
Rust adalah bahasa pemrograman cepat yang mirip dengan C, cocok untuk membuat program sistem (driver dan sistem operasi) serta program biasa dan aplikasi web. Pilih Rust sebagai bahasa pemrograman untuk membuat web scraper jika Anda memerlukan kontrol yang lebih luas dan tingkat yang lebih rendah atas aplikasi Anda. Misalnya, jika Anda ingin melacak sumber daya yang digunakan, mengelola penyimpanan, dan lainnya.
Pada artikel ini, kita akan mengeksplorasi nuansa pembuatan web scraper yang efisien dengan Rust dan menyoroti kelebihan dan kekurangannya di bagian akhir. Baik Anda melacak perubahan data secara real time, melakukan riset pasar, atau sekadar mengumpulkan data untuk dianalisis, fitur Rust memungkinkan Anda membuat web scraper yang kuat dan andal.
Memulai dengan Rust
Untuk menginstal Rust, buka situs web resmi dan unduh distribusinya (untuk sistem operasi Windows) atau salin perintah instalasi (untuk Linux).
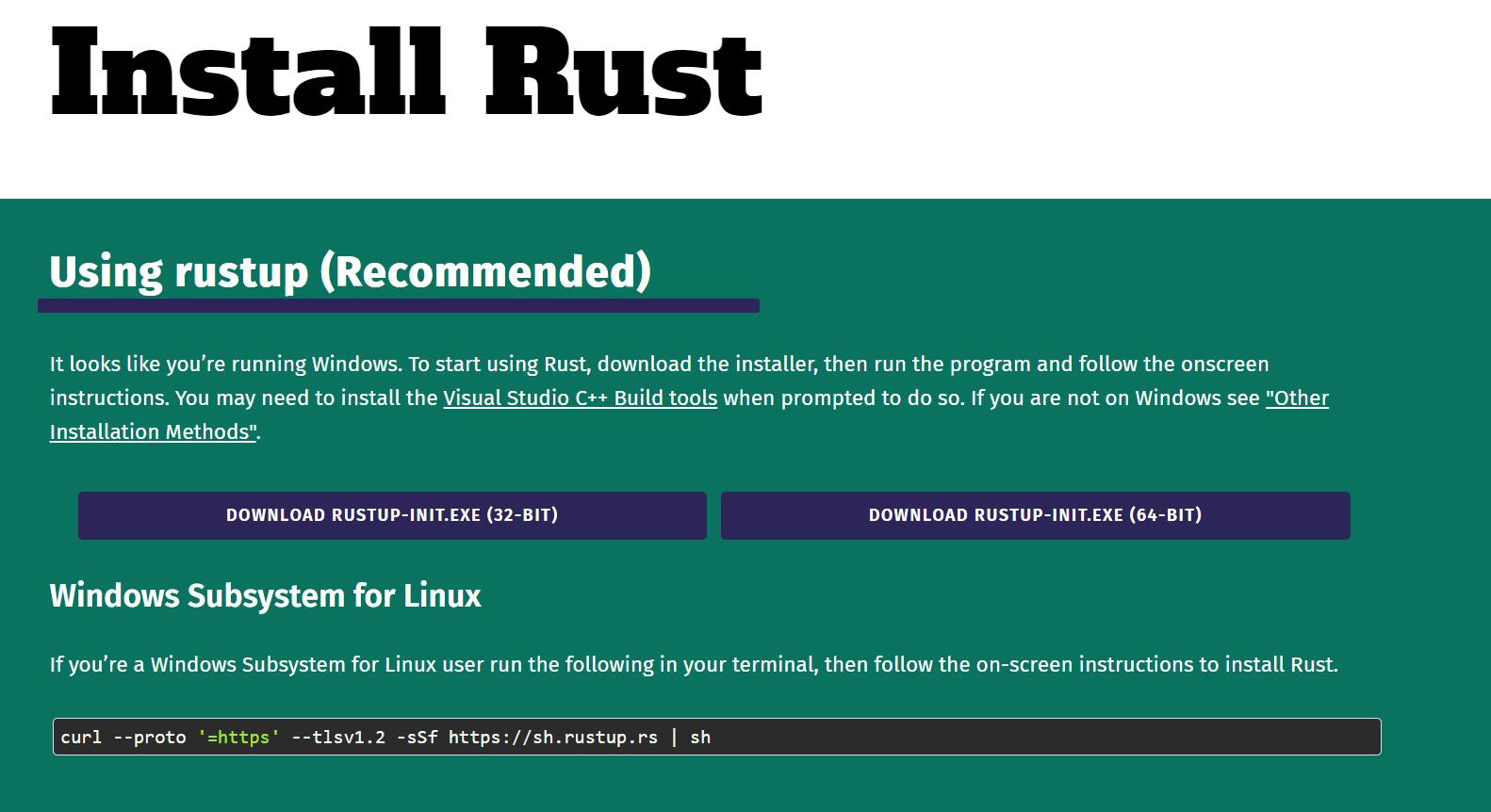
Saat Anda menjalankan file untuk Windows, prompt perintah terbuka dan penginstal menawarkan Anda pilihan salah satu dari tiga fitur:
