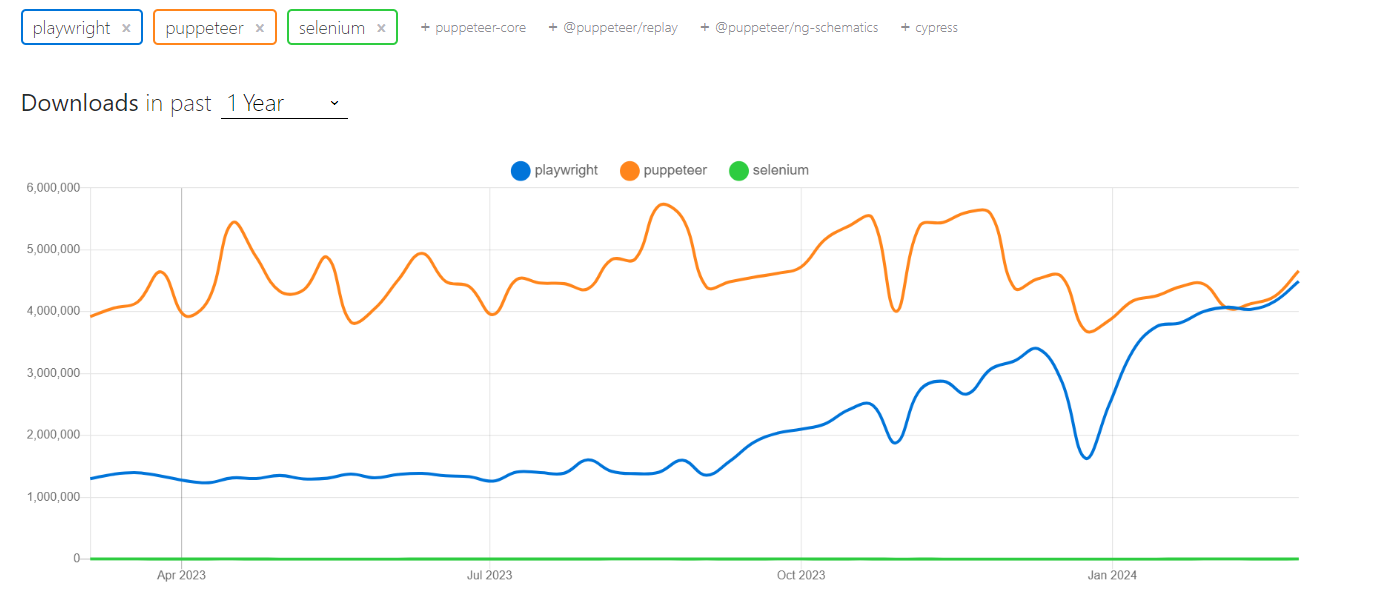
Mari kita lihat tabel perbandingannya:
| parameter | dramawan | Dalang | selenium |
|---|---|---|---|
| kecepatan | Cepat | Cepat | Lambat |
| dokumentasi | Bagus sekali | Bagus sekali | Hanya |
| Pengalaman pengembang | Lebih disukai | Bagus | Hanya |
| Dukungan bahasa | JavaScript, Python, C#, Jawa | JavaScript | Java, Python, C#, Ruby, JavaScript, Kotlin |
| Dari | Microsoft | Komunitas dan sponsor | |
| Masyarakat | Kecil tapi aktif | Besar dan aktif | Besar dan aktif |
| Dukungan peramban | Kromium, Firefox dan WebKit | krom | Chrome, Firefox, IE, Edge, Opera, Safari |
Diploma
Playwright menawarkan perangkat yang kuat dan serbaguna untuk tugas pengikisan web dengan dokumentasi yang sangat baik dan komunitas yang berkembang. Dengan memanfaatkan fitur-fiturnya, Anda dapat mengekstrak data berharga dari situs web secara efisien, mengotomatiskan interaksi browser yang berulang, dan menyederhanakan berbagai alur kerja.
Dalam panduan ini, kami fokus pada halaman topik GitHub, tempat Anda dapat memilih topik (misalnya NodeJS) dan menentukan jumlah repositori yang akan dikikis. Kami telah membahas cara menangani kesalahan dan kasus edge saat melakukan scraping, cara menggunakan proxy untuk menghindari deteksi, dan cara membandingkannya dengan Selenium dan Puppeteer.
Seiring bertambahnya pengalaman, Anda akan mempelajari teknik-teknik lanjutan secara mendetail, seperti: Seperti mengonfigurasi proxy, mencegat permintaan, mengelola cookie, dan memblokir sumber daya dan gambar yang tidak diperlukan. Anda dapat mempelajari lebih lanjut tentang Penulis Drama dengan mengunjungi dokumentasi resmi yang mudah dipahami dan mendetail.