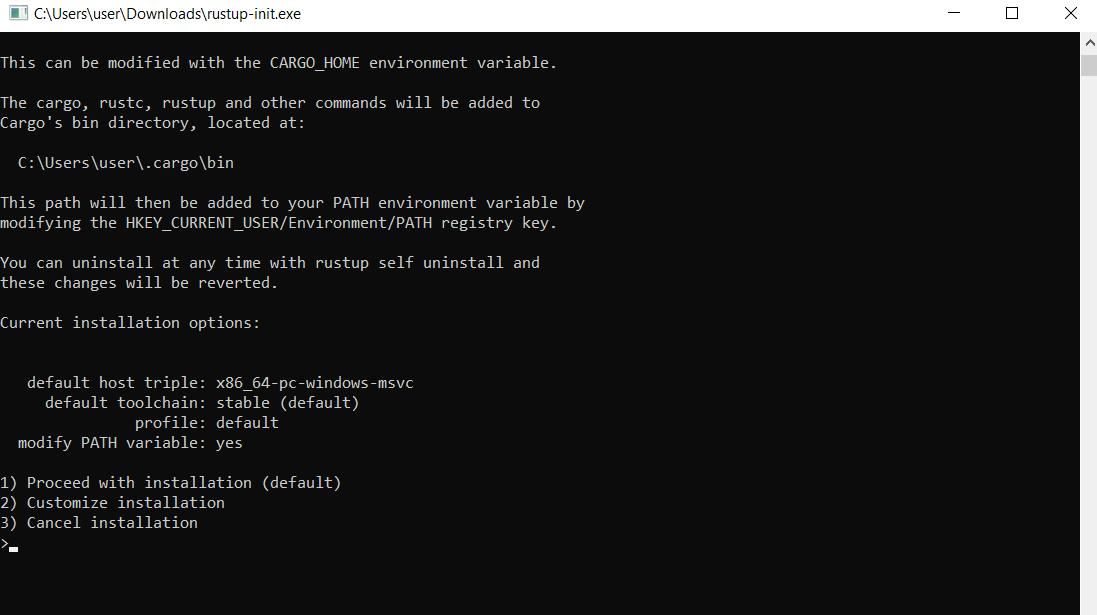
Karena kami tidak ingin mengonfigurasi dependensi secara manual, kami memilih opsi 1 untuk instalasi otomatis. Instalasi kemudian akan selesai dan Anda akan menerima pesan bahwa Rust dan semua komponen yang diperlukan telah berhasil diinstal.
Untuk menginstal komponen standar pada sistem Linux, masukkan perintah di terminal:
$ curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | shKemudian pilih poin 1 pada saat proses instalasi.
Anda juga dapat memperbarui Rust di terminal:
$ rustup updatePeriksa pembaruan:
$ rustc --versionDan hapus instalannya:
$ rustup self uninstallProses instalasi dan setup sudah selesai. Buat file baru dengan file RS untuk membuat skrip Rust. Anda juga dapat menggunakan Cargo, manajer paket Rust, untuk membuat proyek baru. Gunakan perintah ini:
cargo new project_nameSeperti biasa, kami menggunakan Visual Studio Code untuk menulis kodenya. Demi kenyamanan Anda, kami juga akan menggunakan plugin Rust Analyzer.
Tidak seperti Python, Rust memiliki sedikit perpustakaan scraping, tetapi yang paling populer adalah:
- Reqwest dan Scraper. Jalankan permintaan ke halaman web dan analisis hasilnya. Hanya cocok untuk halaman statis.
- Tanpa kepala_Chrome. Memungkinkan Anda menggunakan browser tanpa kepala dan mengotomatiskan tindakan pada halaman (pengisian formulir, klik, dll.). Ini memiliki fitur yang mirip dengan Puppeteer untuk NodeJS dan Selenium untuk Python.
Mari kita lihat lebih dekat.
Pertanyaan
Reqwest adalah perpustakaan asinkron yang sangat sederhana untuk bahasa pemrograman Rust untuk memproses permintaan HTTP. Ini menyediakan cara yang nyaman dan efisien untuk mengirim permintaan HTTP ke server jarak jauh dan memproses respons HTTP.
Untuk menggunakannya dalam proyek Anda, Anda perlu menginstal ketergantungan:
cargo add reqwest --features "reqwest/blocking"Kemudian Anda dapat menggunakannya dalam proyek Anda dan mengonfigurasi berbagai aspek persyaratan seperti: Misalnya header, parameter, dan otorisasi.
pengikis
Pustaka Rust ini, tidak seperti yang sebelumnya, tidak dapat menjalankan permintaan. Namun, ini bagus dalam mengambil data dari dokumen XML dan HTML. Oleh karena itu, perpustakaan ini biasanya digunakan bersama-sama.
Untuk menghubungkan bagian-bagian yang diperlukan dan menggunakan perpustakaan dalam proyek Rust, gunakan perintah ini:
cargo add scraperKemudian Anda dapat mengurai dokumen HTML yang Anda perlukan menggunakan pemilih CSS.
Tanpa kepala_Chrome
Dan perpustakaan terakhir adalah “headless_chrome” untuk Rust. Ia bekerja dengan browser Chrome dalam mode "tanpa kepala" untuk pengikisan dan otomatisasi web. Untuk menggunakannya, sambungkan dependensi dengan perintah berikut:
cargo add headless_chromePustaka Rust “headless_chrome” memungkinkan Anda mengontrol browser Chrome melalui protokol DevTools. Ini menyediakan antarmuka Rust untuk mengirimkan perintah ke browser, seperti memuat halaman web, menjalankan JavaScript, mensimulasikan peristiwa, dan banyak lagi.
Pengikisan web dasar di Rust
Untuk membuat perpustakaan lebih mudah digunakan, mari kita lihat contoh sederhana melakukan scraping dengan perpustakaan. Sebagai contoh, kita akan menelusuri situs demo OpenCart.
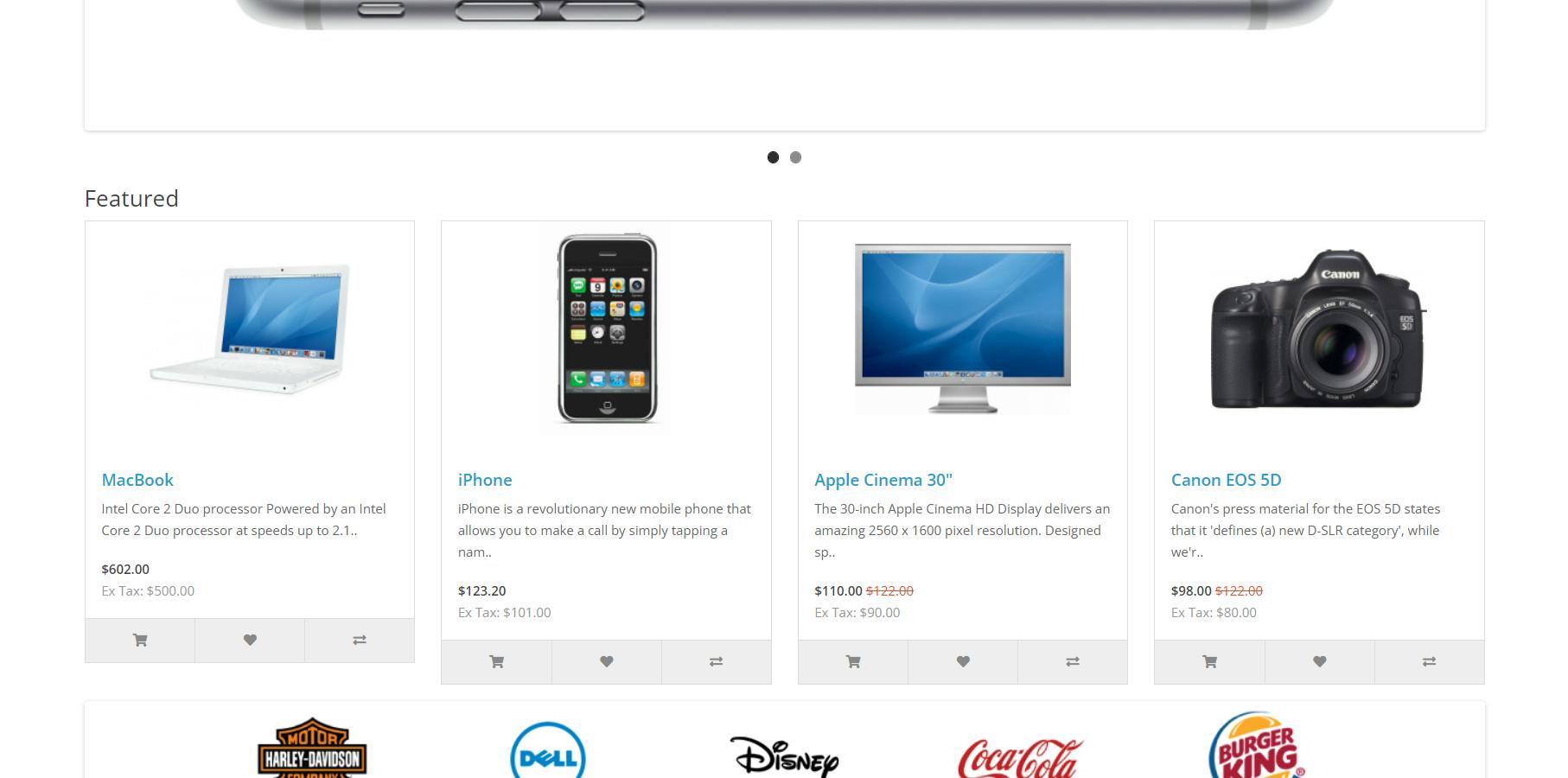
Kami telah membahas item di halaman ini sehingga kami tidak perlu membahasnya lagi.
Buat permintaan HTTP
Kami akan bekerja dengan file yang secara otomatis dibuat dengan "cargo new project_name". File main.rs terletak di folder proyek di subfolder src. Ini segera dihasilkan dengan fungsi contoh untuk menampilkan “Halo Dunia!”
Untuk web scraper, kami menggunakan fungsi yang dibuat secara otomatis untuk menulis kode Rust scraper kami.
fn main() {
// Here will be code
}Pertama, mari kita mulai dengan mendapatkan kode HTML websitenya. Gunakan perintah ini untuk mengirim permintaan:
let response = reqwest::blocking::get("https://demo.opencart.com/");Dan kemudian ini untuk mengekstrak jawaban yang dihasilkan:
let data = response.unwrap().text().unwrap();Jika Anda ingin menguji cara kerjanya, tambahkan perintah keluaran layar:
println!("{data}");Untuk membangun dan menjalankan proyek, gunakan perintah berikut pada prompt perintah:
cargo build
cargo runRuntime memberi Anda semua kode HTML halaman.
Parsing dokumen HTML
Untuk mengurai data, kami menggunakan perpustakaan Scraper dan kemampuannya untuk mengekstrak data menggunakan pemilih CSS. Untuk melakukan ini kita memerlukan struktur dan array untuk menyimpan data:
struct DemoProduct {
image: Option<String>,
url: Option<String>,
title: Option<String>,
description: Option<String>,
new: Option<String>,
tax: Option<String>,
}
let mut demo_products: Vec<DemoProduct> = Vec::new();Kemudian gunakan metode “pilih” untuk mengekstrak informasi tentang semua produk:
let html_product_selector = scraper::Selector::parse("div.col").unwrap();
let html_products = document.select(&html_product_selector);Terakhir, mari kita lihat setiap produk dan gunakan pemilih CSS untuk menyimpan data elemen HTML yang kita butuhkan dalam sebuah array.
for html_product in html_products {
let image = html_product
.select(&scraper::Selector::parse(".image a").unwrap())
.next()
.and_then(|a| a.value().attr("href"))
.map(str::to_owned);
let url = html_product
.select(&scraper::Selector::parse("h4 a").unwrap())
.next()
.and_then(|a| a.value().attr("href"))
.map(str::to_owned);
let title = html_product
.select(&scraper::Selector::parse(".description h4").unwrap())
.next()
.map(|h4| h4.text().collect::<String>());
let description = html_product
.select(&scraper::Selector::parse(".description p").unwrap())
.next()
.map(|p| p.text().collect::<String>());
let new = html_product
.select(&scraper::Selector::parse(".price-new").unwrap())
.next()
.map(|price| price.text().collect::<String>());
let tax = html_product
.select(&scraper::Selector::parse(".price-tax").unwrap())
.next()
.map(|price| price.text().collect::<String>());
let demo_product = DemoProduct {
image,
url,
title,
description,
new,
tax,
};
demo_products.push(demo_product);
}Untuk menampilkan data ini di layar, Anda perlu menelusuri semua elemen lagi dan menampilkan seluruh array baris demi baris:
for (index, product) in demo_products.iter().enumerate() {
println!("Product #{}", index + 1);
println!("Image: {:?}", product.image);
println!("URL: {:?}", product.url);
println!("Title: {:?}", product.title);
println!("Description: {:?}", product.description);
println!("New Price: {:?}", product.new);
println!("Tax: {:?}", product.tax);
println!("-----------------------------");
}Namun, karena kami jarang perlu menampilkan data di layar, kami menyimpan data yang diperoleh dalam file CSV.
Simpan data yang tergores ke file CSV
Pustaka CSV tersedia untuk bekerja dengan file Excel. Untuk menginstalnya kami menggunakan Cargo:
cargo add csvSekarang mari kita kembali ke skrip kita. Tentukan jalur untuk menyimpan file dan kolom yang diperlukan.
let mut csv_writer = csv::Writer::from_path("products.csv").unwrap();
csv_writer.write_record(&("Image", "URL", "Title", "Description", "New Price", "Tax")).unwrap();Kemudian proses setiap elemen array baris demi baris dan masukkan ke dalam file:
for product in demo_products {
let image = product.image.unwrap();
let url = product.url.unwrap();
let title = product.title.unwrap();
let description = product.description.unwrap();
let new = product.new.unwrap();
let tax = product.tax.unwrap();
csv_writer.write_record(&(image, url, title, description, new, tax)).unwrap();
}Dan selesaikan pengerjaan file:
csv_writer.flush().unwrap();Anda dapat menggunakan println! dan cetak data tentang akhir skrip, atau Anda bisa menunggu eksekusinya. Hasilnya, Anda akan mendapatkan file dengan output sebagai berikut:

Selamat, Anda baru saja membuat web scraper klasik dengan Rust, memanfaatkan sepenuhnya keamanan dan kecepatan memori. Anda mempelajari cara membuat permintaan, mengurai dokumen HTML, dan bahkan menulis data yang diambil ke file CSV - semuanya dalam ekosistem Rust.
Namun, metode ini hanya cocok untuk situs statis dan tidak memungkinkan bekerja dengan konten dinamis. Selain itu, ada risiko pemblokiran yang sangat tinggi karena situs web dapat dengan mudah mendeteksi scraper Anda. Untuk mengatasi kesulitan ini, Anda dapat menggunakan browser tanpa kepala.
Berurusan dengan konten dinamis
Mari kita perluas contoh kita. Kami menggunakan perpustakaan yang menggunakan browser tanpa kepala untuk menavigasi ke halaman dan mengumpulkan data. Ini memecahkan beberapa masalah dan menghapus konten dinamis dari halaman.
Untuk menggunakan browser, Anda memerlukan perpustakaan yang sesuai, mis. Misalnya headless_chrome. Skripnya mirip dengan contoh pertama, hanya saja transisi ke halaman dan kumpulan kode HTML halaman ditangani oleh pustaka headless_chrome. Buat proyek Rust baru dengan kode yang mirip dengan contoh pertama. Kemudian tambahkan fungsi utama:
let browser = headless_chrome::Browser::default().unwrap();
let tab = browser.new_tab().unwrap();
tab.navigate_to("https://demo.opencart.com/").unwrap();Pemrosesan data menggunakan pemilih CSS juga sedikit berbeda.
let html_products = tab.wait_for_elements("div.col").unwrap();
for html_product in html_products {
let image = html_product
.wait_for_element("image a")
.unwrap()
.get_attributes()
.unwrap()
.unwrap()
.get(1)
.unwrap()
.to_owned();
let url = html_product
.wait_for_element("h4 a")
.unwrap()
.get_attributes()
.unwrap()
.unwrap()
.get(1)
.unwrap()
.to_owned();
let title = html_product
.wait_for_element(".description h4")
.unwrap()
.get_inner_text()
.unwrap();
let description = html_product
.wait_for_element(".description p")
.unwrap()
.get_inner_text()
.unwrap();
let new = html_product
.wait_for_element(".price-new")
.unwrap()
.get_inner_text()
.unwrap();
let tax = html_product
.wait_for_element(".price-tax")
.unwrap()
.get_inner_text()
.unwrap();
let demo_product = DemoProduct {
image: Some(image),
url: Some(url),
title: Some(title),
description: Some(description),
new: Some(new),
tax: Some(tax),
};
demo_products.push(demo_product);
}Segala sesuatu yang lain tetap seperti pada contoh pertama. Namun, metode ini juga membawa beberapa tantangan. Meskipun pendekatan ini memberi Anda kendali menyeluruh atas proses pengikisan, pendekatan ini bisa sangat menyusahkan bagi pemula atau mereka yang membutuhkan solusi cepat dan sederhana. Di sinilah API web scraping khusus seperti Scrape-It.Cloud berperan.
API ini memiliki keuntungan dalam menangani banyak kerumitan untuk Anda, seperti: Seperti merotasi proxy, penanganan CAPTCHA, dan manajemen sesi browser, sehingga Anda dapat lebih fokus pada data yang Anda perlukan daripada seluk-beluk proses scraping.
Jika ini terdengar seperti alternatif yang menarik, mari kita lihat bagaimana Anda dapat menggunakan API ini untuk kebutuhan web scraping Anda.
Pengikisan web di Rust dengan API
Sebelum kita masuk ke kodenya, mari kita bahas sekilas tentang apa itu web scraping API. Pada dasarnya, ini adalah layanan khusus yang dirancang untuk menyederhanakan proses web scraping dengan menangani kompleksitas yang terlibat, seperti: B. menangani CAPTCHA, merotasi proxy, dan mengelola browser tanpa kepala.
Untuk ikhtisar lebih rinci, lihat artikel terpisah kami tentang topik ini.
Sekarang mari kita lihat bagaimana kita dapat mengintegrasikan API tersebut ke dalam proyek Rust kita. Karena API mengembalikan data dalam format JSON, Anda memerlukan pustaka Serde opsional dan modul serde_json-nya. Anda juga dapat menghubungkannya melalui Cargo:
cargo add serde
cargo add serde_jsonAnda kemudian memerlukan kunci API, yang dapat Anda temukan di tab “Dasbor” di akun Anda setelah mendaftar dengan scrape-it.cloud. Mari buat proyek baru dan atur objek klien dan header permintaan di fungsi utama:
let client = Client::builder().build()?;
let mut headers = HeaderMap::new();
headers.insert("x-api-key", HeaderValue::from_static("YOUR-API-KEY"));
headers.insert("Content-Type", HeaderValue::from_static("application/json"));Kemudian kami memanfaatkan kemampuan untuk menambahkan aturan ekstraksi dan menambahkannya ke isi kueri untuk mendapatkan data yang diperlukan sekaligus:
let mut extract_rules = HashMap::new();
extract_rules.insert("Image", "div.image > a > img @src"); // Use space to identify src or href attribute
extract_rules.insert("Title", "h4");
extract_rules.insert("Link", "h4 > a @href");
extract_rules.insert("Description", "p");
extract_rules.insert("Old Price", "span.price-old");
extract_rules.insert("New Price", "span.price-new");
extract_rules.insert("Tax", "span.price-tax");
let extract_rules_json: Value = serde_json::to_value(extract_rules)?;Tetapkan parameter kueri lainnya:
let data = json!({
"extract_rules": extract_rules_json,
"url": "https://demo.opencart.com/"
});Dan buat permintaan POST ke API:
let request = client.post("https://api.scrape-it.cloud/scrape")
.headers(headers)
.body(serde_json::to_string(&data)?);
let response = request.send()?;Sekarang skrip mengembalikan respons dan Anda bisa mendapatkan data yang Anda butuhkan:
let body = response.text()?;Cetak di layar:
println!("{}", body);Atau gunakan contoh sebelumnya dan simpan data ini ke file CSV.
Perayapan web dengan Rust
Contoh kode terakhir dalam artikel ini adalah crawler sederhana yang secara rekursif melintasi halaman situs web dan mengumpulkan semua link. Kami telah menulis tentang perbedaan antara scraper dan crawler, jadi kami tidak akan membandingkannya di sini.
Mari secara eksplisit mengimpor modul yang diperlukan ke dalam file:
use reqwest::blocking::Client;
use select::document::Document;
use select::predicate::Name;
use std::collections::HashSet;Kemudian di fungsi utama kita mengatur parameter awal dan memanggil fungsi perayapan, yang melewati tautan.
fn main() {
let client = Client::new();
let start_url = "https://demo.opencart.com/";
let mut visited_links = HashSet::new();
crawl(&client, start_url, &mut visited_links).unwrap();
}Terakhir, ada fungsi perayapan, yang dengannya kami memeriksa apakah kami telah melintasi tautan saat ini dan jika belum, kami melakukan perayapan.
fn crawl(client: &Client, url: &str, visited_links: &mut HashSet<String>) -> Result<(), reqwest::Error> {
if visited_links.contains(url) {
return Ok(());
}
visited_links.insert(url.to_string());
let res = client.get(url).send()?;
if !res.status().is_success() {
return Ok(());
}
let body = res.text()?;
let document = Document::from(body.as_str());
for link in document.find(Name("a")) {
if let Some(href) = link.attr("href") {
if href.starts_with("http") && href.contains("demo.opencart.com") {
println!("{}", link.text());
println!("{}", href);
println!("---");
crawl(client, href, visited_links)?;
}
}
}
Ok(())
}Hasil:
Ini memungkinkan Anda menelusuri semua halaman situs dan menampilkannya ke konsol atau menggunakan keterampilan yang dipelajari dan menyimpannya dalam format CSV.
Pro dan kontra menggunakan Rust untuk web scraping
Selain banyak kekurangannya, karat juga mempunyai banyak kelebihan. Meskipun terdapat kesulitan dalam mempelajari dan sumber daya yang terbatas untuk mempelajari scraping di Rust, kinerjanya yang tinggi dan kemampuan untuk mengelola proses tingkat rendah menjadikannya penting.
Konkurensi adalah kekuatan lain dari Rust, yang memungkinkan pemrogram menulis program secara bersamaan yang menggunakan sumber daya sistem secara efisien. Selain itu, komunitas Rust memberikan dukungan penting dan peluang kolaborasi. Pengembang dapat dengan bebas berbagi pengetahuan dan belajar dari orang lain melalui berbagai forum, ruang obrolan, dan komunitas online.
Namun, ada beberapa kelemahan yang perlu dipertimbangkan saat bekerja dengan Rust. Khusus untuk otomatisasi browser, meskipun Rust dapat menggunakan alat atau peti eksternal seperti pengikatan Selenium WebDriver untuk bahasa lain (non-pribumi), dukungan langsung dalam ekosistem Rust murni tetap ada dibandingkan dengan beberapa Alternatif yang didukung langsung oleh browser adalah relatif terbatas.
Dalam tabel Anda akan menemukan kelebihan dan kekurangan terpenting Rust:
|
Keuntungan |
Kekurangan |
|---|---|
|
1. Kinerja |
1. Kurva belajar |
|
2. Keamanan penyimpanan |
2. Kematangan ekosistem |
|
3. Paralelisme |
3. Otomatisasi browser yang terbatas |
|
4. Dukungan masyarakat |
4. Dokumentasi dan Sumber Daya |
|
5. Integrasi dengan perpustakaan Rust lainnya |
5. Lebih sedikit alat |
Secara keseluruhan, aspek-aspek ini menunjukkan bagaimana Rust mengatasi kerentanan utama, mengatasi masalah keamanan, dan menawarkan potensi kinerja yang lebih baik, menjadikannya pilihan yang semakin menarik untuk banyak area aplikasi modern.
Tantangan web scraping di Rust
Pengikisan web bisa jadi menantang, terutama saat menggunakan bahasa Rust. Mari kita jelajahi beberapa kesulitan yang dihadapi oleh web scraper di Rust dan diskusikan solusi yang mungkin.
Keterbatasan ekosistem dan ketersediaan perpustakaan
Salah satu tantangan web scraping dengan Rust adalah terbatasnya ketersediaan perpustakaan dan alat yang dirancang khusus untuk scraping. Rust memiliki ekosistem web scraping yang kurang luas dibandingkan bahasa populer lainnya seperti Python atau JavaScript. Akibatnya, pengembang mungkin harus menghabiskan lebih banyak waktu untuk membuat utilitas scraping kustom mereka sendiri atau bekerja dengan perpustakaan yang sudah ada namun kurang komprehensif.
Konten dinamis dan JavaScript
Banyak situs web modern menggunakan konten dinamis yang dihasilkan dengan menjalankan JavaScript di sisi klien. Konten dinamis ini menghadirkan rintangan lain dalam web scraping karena memerlukan lebih dari sekadar penguraian HTML tradisional untuk mengekstrak semua informasi yang diinginkan secara akurat.
Untuk mengatasi keterbatasan ini, salah satu solusinya adalah memanfaatkan browser tanpa kepala dengan pengikatan WebDriver seperti Headless_Chrome. Alat ini memungkinkan interaksi tertulis dengan situs web seolah-olah Anda sedang mengontrol browser sebenarnya, memungkinkan pengambilan konten dinamis secara efektif.
CAPTCHA, pembatasan akses dan pemblokiran IP
Kami telah menulis tentang kesulitan-kesulitan ini dan cara menghindarinya di artikel lain, jadi kami ingin menyampaikannya secara singkat di sini. Untuk melindungi datanya dan mencegah pengikisan, situs web menggunakan tindakan seperti CAPTCHA, pembatasan akses berdasarkan agen pengguna atau alamat IP, atau bahkan memblokir sementara aktivitas mencurigakan. Mengatasi kendala ini bisa jadi sulit saat melakukan web scraping dengan Rust.
Ada beberapa strategi untuk memitigasi tantangan ini, seperti: B. merotasi alamat IP menggunakan server proxy atau menggunakan perpustakaan yang membantu melewati CAPTCHA. Dengan memahami dan mengatasi tantangan ini secara langsung, pengembang dapat memanfaatkan kekuatan jaminan keamanan Rust sambil membangun web scraper yang efektif dan efisien.
Kesimpulan dan temuan
Meskipun web scraping dengan Rust mungkin menghadirkan beberapa tantangan karena terbatasnya ekosistem bahasa untuk kasus penggunaan khusus ini, tantangan ini masih dapat diatasi dengan menjelajahi perpustakaan yang tersedia dan menerapkan teknik yang sesuai seperti pemrograman asinkron atau memanfaatkan browser tanpa kepala untuk mengatasinya. Dengan memahami rintangan yang ada dan menerapkan solusi yang tepat, pengembang dapat menyelesaikan tugas web scraping di Rust dengan sukses dan efisien.
